Зрение для получения прав, с каким зрением допускается вождение автомобиля
Обучение вождению и получение водительских правВсе статьи
Все статьи Экзамен Получение документов Международные права Обучение Общие сведения
Общие сведения37076
Водитель должен реагировать на изменение ситуации на дороге в течение одной секунды. Оперативную реакцию обеспечивает хорошее зрение. Если с ним есть проблемы, тогда водитель должен использовать корректирующие средства — очки или контактные линзы. Они регулируют остроту зрения, но не всегда обеспечивают успешное прохождение медосмотра.
Какие ограничения по зрению могут помешать получить водительское удостоверение, а какие не являются помехой для управления автомобилем, расскажем в этом материале.
С каким зрением можно водить машину
Мы уже рассказывали, что положительное заключение от офтальмолога обязательно для получения ВУ. Врач проверяет остроту зрения и здоровье глаз.
Человек с не очень хорошим зрением может получить водительские права. Офтальмолог смотрит, как он видит в линзах или очках.
Если водитель с нарушениями зрения не проходит проверку в своих очках, специалист назначает ему более сильную оптику для вождения.
Безопасная для управления автомобилем острота зрения — 0,6 единиц на одном глазу и 0,2 единицы на другом.
Также читайте: Как пройти медкомиссию при получении водительских прав
Дальтонизм
Цветовосприятие водителя — важный фактор, влияющий на решение медкомиссии о допуске его к вождению. Раньше с диагнозом дальтонизм водительское удостоверение выдавали, однако позднее этот фактор стал ограничением, с которым нельзя получать права. На дальтонизм проверяют по таблице Рабкина:
Нераспознавание цветов на таблице означает, что человек болен дальтонизмом. При таком диагнозе водительское удостоверение не выдается. Считается, что водитель с дальтонизмом может неправильно отреагировать на сигналы светофора.
Узкий кругозор
Сужение кругозора — это невозможность охватывать взглядом по меньшей мере двадцать градусов. Этот диагноз зачастую возникает при катаракте и глаукоме. Выявление такой проблемы является поводом к отказу в выдаче водительского удостоверения. Если кругозор остается нормальным, тогда такие заболевания не помешают получить права.
Также читайте: Где и как получить водительское удостоверение
С какими еще ограничениями нельзя садиться за руль
К прочим ограничениям, с которыми водительские права не выдают, можно отнести патологии:
- слезного мешка;
- зрительного нерва;
- изменения слизистых;
- изменения мышц века;
- диплопия
Если вы задумываетесь о получении прав, выделите время и пройдите обследование у хороших врачей. Проблемы со здоровьем в большинстве случаев можно решить. Займитесь этим заранее, чтобы патологии не помешали вам получить водительское удостоверение. Также начните как можно раньше отрабатывать свои навыки за рулем.
В качестве первого автомобиля лучше приобрести подержанный автомобиль. Как купить б/у машину и чего стоит опасаться, вы узнаете из статей, размещенных в разделе «Покупка подержанного автомобиля». Обзоры на подержанные автомобили разных годов выпуска читайте в нашем блоге. А когда определитесь с моделью, проверьте историю автомобиля на наличие штрафов, ДТП, лизинга, залога и других проблем.
Если вы профессиональный продавец авто, воспользуйтесь сервисом безлимитных проверок авто «Автокод Профи». «Автокод Профи» позволяет оперативно проверять большое количество машин, добавлять комментарии к отчетам, создавать свои списки ликвидных ТС, быстро сравнивать варианты и хранить данные об автомобилях в упорядоченном виде.
Также читайте: Противопоказания к вождению автомобиля
Оцените материал:
Категории водительских прав с расшифровкой
Категория и подкатегория дает возможность водителю управлять тем или иным транспортным средством.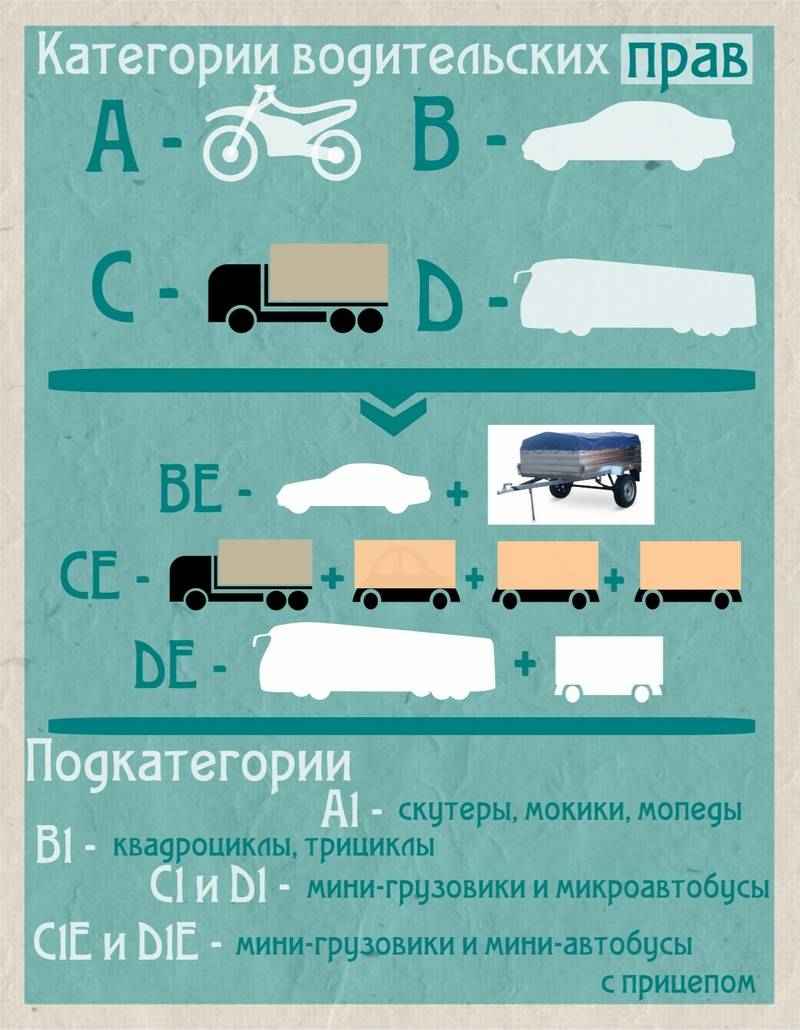 На сегодняшний день их насчитывается шестнадцать и каждую можно классифицировать в соответствии с предназначением:
На сегодняшний день их насчитывается шестнадцать и каждую можно классифицировать в соответствии с предназначением:
Мототранспорт;
Маловесное транспортное средство;
Тяжеловесное ТС;
Транспорт с прицепом;
ТС для перевозки пассажиров.
Категории автомобилей по ПДД 2021 года
Беря в руки водительское удостоверение, мы знаем, что будет открыта категория, на которую было пройдено обучения, но с удивлением обнаруживаем еще как минимум одну дополнительную подкатегорию, и не всегда знаем, что она обозначает.
Чтобы не было сомнений, ниже представлена расшифровка категорий и подкатегорий ТС в водительском удостоверении.
| Категория и подкатегория | Тип транспорта |
|---|---|
| А | Мотоциклы |
| A1 | Легкие мотоциклы с мощностью двигателя от 50 до 125 куб.см и максимальной мощностью до 11кВт |
| B | Автомобили с максимальным весом, не превышающим 3,5 тонны и числом мест, помимо сиденья водителя, не превышает восьми. |
| B1 | Трициклы и квадрициклы |
| BE | Автомобили категории В с прицепом, масса которого составляет более 750 килограммов. |
| C | Автомобили с массой свыше 3,5 тонны, в том числе с прицепом до 750 кг |
| C1 | Автомобили с максимальным весом от 3,5 тонн до 7,5 тонн |
| CE | Автомобили категории С с прицепом, масса которого составляет от 750 кг до 3,5 тонн |
| С1Е | Автомобили категории С1 с массой свыше 3,5 тонн, но не превышает 7.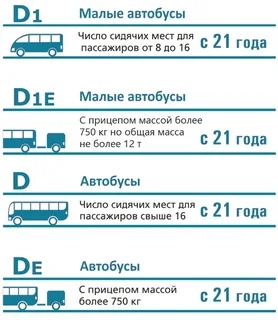 5 тонн сцепленных с прицепом, масса которого превышает 750 кг, при общей сумме не более 12 тонн 5 тонн сцепленных с прицепом, масса которого превышает 750 кг, при общей сумме не более 12 тонн |
| D | Автомобили для перевозки пассажиров, которые имеют более 8 сидячих мест, помимо места водителя, в том числе с прицепом массой до 750 кг. |
| D1 | Автомобили с количеством мест 8-16, помимо места водителя |
| DE | Автомобили категории D с прицепом массой от 750 кг до 3,5 тонн |
| D1E | Автомобили категории DE с прицепом, масса которого не менее 750 кг, но не более 12 тонн |
| M | Мопеды, скутеры и квадроциклы объемом до 50 куб.см |
| Tm | Трамваи |
| Tb | Троллейбусы |
Данное описание категорий в правах водителя в России актуально на сегодняшний день.
Не стоит забывать, что автомобильные права одни для всех категорий, то есть открывая новую категорию, у вас будет одно удостоверение с проставленными отметками для управления разрешенным ТС.
Важно!
Чтобы легче запомнить обозначение категорий транспорта в ВУ, нужно выделить 5 главных категорий : А — мотоциклы, В — легковые, С — грузовые, D — автобусы, М — мопеды. A1, B1, C1, D1 — подкатегории, а BE, CE, DE, C1E, D1E — управление с прицепом.
Не многие участники дорожного движения знают, что для управления транспортным средством нужно открыть соответствующую категорию вождения. Например, если у вас открыта “В”, то вам нельзя управлять грузовым автомобилем или автобусом, но граждане порой пренебрегают этим правилом. За подобное нарушение полагаются существенные штрафы. Классификация ТС по категориям не зря придумана, ведь управлять грузовиком сложнее, чем легковым авто. Не зная габариты и особенности управления, можно спровоцировать ДТП.
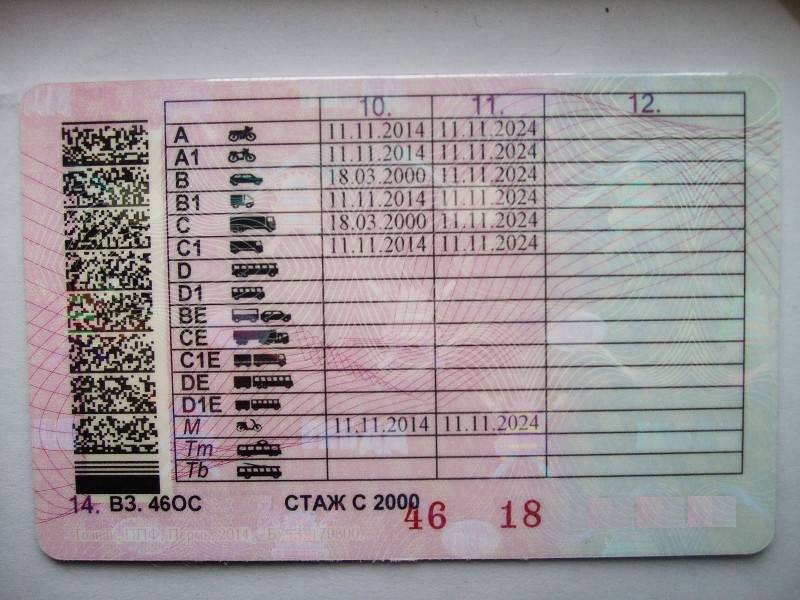
Что означает пункт 12 в водительском удостоверении
Существуют различные обозначения на водительском удостоверении, которые что-то разрешают или запрещают.
Существует еще один тип отметки, это “MS”. Она позволяет управлять двухколесным ТС с мотоциклетным типом руля и соответствующей посадкой. Ставят ее, если открыта категория “А” или “А1”. Если водителю доступны обе категории,то отметка не ставится.
Также возможна отметка “АТ” — автоматическая трансмиссия, и “ML” — при наличии медицинских ограничений к категории М.
В этой статье мы рассматривали вопрос отметок в водительском удостоверении более детально.
Вопрос-ответ
Зачем нужен 14 пункт в правах?
Пункт 14 в водительском удостоверении означает еще одно место для специальных отметок. Там может быть указан стаж вождения или отметка, что управление ТС без линз невозможно.
Там может быть указан стаж вождения или отметка, что управление ТС без линз невозможно.
Какая расшифровка В/У?
Водительское удостоверение.
Какие есть категории автотранспорта?
Существует 5 главных категорий : А — мотоциклы, В — легковые, С — грузовые, D — автобусы, М — мопеды. A1, B1, C1, D1 — подкатегории, а BE, CE, DE, C1E, D1E — управление с прицепом.
Какая категория вод. прав на машину для перевозки грузов?
Материалы текущего раздела
Дата обновления: 20 октября 2020 г.
Категории водительских прав | Новые категории водительских прав
В соответствии со статьей 2.1.1 ПДД Российской Федерации, в 2021 году человек, который управляет автомобильным транспортом, обязан иметь документы, удостоверяющие личность, и бумаги, подтверждающие право управления автомобилем соответствующей категории или подкатегории. Все категории водительских прав обладают своими уникальными параметрами. Теория вождения все время обновляется, поэтому сегодня поговорим о нововведениях следующего года.
Какие будут категории прав в 2021 году
Категория, указанная в удостоверении – это указание на тип транспортного средства, которым может управлять человек. С каждым годом появляются новые категории водительских прав.
В 2021 году утверждено пять основных групп:
- А – мототранспорт;
- В – легковые автомобили;
- С – грузовые авто;
- D – автомобильный транспорт для перевозки пассажиров;
- М – мопеды и прочие транспортные средства, имеющие небольшую мощность.


Расшифровка категорий водительских прав
Каждая категория и подкатегория имеет свои индивидуальные требования к автомобильному транспорту. Расшифровка категорий водительского удостоверения приведена ниже.
A
Транспортное удостоверение категории А разрешает управлять следующим мототранспортом:
- мотоколяски;
- мотоциклы;
- мотоциклы с мотоприцепами.
Под определение мотоцикла подходит двухколесный транспорт, имеющий объём двигателя от 50 кубических сантиметров и максимальную скорость более пятидесяти км/ч. Допускается наличие боковой коляски. Ещё к мотоциклам относятся трёхколесные и четырехколесные средства передвижения, масса которых не превышает 0,4 т. без учета аккумулятора.
A1
Литер А1 разрешает управлять только мотоциклами. Эти удостоверения выдаются для управления скутером или квадроциклом. Транспорт должен соответствовать следующим характеристикам:
- мощность до одиннадцати киловатт;
- объём двигателя от 50 до 125 кубов;
- отсутствие мотоприцепа.
B
В категорию В входит легковой автотранспорт. Он должен соответствовать следующим требованиям:
- масса не более трех с половиной тонн;
- девять сидячих мест вместе с креслом водителя;
- возможно наличие груза до 0,75 т.;
- прицеп может иметь больший вес, но тогда он должен быть меньше авто.
BE
К этой группе относится легковой автомобильный транспорт с тяжелым грузом. В 2021 году гражданин имеет право управлять машиной с прицепом, подходящим под эти характеристики:
- вес более 0,75 т.;
- общая масса больше 3,5 т.;
- масса груза больше массы автомобиля без нагрузки.
Для получения ВЕ требуется сдача дополнительного экзамена, так как удостоверение относится к отдельной группе.
B1
Это подкатегория, которая появилась сравнительно недавно. В официальных документах практически нет четкой информации о том, что подходит под определение этого авто. В статье 25 ФЗ№196 указано, что сюда относятся трициклы и квадроциклы.
C
В категорию С включены грузовые машины разнообразной вместимости:
- массой от трех с половиной тонн;
- машины с прицепом меньше 0,75 т.
Литера С включает в себя весь автомобильный транспорт, применяющейся для грузоперевозок.
CE
Категория СЕ включает в себя автотранспорт с прицепом более 0,75 т. Т/С обязывает иметь определенные навыки управления, потому что сложно совершать маневры на таком тяжелом автомобиле. Существует запрет на движение по некоторым трассам.
C1
В С1 входят облегченные транспортные средства для грузоперевозок. Параметры для этих автомобилей:
- масса от трех с половиной до семи с половиной тонн;
- автомобиль с грузом до 0,75 т.
Когда гражданин получает права категории С, то С1 ставится автоматом. В 2021 году появляется возможность сдать на подкатегорию С1 отдельно.
C1E
Сюда относятся машины с прицепом, к которому имеются чёткие требования. Это более лёгкий вариант СЕ, ведь здесь масса прицепа может быть больше 0,75 т, но только при соблюдении следующих условий:
- общий вес менее двенадцати тонн;
- вес груза не должен превышать массу основного автомобиля без нагрузки.
Подкатегория получается при сдаче на СЕ, но существует возможность сдать на нее отдельно.
D
D – это автомобильный транспорт, предназначенный для перевозки пассажиров. Основной упор прав – число сидячих мест. Здесь присутствуют определенные требования по массе.
Трамваи и троллейбусы не входят в эти водительские категории.
DE
Буква Е обычно говорит о наличии прицепа, но на дорогах крайне редко встречаются пассажирские автобусы с прицепом для грузов. В основном к этой подкатегории относятся сочлененные автобусы.
D1
В эту подкатегорию включены маршрутки, в которых находится от 9 до 17 мест вместе с водительским сидением. Этот автомобильный транспорт может иметь прицеп для перевозки грузов, весом в 0,75 т.
D1E
К этой подкатегории имеют отношения различные пассажирские транспортные средства, которые обладают следующими параметрами:
- от девяти до семнадцати сидячих мест, включая место водителя;
- общий вес автомобиля с грузом не должен превышать двенадцать тонн;
- имеется специальный прицеп для перевозки различных грузов менее 0,75 тонн.
M
Эта группа появилась с недавних пор и разработана для регулирования езды на мопедах. В 2021 году сюда входят легкие квадроциклы.
Мопед – это вид двухколесного или трехколесного транспортного средства, соответствующего следующим параметрам:
- максимальная скорость – не более пятидесяти километров в час;
- объем двигателя – до пятидесяти сантиметров в кубе;
- мощность до четырёх киловатт.
Удостоверение с пометкой М получается при сдаче на права на абсолютно любой другой вид прав. Стоит заметить, что помимо мопедов сюда включены электрические велосипеды и остальные средства передвижения.
Tm
В эту категорию входят трамваи. Можно управлять как одинарными, так и сочлененными моделями.
Tb
Сюда относятся троллейбусы. Как и Tm можно использовать права для управления сочлененными и одинарными транспортными средствами.
В статье были рассмотрены требования ко всем категориям водительских прав. Важно, чтобы транспортное средство подходило под указанные параметры.
Какие есть категории водительских прав
Категория водительских прав — это разрешение на управление конкретным видом транспортного средства. Для получения каждой из них нужно пройти обучение и успешно сдать отдельные экзамены.
Если раньше с обозначением пунктов удостоверения на право вождения авто было все понятно, то сейчас категории несколько запутаны. Помимо основных, существует целый ряд дополнительных разрешений на управление определенным видом транспорта. Для общего понимания в этой статье мы расскажем о категориях и самых популярных подкатегориях водительских прав в Украине. Плюс к этому познакомим вас с их расшифровкой. Но давайте обо всем по порядку.
Плюс к этому познакомим вас с их расшифровкой. Но давайте обо всем по порядку.
Классификация водительских прав: какие бывают категории
Ранее на водительском удостоверении можно было увидеть только 5 основных категорий. Сейчас они также присутствуют, но при этом получили ряд подкатегорий. Всего современные права водителя насчитывают 16 пунктов. Их классификация базируется на общепринятой системе о дорожном движении в Украине.
В начале рассмотрим 5 основных групп транспортных средств и их значение:- Мотоциклы и мотороллеры (А) Можно водить любой двухколесный транспорт (в том числе с боковым прицепом), в котором объем двигателя не менее 50 куб. см, или электромотором мощностью более 4 кВт.
- Легковые автомобили и другой транспорт на их базе (В) Это самая распространенная среди водителей категория, которая даёт право управлять любым транспортом с массой до 3,5 тонны и общим числом сидений в салоне не более 8.
- Грузовые автомобили (С) Тут все предельно просто – можно управлять особенно крупными грузовыми авто, общая масса которых больше 7,5 тонны.
- Автобусы (D) Нужна для управления крупным пассажирским транспортным средством, в салоне которого установлено больше 16 сидений (с учетом места для водителя).
- Трамваи и троллейбусы (Т) Как видно из названия, дают право управлять трамваем и троллейбусом.
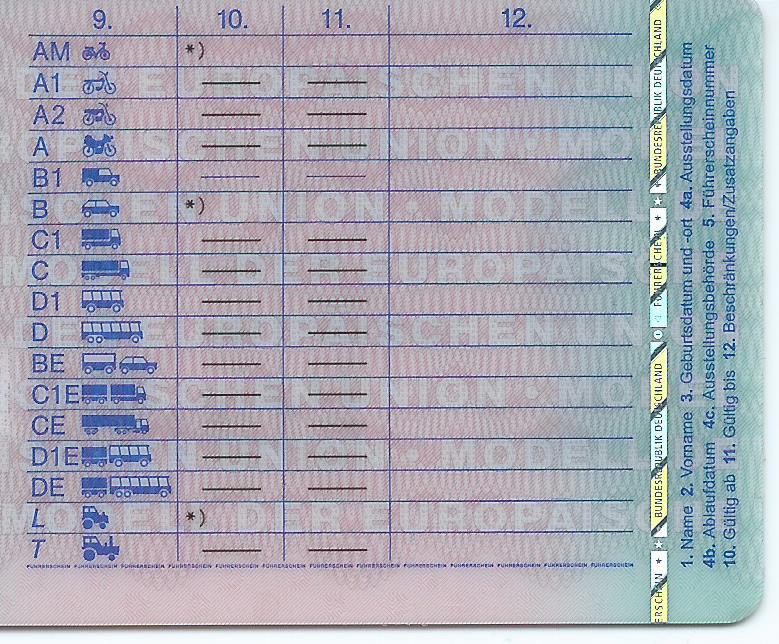
Что означают подкатегории на водительском удостоверении
Также в Украине существует ряд подкатегорий, имеющих своё индивидуальное обозначение и характеристики. Те, что с цифрой, обозначают облегченную (упрощенную) версию транспортного средства, указанного в основном разделе. Характеристика категорий с индексом Е дает разрешение на буксировку автомобилем тяжелого прицепа.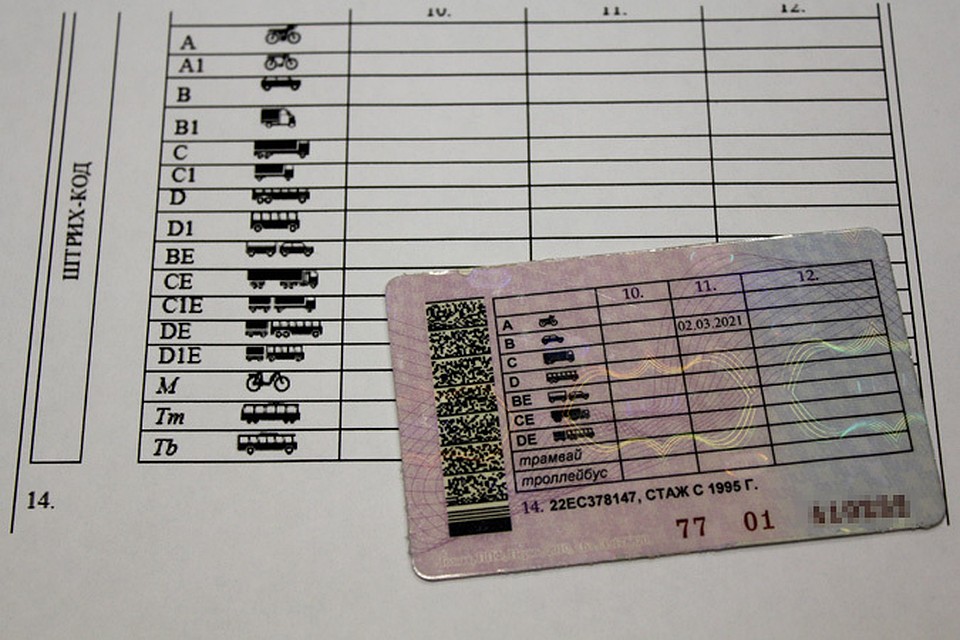 Давайте рассмотрим каждый пункт более детально:
Давайте рассмотрим каждый пункт более детально:
- А1 – двухколесный или трехколесный транспорт, с объемом двигателя меньше 50 куб. см. К этой подкатегории также относятся модели с электродвигателем до 4 кВт.
- В1 – малогабаритные транспортные средства, общая масса которых составляет до 400 кг. К ним относятся квадроциклы, трициклы и др.
- С1 – грузовики с разрешенной массой в диапазоне от 3,5 до 7,5 тонн.
- D1 – миниатюрные версии полноценных пассажирских автобусов. Выдается для управления транспортом с 16 местами в салоне и менее.
- В, С и D с индексом Е – управление тягачом (соответствующим основной категории), а также транспортом с прицепом (масса свыше 750 кг).
На заметку – если масса прицепа менее 750 кг, удостоверения с индексом Е не требуется. Это все описания категорий транспортных средств, которое нужно помнить водителю.
Что еще важно знать
С появлением дополнительной классификации водительских прав в Украине, существенно изменились условия для их получения. Если говорить прямо – они стали сложнее. И речь идет не только о получении первой водительской корочки. Многие водители отметили, что сдать на права даже на более низкую категорию стало значительно труднее.
Если говорить прямо – они стали сложнее. И речь идет не только о получении первой водительской корочки. Многие водители отметили, что сдать на права даже на более низкую категорию стало значительно труднее.
Помимо усложненных экзаменов, существуют и ограничения по возрасту. Например:
- водить мотоциклы (А) можно с 16 лет,
- четырехколесный легковой и грузовой транспорт (В и С) – с 18 лет,
- прицепы и тягачи (с индексом Е) – с 19 лет,
- автобусы и троллейбусы (D и Т) только при достижении 21 года.
Категории водительских прав в Украине
КАТЕГОРИИ ВОДИТЕЛЬСКИХ ПРАВ В УКРАИНЕ
Сегодня уже трудно представить жизнь современного человека без автомобиля. Машина с нами повсюду: помогает быстро приехать на работу, и вернутся домой, отвезти детей в школу либо садик, проехаться по магазинам за покупками и так далее. Да что там говорить, ездить на автомобиле это большое удовольствие, которое становится неотъемлемой частью жизни человека.
Выбирая непосредственно сам процесс обучения вождению автомобиля, люди задумываются, а какие категории водительских прав есть в Украине на 2015 год, что означают все эти символы на обратной стороне заветного водительского удостоверения и какова расшифровка категорий водительских прав в Украине. Давайте попробуем разобраться с таким важным и интересным вопросом.
Расшифровка категорий водительских прав в Украине на 2015 год
А1 — эта категория, открытая в ваших правах, позволит Вам ездить на таких транспортных средствах, как мопеды. Если обратится к Правилам движения, то мопеды – это двухколесный транспорт, с рабочим объемом двигателя не более 50 сантиметров кубических
А – расшифровка водительских прав такой категории говорит, что с нею вам разрешено управлять такими типами транспортных средств, как мотоцикл (с рабочим объемом более 50 сантиметров кубических), также присутствует уточнение, что мотоциклы могут быть только двухколесными, то есть без коляски, для следующих предусмотрена отдельная категория водительских прав.
В1 – новая категория водительских прав в Украине на 2015 год, расшифровка такой категории подразумевает под собою трех и четырехколесные средства для передвижения с полной массой до 400 килограмм. Это мотоциклы с колясками и квадроциклы.
В – самая удобная и удачная категория водительских прав в Украине, разрешает водить легковые машины и их модификации с полной массой до 3,5 тонн и количеством мест для сиденья 8+1, плюс один означает плюс водитель. Также можно прицепить и буксировать легковой прицеп, который вместе с грузом весит не более 750 килограмм.
С1 – одна из новых категорий в расшифровке водительских прав в Украине на 2015 год. Это грузовые автомобили с полной массой 3,5-7,5 тонн, без прицепа. В таком автомобиле также может быть до 8 пассажирских мест плюс место водителя.
С – все те же условия, что и категория С1, только полная масса такого автомобиля уже может быть более 7, 5 тонн.
D1 – расшифровуетсякак автомобили с количеством мест для сидения от 8 до 16 плюс место водителя. Согласно все тем же Правилам такой транспорт определяется как микроавтобусы. Разрешается также буксировать прицеп до 750 килограмм полной массы.
Согласно все тем же Правилам такой транспорт определяется как микроавтобусы. Разрешается также буксировать прицеп до 750 килограмм полной массы.
D – разрешает управлять автобусами, с количеством пассажирских мест более восьми плюс место водителя.
Е – дополнительная категория водительских прав в Украине, которая может комбинироваться с остальными, представляет возможность для буксировки любого типа прицепов полной массой более 750 килограмм.
В завершении хотелось бы также отметить, что расшифровка категорий водительских прав в Украине позволяет получать их в случае с мопедами и мотоциклами с 16 лет, с автомобилями с 18 лет, с автобусами с 21 года. Ну а для получения категории Е вам должно быть не менее 19.
ОФОРМЛЕНИЕ ВОДИТЕЛЬСКОГО УДОСТОВЕРЕНИЯ ПРИ ЕГО ВЫДАЧЕ / КонсультантПлюс
Приложение N 3
к Приказу МВД России
от 13.05.2009 N 365
Оформление водительского удостоверения (далее — удостоверение) производится с использованием автоматизированных рабочих мест.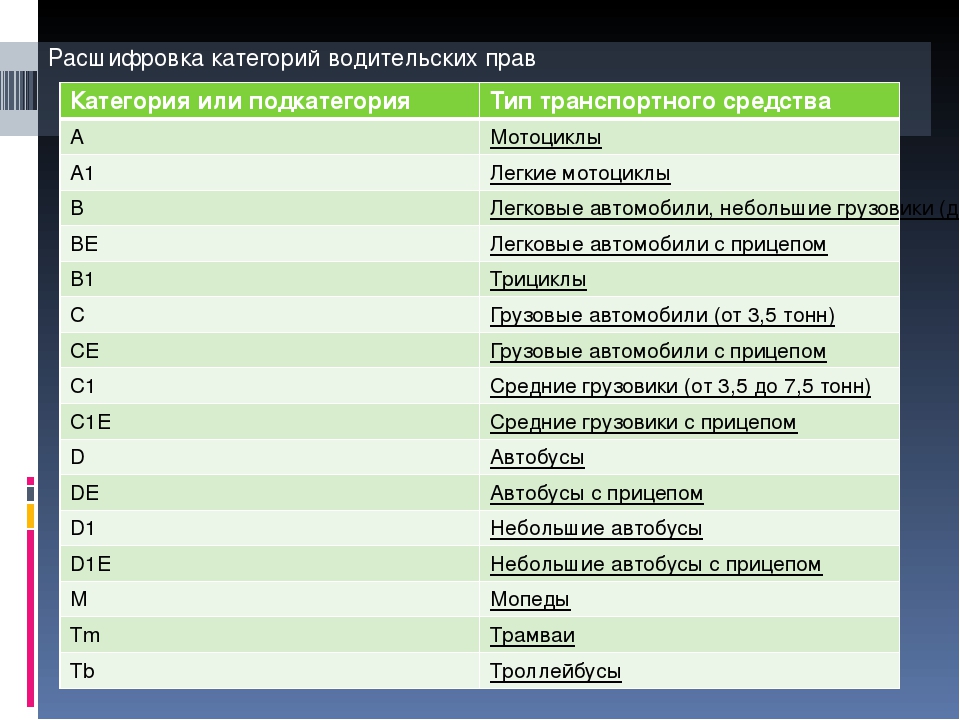
Нумерация разделов удостоверения печатается сиреневым цветом, остальная вводимая информация, в том числе таблица категорий, подкатегорий на оборотной стороне, — черным цветом.
(см. текст в предыдущей редакции
)
Цветная фотография владельца выполняется в процессе оформления удостоверения цифровым способом на сером фоне и печатается в специально отведенном месте удостоверения.
Фотография должна иметь четкое изображение лица строго в анфас без головного убора. Допускается изготовление фотографий в головных уборах, не скрывающих овал лица, гражданам, религиозные убеждения которых не позволяют показываться перед посторонними лицами без головных уборов.
Для граждан, постоянно носящих очки, допускается фотографирование в очках без тонированных стекол.
Все записи в водительском удостоверении выполняются на русском языке и дублируются способом транслитерации (простого замещения русских букв на латинские), учитывая рекомендованный ИКАО международный стандарт (приложение к настоящему Оформлению водительского удостоверения при его выдаче — справочно).
(см. текст в предыдущей редакции
)
———————————
Сноска исключена. — Приказ МВД России от 20.10.2015 N 995.(см. текст в предыдущей редакции
)
По желанию владельца записи в удостоверении могут транслитерироваться в соответствии с данными, указанными в его заграничном паспорте.
Транслитерация текстовой информации выполняется в специально отведенных полях, расположенных под соответствующими разделами удостоверения. Шрифт транслитерируемой текстовой информации должен отличаться от шрифта, которым выполняются записи на русском языке.
Сведения в разделах 1, 2 и 3 указываются на основании паспорта гражданина или иного документа, удостоверяющего личность в соответствии с законодательством Российской Федерации. При этом в разделе 3 указывается наиболее крупная административно-территориальная единица соответствующей графы «Место рождения».При написании названий субъектов Российской Федерации в разделах 3, 4c) и 8 применяются следующие сокращения: республика — респ. , край — кр., область — обл., автономная область — авт. обл., автономный округ — авт. окр., г. Санкт-Петербург — г. С.-Петербург.Даты в разделах 3, 4a), 4b), 10 и 11 указываются арабскими цифрами в следующем формате: число, месяц, год (чч.мм.гггг).В разделе 4c) указывается аббревиатура «ГИБДД» и через один пробел — четырехзначный код подразделения Госавтоинспекции в формате: «0011», где:
, край — кр., область — обл., автономная область — авт. обл., автономный округ — авт. окр., г. Санкт-Петербург — г. С.-Петербург.Даты в разделах 3, 4a), 4b), 10 и 11 указываются арабскими цифрами в следующем формате: число, месяц, год (чч.мм.гггг).В разделе 4c) указывается аббревиатура «ГИБДД» и через один пробел — четырехзначный код подразделения Госавтоинспекции в формате: «0011», где:«00» — цифровой код региона Российской Федерации, применяемый на государственных регистрационных знаках транспортных средств и другой специальной продукции, необходимой для допуска транспортных средств и их водителей к участию в дорожном движении <*>;
———————————
Постановление Правительства Российской Федерации от 8 апреля 1992 г. N 228 «О некоторых вопросах, связанных с эксплуатацией автомототранспорта в Российской Федерации» (Собрание актов Президента и Правительства Российской Федерации, 1993, N 15, ст. 1249; Собрание законодательства Российской Федерации, 1995, N 48, ст.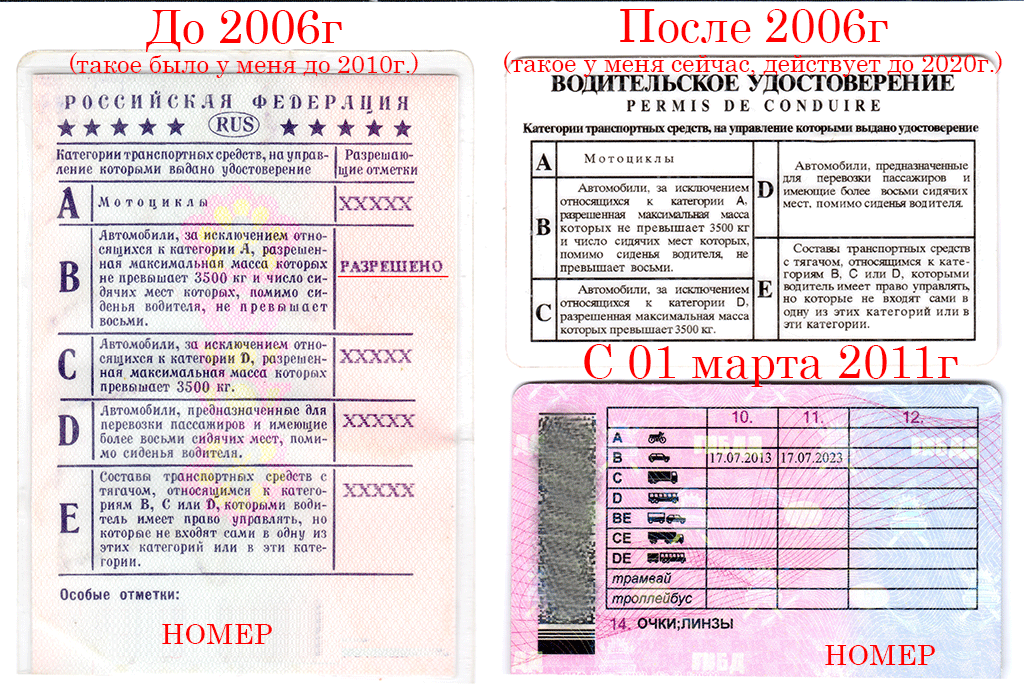 4681; 1998, N 32, ст. 3910, ст. 3916; 1999, N 31, ст. 4025; 2002, N 20, ст. 1859; 2007, N 6, ст. 760).
4681; 1998, N 32, ст. 3910, ст. 3916; 1999, N 31, ст. 4025; 2002, N 20, ст. 1859; 2007, N 6, ст. 760).
«11» — цифровой код экзаменационного подразделения, утверждаемый главным государственным инспектором безопасности дорожного движения по субъекту Российской Федерации, а также главным государственным инспектором безопасности дорожного движения Российской Федерации.
Например: «ГИБДД 0215».
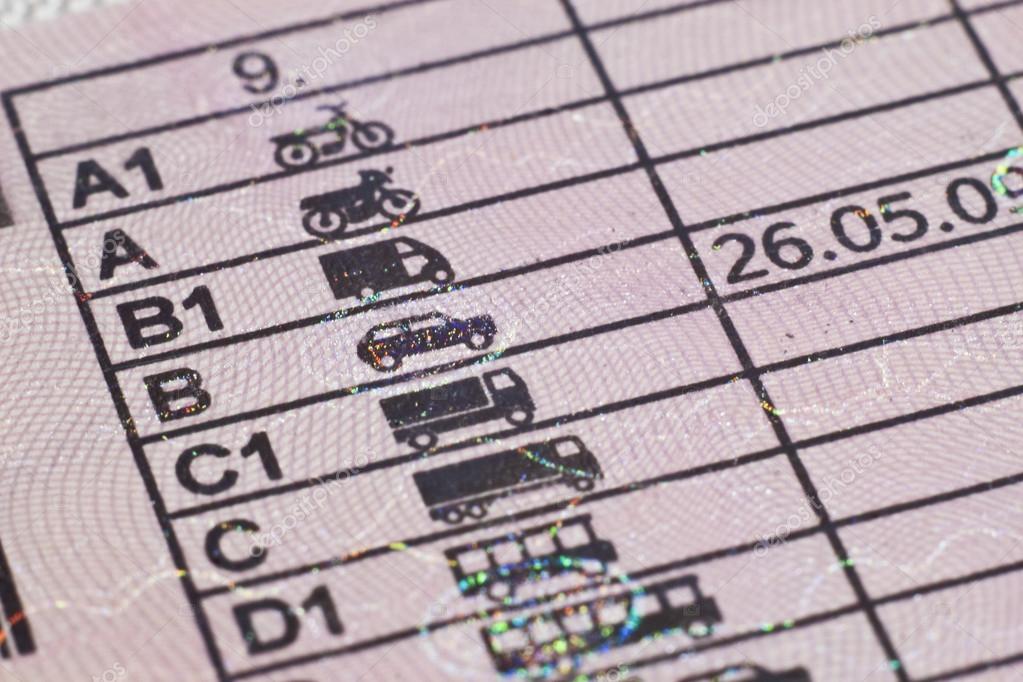
В разделе 5 указываются серия и номер удостоверения, которые должны соответствовать серии и номеру на оборотной стороне удостоверения.В разделе 7 специальными чернилами или пастой черного цвета проставляется личная подпись владельца удостоверения либо печатается изображение подписи владельца.В разделе 8 указывается субъект Российской Федерации, в котором владелец удостоверения зарегистрирован по месту жительства, а при отсутствии такой регистрации — по месту пребывания. Для лиц, не зарегистрированных по месту жительства и по месту пребывания, указывается субъект Российской Федерации, в котором владелец удостоверения фактически проживает. Для лиц, временно пребывающих или временно проживающих на территории Российской Федерации, указывается страна места жительства.В разделе 9 указываются разрешенные категории и подкатегории транспортных средств, на которые распространяется действие удостоверения. Указанные категории и подкатегории печатаются в отдельных рамках, которые располагаются в одну строку с соблюдением следующей последовательности: A, A1, B, B1, C, C1, D, D1, BE, CE, C1E, DE, D1E, M, Tm, Tb.(см. текст в предыдущей редакции
)
Категории «M», «Tm» и «Tb» обозначаются шрифтом Arial с курсивом.
(см. текст в предыдущей редакции
)
(см. текст в предыдущей редакции
)
(см. текст в предыдущей редакции
)
(см. текст в предыдущей редакции
)
(см. текст в предыдущей редакции
)
(см. текст в предыдущей редакции
)
(см. текст в предыдущей редакции
)
———————————
Сноска исключена. — Приказ МВД России от 20. 10.2015 N 995.
10.2015 N 995.(см. текст в предыдущей редакции
)
При наличии в водительском удостоверении категории «B» и отсутствии категории «A» в разделе 12 для подкатегории «B1» проставляется отметка «AS», подтверждающая наличие ограничений к управлению транспортными средствами подкатегории «B1» с мотоциклетной посадкой или рулем мотоциклетного типа.
(см. текст в предыдущей редакции
)
(см. текст в предыдущей редакции
)
 10.2015 N 995)В разделе 14 указываются общие ограничения в действии удостоверения в отношении всех категорий и подкатегорий транспортных средств , информация о стаже управления транспортными средствами (указывается год наиболее ранней даты получения права на управление транспортными средствами), а также информация, касающаяся владельца удостоверения.(абзац введен Приказом МВД России от 20.10.2015 N 995)
10.2015 N 995)В разделе 14 указываются общие ограничения в действии удостоверения в отношении всех категорий и подкатегорий транспортных средств , информация о стаже управления транспортными средствами (указывается год наиболее ранней даты получения права на управление транспортными средствами), а также информация, касающаяся владельца удостоверения.(абзац введен Приказом МВД России от 20.10.2015 N 995)———————————
Постановление Правительства Российской Федерации от 29 декабря 2014 г. N 1604 «О перечнях медицинских противопоказаний, медицинских показаний и медицинских ограничений к управлению транспортным средством» (Собрание законодательства Российской Федерации, 2015, N 2, ст. 506).(сноска введена Приказом МВД России от 20.10.2015 N 995)Общие ограничения в действии водительского удостоверения в отношении всех категорий и подкатегорий транспортных средств, являющиеся медицинскими показаниями к управлению транспортным средством, в разделе 14 указываются в кодированном виде:(абзац введен Приказом МВД России от 20.
 10.2015 N 995)
10.2015 N 995)MC — медицинские показания к управлению транспортным средством с ручным управлением;
(абзац введен Приказом МВД России от 20.10.2015 N 995)AT — медицинские показания к управлению транспортным средством с автоматической трансмиссией;
(абзац введен Приказом МВД России от 20.10.2015 N 995)APS — медицинские показания к управлению транспортным средством, оборудованным акустической парковочной системой;
(абзац введен Приказом МВД России от 20.10.2015 N 995)GCL — медицинские показания к управлению транспортным средством с использованием водителем транспортного средства медицинских изделий для коррекции зрения;
(абзац введен Приказом МВД России от 20.10.2015 N 995)HA/CF — медицинские показания к управлению транспортным средством с использованием водителем транспортного средства медицинских изделий для компенсации потери слуха.
(абзац введен Приказом МВД России от 20.10.2015 N 995)В специально отведенном месте удостоверения наносится штрих-код, содержание которого определяется подразделением Госавтоинспекции на федеральном уровне.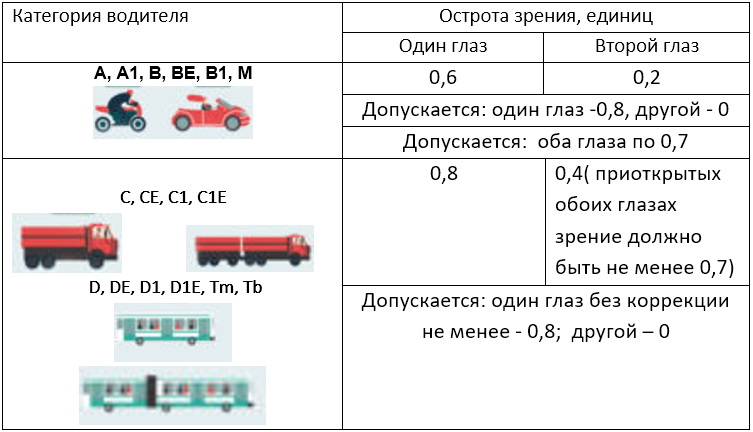
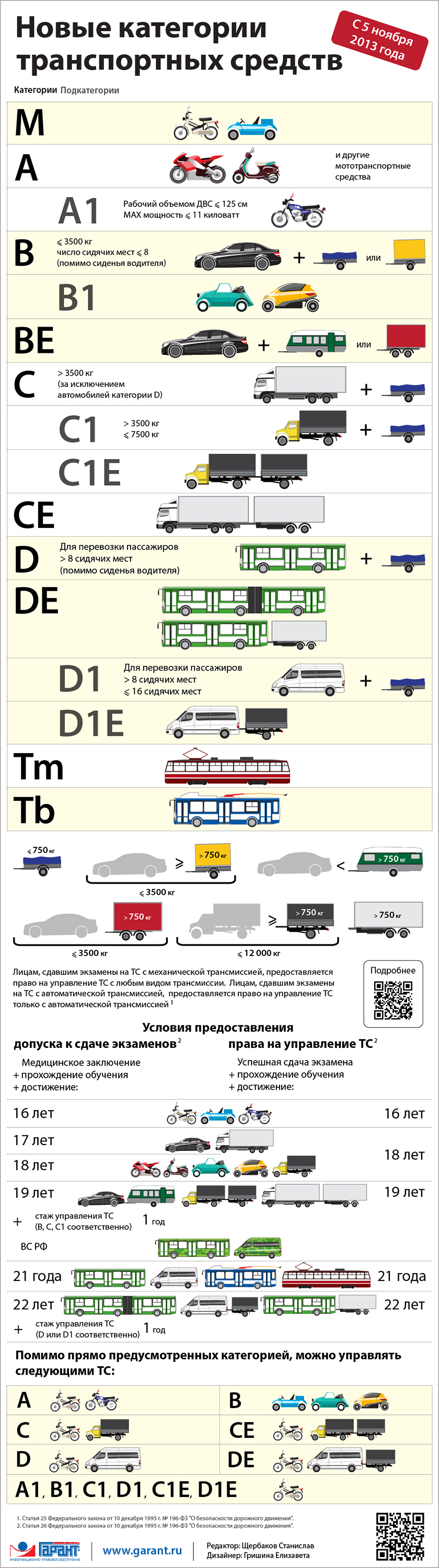
Категории водительских прав в 2020 году
Категория в правах формирует конкретную группу транспортных средств (ТС) право управлять которой имеет владелец водительского удостоверения.
С 5 ноября 2013 года вступили в силу изменения в закон «О безопасности дорожного движения», которые не только изменили перечень категорий водительского удостоверения, но и добавили совершенно новые подкатегории.
Новые категории водительских прав 2019 года — их расшифровка и классификация
Имеющиеся категории классифицируются на 7 основных:
- «A» — мотоциклы;
- «B» — легковые автомобили;
- «C» — грузовые автомобили;
- «D» — автобусы;
- «Tm, Tb» — тролебусы, трамваи;
- «M»— мопеды и скутеры;
- специальные категории «BE», «CE», «DE», «C1E», «D1E» дающие право на управление ТС с прицепом.

И 4 группы подкатегорий: «A1», «B1», «C1», «D1».
Рассмотрим подробнее каждую категорию/подкатегорию водительских прав и выясним их особенности использования для управления конкретным транспортным средством.
Категория «А» — мотоцикл
Категория «А» дает право управлять любым типом мотоциклов, в их числе — оборудованных коляской.
Кроме вышесказанного, категории «A» разрешает управлять мотоколяской (если кто-то еще помнит что это).
Напомним: в соответствии с ПДД, мотоцикл – двухколесное транспортное средство без бокового прицепа либо с ним. Категория «А» разрешает управлять трехколесным либо четырехколесным транспортным средством массой менее 400 килограмм в снаряженном состоянии.
Подкатегория «А1»
К этой подкатегории причисляют мотоцикл с объемом двигателя не более 125 см. куб., а мощностью – не более 11 кВт.
Эта подкатегория, грубо говоря, относится к мотоциклам с небольшим двигателем и невысокой мощностью.
Отметим, что человек с правами в которых категория «А» открыта может законно управлять и ТС по категории «А1».

Категория «M» — мопед / легкий квадрицикл
С 05.11.13 определена новая категория «М» для мопеда и легкого квадрицикла.
Если у человека есть права в принципе с любой открытой категорией – у него есть законное право на управление по категории «М».
Нюанс: удостоверение тракториста-машиниста права на управление обозначенными мопедами не дает.
Категория «В» — легковой автомобиль
Категория «В» в водительском удостоверении разрешает управление легковым авто и небольшими джипами/ микроавтобусами/ грузовиками, отвечающим таким требованиям:
- категория «В» — машина (за исключением ТС по категории «А») массой не более 3,5 тонны, числом мест (сидячих) не более восьми, не включая водительского;
- автомобиль категории «В» в связке с прицепом весом не более 750 кг;
- автомобиль категории «В» в связке с прицепом весом более 750 кг, но массы машины без нагрузки он не превышает, а также с условием того, что масса состава автомобиль плюс прицеп не более 3,5 тонны.

Категория «B», в том числе, разрешает управление мотоколяской, а также еще и машиной с прицепом весом не более 750 кг.
В случае если прицеп весит более 750 кг – к такому составу предъявляют дополнительные требования, а именно:
- Нагруженный прицеп не может весить больше чем машина без нагрузки;
- Разрешенный максимальный вес состава «автомобиль плюс прицеп» не может быть более 3,5 тонн.
Категория «BE» — тяжелый прицеп
Чтобы управлять машиной категории «B» в связке с тяжелым прицепом, человек должен получить категорию «BE»:
- «ВЕ» – авто категории «В» в связке с прицепом весом более 750 кг и который весит более чем сама машина без нагрузки;
- ТС категории «В» в связке с прицепом массой более 750 кг, но с условием того, что вес состава «автомобиль плюс прицеп» не должен превышать 3,5 тонн.
Подкатегория «B1» — трицикл / квадрицикл
На данный момент мы готовим подробный данные для подкатегории «B1». Ждите обновленной информации.
Ждите обновленной информации.
Сразу уточним: «квадрИцикл» и «квадрОцикл» технически разные понятия. В силу этого водительские права для квадроцикла не подходят для управления квадрициклом.
Сразу уточним: «квадрИцикл» и «квадрОцикл» технически разные понятия. В силу этого водительские права для квадроцикла не подходят для управления квадрициклом.
Категория «С» — грузовой автомобиль
Категория «C» нужна водителю для управления грузовиком весом более 3500 кг:
- категория «С» – автомобиль (кроме транспорта из категории «D») весящий более 3,5 тонн;
- машины категории «С» в связке с прицепом весом не более 750 кг.
Человек с правами категории «С» может водить только средние и тяжелые грузовики (3500-7500 кг и более 7500 кг, соответственно), а также грузовую машину с прицепом весом не более 750 кг.
Стоит обратить внимание что категория «C» абсолютно не дает водителю прав на управление небольшим грузовиком (менее 3,5 тонн) и легковой машиной.

Водительские права категории «СE» — с тяжелым прицепом
Категория «CE» пригодится водителю с открытой категорией «С» для управления автомобилем с тяжелым прицепом (больше чем 750 кг).
Подкатегория «С1»
Чтобы иметь право управлять грузовым автомобилем с весом 3,5-7,5 тонны, человек должен иметь права с действующей категорией «C1»:
- подкатегория «С1» — машины (кроме авто категории «D») с массой более 3500 килограммов, но менее 7500 килограммов;
- авто подкатегории «С1» в связке с прицепом который весит не больше чем 750 килограмм;
- к этой подкатегории относятся также и средние грузовики массой в пределах 3500-7500 кг
- подкатегория разрешает управлять связкой с легким прицепом весом до 750 кг.
Открытая категория «С» разрешает управлять машинами и по категории «С1».
Подкатегория «С1E» — тяжелый прицеп
Дополняющая подкатегория «C1E» характеризует автомобили категории «С1», однако уже весящими более 750 кг (тяжелыми прицепами). Согласно ПДД, в таком случае общий вес всего состава не должен быть более 12 тонн.
Водители со старшей подкатегорий «CE» имеют право управлять грузовиками, относящимся к категории «C1E».
Категория «D» — автобус
Чтобы иметь право управлять автобусами, человек должен обладать водительскими правами по категории «D»:
- категория «D» — транспорт перевозящий пассажиров с более чем 8 сидячими местами. Водительское место в общее число мест не входит;
- транспорт категории «D» в связке с прицепом, весящим не больше чем 750 килограмм.
Категория «D» дает право управления автобусами различных типоразмеров не зависимо от их массы, в том числе связкой «автобус плюс прицеп» с максимальный весом последнего не более 750 кг. В том случае если масса самого прицепа более 750 кг – необходима открытая категория «DE».
Категория «DE»
«DЕ» – транспорт из категории «D» в связке с прицепом весящим более больше чем 750 килограммов.![]() Сюда же причислен сочлененный автобус.
Сюда же причислен сочлененный автобус.
Подкатегория «D1»
- подкатегория «D1» — автомобиль для транспортировки пассажиров имеющий больше 8 и меньше 16 сидячих мест, не включая водительское сиденья;
- автомобиль подкатегории «D1» в связке с прицепом весом не более 750 килограмм;
Такая подкатегория разрешает управлять маленьким автобусом ( от 9 до 16 мест), а также эксплуатировать легкий прицеп (вес — менее 750 кг).
Подкатегория «D1E» — тяжелый прицеп
Если есть необходимость использовать более тяжелые прицепы – нужна будет подкатегория «D1E» для водителя автобуса:
- подкатегория «D1Е» — машины подкатегории «D1» в связке с прицепом, весящим не больше чем 750 килограмм и который не эксплуатируется для перевозки людей. Масса прицепа не должна быть больше массы самого основного транспорта без нагрузки и общая масса такой сцепки не должна быть больше 12 тонн.
Категория «D» разрешает водителю управлять ТС из категории «D1», а «DE» – из категории «D1E».

Категория «E»
На сегодня категории «E» уже не существует. Ее заменили охарактеризованные выше, категории BE, CE, C1E, DE, D1E.
В том случае если вас интересует обмен старого удостоверения с категорией «Е» — читайте наш материал «Перенос категории E в новые права«.
Категория «Tb» / «Tm» — трамвай /троллейбусы
Чтобы управлять трамваем или троллейбусом, начиная с 2016 года и уже в 2019 году, человеку потребуются права со специальной категорией «Tb» / «Tm».
Все ещё остались вопросы?
Задавайте Ваши вопросы здесь и наш автоюрист БЕСПЛАТНО ответит на все Ваши вопросы.
Последнее обновление: 04-09-2020
Страница не найдена
К сожалению, страница, которую вы искали на веб-сайте AAAI, не находится по URL-адресу, который вы щелкнули или ввели:
https://www.aaai.org/papers/aaai/2008/aaai08-193.pdf Если указанный выше URL-адрес заканчивается на «. html», попробуйте заменить «.html:» на «.php» и посмотрите, решит ли это проблему.
html», попробуйте заменить «.html:» на «.php» и посмотрите, решит ли это проблему.
Если вы ищете конкретную тему, попробуйте следующие ссылки или введите тему в поле поиска на этой странице:
- Выберите темы AI, чтобы узнать больше об искусственном интеллекте.
- Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство».
- Выберите «Публикации», чтобы узнать больше о AAAI Press и журналах AAAI.
- Для рефератов (а иногда и полного текста) технических документов по ИИ выберите Библиотека
- Выберите AI Magazine, чтобы узнать больше о флагманском издании AAAI.
- Чтобы узнать больше о конференциях и встречах AAAI, выберите Conferences
- Для ссылок на симпозиумы AAAI выберите «Симпозиумы».
- Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «Организация».
Помогите исправить страницу, которая вызывает проблему
Интернет-страница
, который направил вас сюда, должен быть обновлен, чтобы он больше не указывал на эту страницу. Вы поможете нам избавиться от старых ссылок? Напишите веб-мастеру ссылающейся страницы или воспользуйтесь его формой, чтобы сообщить о неработающих ссылках. Это может не помочь вам найти нужную страницу, но, по крайней мере, вы можете избавить других людей от неприятностей. Большинство поисковых систем и каталогов имеют простой способ сообщить о неработающих ссылках.
Вы поможете нам избавиться от старых ссылок? Напишите веб-мастеру ссылающейся страницы или воспользуйтесь его формой, чтобы сообщить о неработающих ссылках. Это может не помочь вам найти нужную страницу, но, по крайней мере, вы можете избавить других людей от неприятностей. Большинство поисковых систем и каталогов имеют простой способ сообщить о неработающих ссылках.
Если это кажется уместным, мы были бы признательны, если бы вы связались с веб-мастером AAAI, указав, как вы сюда попали (т. Е. URL-адрес страницы, которую вы искали, и URL-адрес ссылки, если он доступен). Спасибо!
Содержание сайта
К основным разделам этого сайта (и некоторым популярным страницам) можно перейти по ссылкам на этой странице. Если вы хотите узнать больше об искусственном интеллекте, вам следует посетить страницу AI Topics. Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство».Выберите «Публикации», чтобы узнать больше о AAAI Press, AI Magazine, и журналах AAAI. Чтобы получить доступ к цифровой библиотеке AAAI, содержащей более 10 000 технических статей по ИИ, выберите «Библиотека». Выберите Награды, чтобы узнать больше о программе наград и наград AAAI. Чтобы узнать больше о конференциях и встречах AAAI, выберите «Встречи». Для ссылок на программные документы, президентские обращения и внешние ресурсы ИИ выберите «Ресурсы». Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «О нас» (также «Организация»).Окно поиска, созданное Google, будет возвращать результаты, ограниченные сайтом AAAI.
Чтобы получить доступ к цифровой библиотеке AAAI, содержащей более 10 000 технических статей по ИИ, выберите «Библиотека». Выберите Награды, чтобы узнать больше о программе наград и наград AAAI. Чтобы узнать больше о конференциях и встречах AAAI, выберите «Встречи». Для ссылок на программные документы, президентские обращения и внешние ресурсы ИИ выберите «Ресурсы». Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «О нас» (также «Организация»).Окно поиска, созданное Google, будет возвращать результаты, ограниченные сайтом AAAI.
Бунт на Капитолии: расшифровка экстремистских символов, групп во время восстания на Капитолийском холме
Флаги, знаки и символы расистских, сторонников превосходства белой расы и экстремистских групп были показаны вместе с баннерами Трампа 2020 и американскими флагами во время беспорядков в среду у Капитолия США. Фотографии рассказывают часть истории убеждений некоторых из тех, кто решил явиться в этот день — от страстных и мирных сторонников Трампа до экстремистов, которые продемонстрировали свою ненависть с помощью своих символов, а также своими действиями.
СВЯЗАННЫЕ: Аресты Капитолия США: Список обвинений для арестованных в хаосе округа Колумбия
Смешивание групп — одна из проблем, которая давно беспокоит экспертов, отслеживающих экстремизм и ненависть.
Подтверждение результатов выборов оказалось именно тем мероприятием, которое объединило различные группы и могло привести к распространению радикальных идей, говорят они. Первоначальное мероприятие, которое активно продвигалось и поощрялось президентом Трампом, дало всем этим группам возможность сплотиться.
«Это мероприятие было направлено против результатов свободных и справедливых демократических выборов и естественной смены власти», — сказал Марк Питкэвидж, историк и эксперт по экстремизму из Антидиффамационной лиги.
CNN поговорил с ним, чтобы определить символы и понять ужасающие послания тирании, превосходства белых, анархии, расизма, антисемитизма и ненависти, которые они изображают.
Петля и виселица
Хотя петля сама по себе часто используется как форма расового запугивания, Питкэвидж считает, что в этом контексте виселица должна была предполагать наказание за совершение государственной измены. «Это предполагает, что представители и сенаторы, которые голосуют за подтверждение результатов выборов, и, возможно, вице-президент Пенс, совершают измену и должны быть преданы суду и повешены», — поясняет он.
«Это предполагает, что представители и сенаторы, которые голосуют за подтверждение результатов выборов, и, возможно, вице-президент Пенс, совершают измену и должны быть преданы суду и повешены», — поясняет он.
Эта риторика об измене была замечена на досках объявлений правых за несколько дней до события.
Флаг «Три процента»
«Три процента» (также известные как «третьи проценты», «3 процента» или «тройки») являются частью движения ополченцев в Соединенных Штатах и являются антиправительственными экстремистами, согласно ADL.
Как и другие участники движения ополченцев, «Трехпроцентники» считают себя защитниками американского народа от правительственной тирании.
«Поскольку многие сторонники ополчения решительно поддерживают президента Трампа, в последние годы« Трехпроцентники »не так активно выступали против федерального правительства, направляя свой гнев на других предполагаемых врагов, включая левых / антифа, мусульман и иммигрантов», согласно ADL.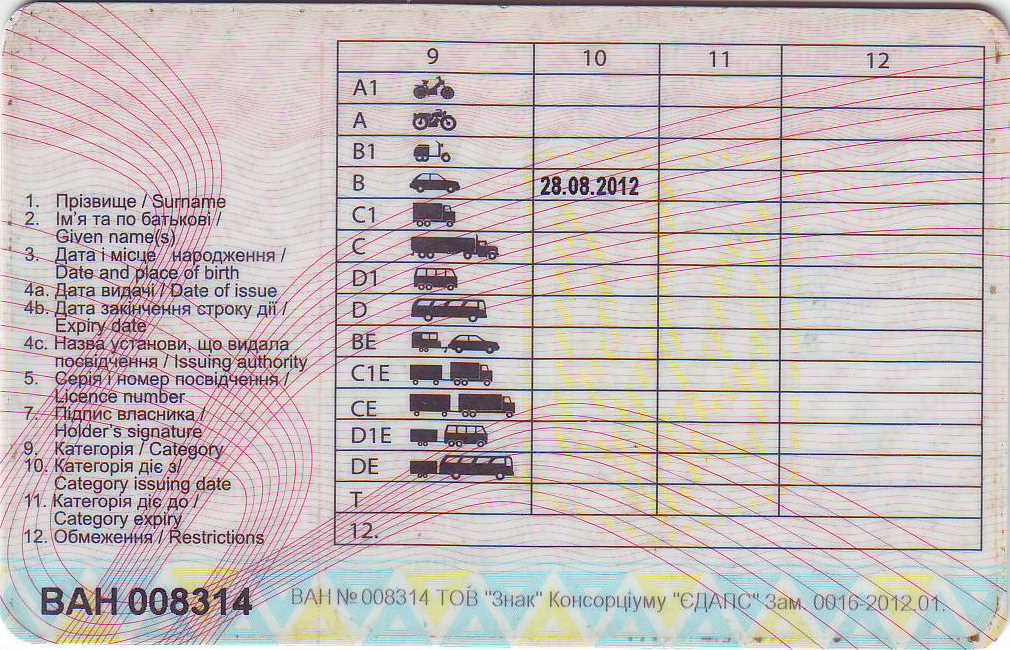
Название группы происходит от неточного утверждения о том, что только три процента жителей колоний вооружились и воевали против британцев во время Войны за независимость.
Флаг, показанный выше, является их логотипом на традиционном флаге Бетси Росс. Питкэвидж говорит, что правые группы (мейнстримные или экстремистские), считающие себя патриотами, иногда кооптируют первый флаг Америки.
Флаг «Освободить Кракена»
Флаг ссылается на комментарии бывшего адвоката Трампа Сидни Пауэлла о том, что она собиралась «освободить Кракена». Пауэлл ложно заявила, что у нее есть доказательства, которые разрушили бы идею о том, что Джо Байден выиграл президентский пост.
«Кракен», гигантское морское существо из скандинавского фольклора, превратилось в мем в кругах, которые считают, что выборы были украдены.Они говорят, что Kraken — это кладезь доказательств того, что мошенничество было широко распространено. В социальных сетях широко распространяются сообщения о заговоре QAnon и второстепенные сайты #ReleaseTheKraken, а также ложные теории мошенничества.
Гордые мальчики и знак ОК
Крайне правые использовали знак ОК как троллинговый жест, а для некоторых — как символ силы белых. ADL добавила этот символ в давнюю базу данных лозунгов и символов, используемых экстремистами.
«Они носят оранжевые кепки, чтобы идентифицировать друг друга; на прошлых митингах они носили опознавательные рубашки и другое снаряжение, но они отказались от этого для этого события после того, как их лидер был недавно арестован», — пояснил Питкэвидж.
The Proud Boys поддерживали президента Трампа и присутствовали на митингах «Stop The Steal» в Вашингтоне, округ Колумбия. Лидер Proud Boys Генри Таррио, которого зовет Энрике Таррио, был освобожден из-под стражи во вторник по обвинениям, связанным с якобы сожжением баннера Black Lives Matter, взятого из черной церкви в прошлом месяце во время протестов в городе после акции «Stop the Steal» «митинг в прошлом месяце. Местный судья приказал ему держаться подальше от округа Колумбия, пока он ожидает суда, в том числе во время протестов на этой неделе.

Флаги «Кекистан»
Зелено-бело-черный флаг был создан некоторыми членами онлайн-сообщества 4chan, чтобы представить выдуманную страну-шутку, названную в честь «Кека», вымышленного бога, которого они также создали. Он давно присутствует на митингах правых и крайне правых.
«Флаг Кекистана вызывает споры, потому что его дизайн частично заимствован из флага нацистской эпохи; это, по-видимому, было сделано намеренно в шутку», — пояснил Питкавадж. «Молодые правые из субкультуры 4chan (как основные правые, так и крайне правые) часто любят вывешивать флаг Кекистана на митингах и мероприятиях.»
Измененные исторические флаги
Измененные флаги Конфедерации и Гадсдена были замечены в толпе у Капитолия. Одна из вариаций боевого флага Конфедерации включала изображение штурмовой винтовки и слоган» Приходите и возьмите его «, чтобы передать анти-оружие Контрольное сообщение. Фраза «приди и возьми» перефразирует реплику «приди и возьми их», произнесенную спартанским царем Леонидом в битве при Фермопилах, когда персидский царь Ксеркс сказал ему и его людям сложить копья в обмен на свою жизнь — сказал Питкавадж.
Флаг Гадсдена, известный многим как флаг «Не наступай на меня», является традиционным и историческим патриотическим флагом, датируемым американской революцией. Флаг и символ также популярны среди либертарианцев. Но это также было кооптировано правыми группами. Питкэвидж объясняет, что, хотя некоторые используют его как символ патриотизма, другие используют его как «символ сопротивления предполагаемой тирании».
Хранители присяги
В Капитолии виден мужчина в шляпе Хранителей присяги после того, как она была нарушена.Хранители присяги — это поддерживающая Трампа, крайне правая, антиправительственная группа, которая считает себя частью движения ополченцев, призванных защищать страну и защищать конституцию. Группа пытается вербовать членов из числа действующих или отставных военных, служб быстрого реагирования или полиции.
Их лидер извергал обширные теории заговора в своем блоге, обвинял демократов в краже результатов выборов, ранее угрожал насилием, если это будет необходимо в день выборов во время интервью с крайне правым заговорщиком Алексом Джонсом, и сказал, что его группа будет вооружена для защиты Белый дом при необходимости, сообщает ADL.
Флаг Конфедерации
Во время долгой Гражданской войны в Соединенных Штатах боевой флаг Конфедерации не попадал в тень Капитолия США, но в среду мятежник пронес один прямо через его залы.
Фотографы запечатлели человека, несущего его мимо портретов аболициониста Чарльза Самнера и рабовладельца Джона Калхуна.
Флаг всегда был символом поддержки рабства. После Второй мировой войны он стал ярким символом Джима Кроу и сегрегации, неудивительно говорит, что он стал популярным символом среди сторонников превосходства белой расы — даже за пределами Соединенных Штатов.
Флаг Америки прежде всего
Мятежник облачается в флаг «Америка прежде всего» с логотипом подкаста крайне правого комментатора Ника Фуэнтеса. Фуэнтес присутствовал на мероприятии в Капитолии, но был сфотографирован, оставаясь за пределами здания Капитолия.
«Америка прежде всего» — также лозунг, который президент Трамп использовал при описании своей внешней политики. Его принятие подверглось критике со стороны ADL, заявившей, что он использовался в антисемитских целях, чтобы не допустить США во Вторую мировую войну.
Его принятие подверглось критике со стороны ADL, заявившей, что он использовался в антисемитских целях, чтобы не допустить США во Вторую мировую войну.
ADL утверждает, что Фуэнтес является частью «армии гройперов», которую ADL называет группой сторонников превосходства белых.
«В то время как взгляды группы и руководства совпадают с взглядами сторонников превосходства белых альт-правых, гройперы пытаются нормализовать свою идеологию, присоединяясь к« христианству »и« традиционным »ценностям, якобы отстаиваемым церковью, включая брак и семью «ADL объясняет. «Подобно альт-правым и другим сторонникам превосходства белых, гройперы считают, что они работают, чтобы защитить себя от демографических и культурных изменений, которые разрушают« истинную Америку »- белую христианскую нацию.«
» Лагерь Освенцим »
Мятежник внутри Капитолия был одет в толстовку« Лагерь Освенцим ». На нижней части рубашки написано« Работа приносит свободу », что является грубым переводом слов« Arbeitmacht frei »на воротах нацистский концлагерь. Освенцим был самым большим и самым печально известным нацистским концентрационным лагерем, где во время Второй мировой войны было убито около 1,1 миллиона человек.
Освенцим был самым большим и самым печально известным нацистским концентрационным лагерем, где во время Второй мировой войны было убито около 1,1 миллиона человек.
Питкавадж говорит, что, по его мнению, рубашка пришла с ныне несуществующего веб-сайта Aryanwear. существует уже около 10 лет, по данным Pitcavage, в последние недели появляется на разных веб-сайтах, хотя часто удаляется при подаче жалобы.
Наклейки Nationalist Social Club
Изображение в социальной сети показывает наклейки Nationalist Social Club на том, что, похоже, является оборудованием полиции Капитолия США. Неясно, когда была сделана фотография, но она была опубликована в среду в чате Telegram, который использует группа, включая нацистский символ как часть их имени.
NSC, очевидно, игра слов о национал-социалистах или нацистской партии, является неонацистской группировкой, у которой есть региональные отделения как в Соединенных Штатах, так и по всему миру, согласно ADL.Неясно, относится ли наклейка справа к отделению в Новой Англии или потому, что группа изначально называла себя Клубом националистов Новой Англии.
«Члены КНБ видят себя солдатами, ведущими войну с враждебной, контролируемой евреями системой, которая намеренно замышляет вымирание белой расы», согласно ADL. «Их цель — сформировать подпольную сеть белых людей, которые готовы сражаться со своими предполагаемыми врагами посредством локальных прямых действий».
MAGA Civil War 6 января 2021 г. рубашки
Есть еще много вопросов о том, как именно произошло нападение на Капитолий и кто возглавил атаку.Но призывы к свержению правительства и к гражданской или расовой войне уже давно вызывают крики в ультраправых кругах.
Рубашки, которые носили эти люди на территории Капитолия в среду, показывают, что, по крайней мере, было намерение отметить этот день. На них были футболки с заранее напечатанными рисунками, со ссылкой на фирменный лозунг Трампа «Сделай Америку снова великой», а также слова «Гражданская война» и дата события, которое переросло в восстание.
Многие комментаторы на ультраправых форумах писали после нападения, что это только начало той гражданской войны, которую многие из них давно желали.
(The-CNN-Wire и 2021 Cable News Network, Inc., компания Time Warner. Все права защищены.)
границ | Расшифровка трех разных уровней предпочтений потребителей с помощью сверточной нейронной сети: исследование функциональной спектроскопии в ближнем инфракрасном диапазоне
Введение
Основным ограничением в современной индустрии коммерческого видео является то, что все видео оцениваются субъективно при их просмотре. Целью данной статьи является разработка систематического количественного метода оценки уровней предпочтений потребителей при просмотре видео с использованием неинвазивного метода изображения мозга, функциональной ближней инфракрасной спектроскопии (fNIRS).В области распознавания и классификации (Moon et al., 2018; Zhang et al., 2018; Ansari et al., 2019; Kim, Choi, 2019; Kim et al., 2019; Manzanera et al., 2019; Shan et al., 2019; Yang et al., 2019; Lee et al., 2020; Leming et al., 2020; Liu et al., 2020; Lun et al., 2020; Thomas et al. , 2020; Ye et al., al., 2020), сверточные нейронные сети (CNN) показали превосходные характеристики классификации при обнаружении речи, искусственном интеллекте и обработке множественных временных рядов по сравнению с другими традиционными методами (Bengio, 2009; Kim et al., 2018). Благодаря способности CNN извлекать важные особенности из полученных сигналов, они используются в качестве инструмента для декодирования сигналов fNIRS. Разработана схема CNN, подходящая для извлечения признаков из полученных сигналов гемодинамического ответа. В частности, мы определили эффективность fNIRS на основе CNN при декодировании входных данных сигналов гемодинамического ответа и классификации различных уровней предпочтений потребителей.
, 2020; Ye et al., al., 2020), сверточные нейронные сети (CNN) показали превосходные характеристики классификации при обнаружении речи, искусственном интеллекте и обработке множественных временных рядов по сравнению с другими традиционными методами (Bengio, 2009; Kim et al., 2018). Благодаря способности CNN извлекать важные особенности из полученных сигналов, они используются в качестве инструмента для декодирования сигналов fNIRS. Разработана схема CNN, подходящая для извлечения признаков из полученных сигналов гемодинамического ответа. В частности, мы определили эффективность fNIRS на основе CNN при декодировании входных данных сигналов гемодинамического ответа и классификации различных уровней предпочтений потребителей.
Интерфейс мозг-компьютер (BCI), коммуникационный мост между мозгом человека и внешним устройством, используется для обнаружения и декодирования человеческого познания и поведения.BCI также обычно используются для декодирования нейронной активности головного мозга для восстановления функции движения или для управления машинами и роботами (Zander and Kothe, 2011; LaFleur et al. , 2013; Degrave et al., 2019; Fiederer et al., 2019). ; Hu et al., 2019; Li and Shi, 2019; Furlan et al., 2020; Grossberg, 2020; Kwon et al., 2020). Недавно применение BCI было расширено для декодирования потребительской мотивации, эмоций и принятия решений (Yun et al., 2019; Giustiniani et al., 2020; Neo et al., 2020). О нейронных процессах потребителей, лежащих в основе их суждений о расширении бренда услуг, сообщается с помощью различных рекламных роликов (Yang et al., 2015; Ян и Ким, 2019). Основные процессы эффективной системы BCI включают: (а) получение церебральных сигналов с использованием техники нейровизуализации, (б) обработку и анализ сигналов для получения характеристик, представляющих сигнал, и (в) преобразование функций в команды для управления устройствами и декодирования. человеческое познание (Daly and Wolpaw, 2008; Valeriani, Poli, 2019). Системы BCI разрабатывались в течение нескольких лет на основе неинвазивных методов (Birbaumer et al., 1999; Dornhege, 2007; Pamosoaji et al.
, 2013; Degrave et al., 2019; Fiederer et al., 2019). ; Hu et al., 2019; Li and Shi, 2019; Furlan et al., 2020; Grossberg, 2020; Kwon et al., 2020). Недавно применение BCI было расширено для декодирования потребительской мотивации, эмоций и принятия решений (Yun et al., 2019; Giustiniani et al., 2020; Neo et al., 2020). О нейронных процессах потребителей, лежащих в основе их суждений о расширении бренда услуг, сообщается с помощью различных рекламных роликов (Yang et al., 2015; Ян и Ким, 2019). Основные процессы эффективной системы BCI включают: (а) получение церебральных сигналов с использованием техники нейровизуализации, (б) обработку и анализ сигналов для получения характеристик, представляющих сигнал, и (в) преобразование функций в команды для управления устройствами и декодирования. человеческое познание (Daly and Wolpaw, 2008; Valeriani, Poli, 2019). Системы BCI разрабатывались в течение нескольких лет на основе неинвазивных методов (Birbaumer et al., 1999; Dornhege, 2007; Pamosoaji et al. , 2019) и инвазивных (Lal et al., 2004; Leuthardt et al., 2004) методов нейровизуализации, таких как электроэнцефалография (ЭЭГ) (Cheng et al., 2002; Parra et al., 2002; Buttfield et al., 2006 ; Blankertz et al., 2007; Mellinger et al., 2007; Fazli et al., 2012; Kang et al., 2015; Park et al., 2018), магнитоэнцефалография (Mellinger et al., 2007; Buch et al. , 2008), электрокортикографии (ECoG) (Leuthardt et al., 2004), функциональной магнитно-резонансной томографии (fMRI) (LaConte, 2011; Chaudhary et al., 2017) и fNIRS (Fazli et al., 2012; Chaudhary et al., 2017; Хан и др., 2018; Канг и др., 2018; Шин и др., 2018; Хонг и Фам, 2019; Фам и Хонг, 2020). Среди этих методов основными преимуществами fNIRS являются его неинвазивность, портативность, низкая стоимость, удобство ношения и умеренное временное и пространственное разрешение. Поскольку fNIRS является оптическим методом, его типы сбора данных не подвержены электрогенным артефактам (Moghimi et al., 2012). В этом исследовании fNIRS использовался в качестве метода нейровизуализации для обнаружения церебральных гемодинамических реакций.
, 2019) и инвазивных (Lal et al., 2004; Leuthardt et al., 2004) методов нейровизуализации, таких как электроэнцефалография (ЭЭГ) (Cheng et al., 2002; Parra et al., 2002; Buttfield et al., 2006 ; Blankertz et al., 2007; Mellinger et al., 2007; Fazli et al., 2012; Kang et al., 2015; Park et al., 2018), магнитоэнцефалография (Mellinger et al., 2007; Buch et al. , 2008), электрокортикографии (ECoG) (Leuthardt et al., 2004), функциональной магнитно-резонансной томографии (fMRI) (LaConte, 2011; Chaudhary et al., 2017) и fNIRS (Fazli et al., 2012; Chaudhary et al., 2017; Хан и др., 2018; Канг и др., 2018; Шин и др., 2018; Хонг и Фам, 2019; Фам и Хонг, 2020). Среди этих методов основными преимуществами fNIRS являются его неинвазивность, портативность, низкая стоимость, удобство ношения и умеренное временное и пространственное разрешение. Поскольку fNIRS является оптическим методом, его типы сбора данных не подвержены электрогенным артефактам (Moghimi et al., 2012). В этом исследовании fNIRS использовался в качестве метода нейровизуализации для обнаружения церебральных гемодинамических реакций.
Напротив, приложения BCI были разработаны для улучшения познания поведения потребителей. Окружающая среда, включая дружбу и эмоции, может повлиять на одобрение продукта и готовность платить (Liao et al., 2019). Поведение потребителей, финансовые услуги, этап оценки и принятие решений в рекламе связаны с изменениями реакции нервной коры в текущих исследованиях, чтобы дополнительно проверить возможность применения в нейромаркетинге (Senior et al., 2015; Ramsøy et al., 2018; Wei et al., 2018; Чераволо и др., 2019; Ma et al., 2019; Hu et al., 2020). Vences et al. (2020) обобщили теоретический обзор основных нейронных исследований эффективности нейромаркетинга, который является инструментом нейронного измерения для усиления эмоциональной связи между потребителями и организациями в социальных сетях. Нейробиология используется в качестве нового доступа, позволяющего лучше понять поведенческое познание потребителей, принятие решений о покупке, предпочтения, ощущающие обратную связь и т. Д. В частности, нейробиология также была разработана, чтобы помочь маркетологам понять, как повлиять на физиологическое поведение потребителей, демонстрируя рекламу и маркетинг стратегии (Lee et al., 2007). С точки зрения исследователей, техника нейромаркетинга стала новым подходом к исследованию коммерческих рекламных объявлений, содержащих различные комбинации элементов, предпочтений потребителей и принятия решений. Нейробиология и маркетинг соединяют расшифровку нейрокогнитивных принципов потребителей и продуктов, предпочитаемых в приложении нейромаркетинга.
Д. В частности, нейробиология также была разработана, чтобы помочь маркетологам понять, как повлиять на физиологическое поведение потребителей, демонстрируя рекламу и маркетинг стратегии (Lee et al., 2007). С точки зрения исследователей, техника нейромаркетинга стала новым подходом к исследованию коммерческих рекламных объявлений, содержащих различные комбинации элементов, предпочтений потребителей и принятия решений. Нейробиология и маркетинг соединяют расшифровку нейрокогнитивных принципов потребителей и продуктов, предпочитаемых в приложении нейромаркетинга.
Результаты Wang et al. (2016) предполагают, что видеоролики с линейной структурой и демонстрация одного бренда делают область коры более активной, чем другие комбинации.Определение способов объединения различных ресурсов является важным решением для определения вовлеченности продукта и повышения уровня предпочтений. Структура рекламы была исследована исследователями в области психологии и маркетинга. Они проанализировали, как сюжет и структура сценария влияют на поведение потребителей, и постепенно разобрались в брендовом продукте. Кроме того, с помощью рекламы они пытались привлечь внимание аудитории, чтобы лучше убедить потребителей (Stern, 1994; Mattila, 2000; Phillips and McQuarrie, 2010).Чтобы понять потребности потребителей, маркетологи ставят цели для желаемой эффективности рекламы и коммуникации (Lavidge and Steiner, 1961; Foekens et al., 1997). Котлер (2000) резюмировал процесс в следующих трех стадиях: (i) когнитивная стадия, (ii) эффективная стадия и (iii) поведенческая стадия. Уровень предпочтения рекламы считается лучшим показателем ее эффективности и коммуникабельности. Таким образом, широко распространенное коммерческое рекламное видео вызывает положительный отклик в отношении бренда и помогает ему противостоять конкуренции (Edith et al., 2006).
Кроме того, с помощью рекламы они пытались привлечь внимание аудитории, чтобы лучше убедить потребителей (Stern, 1994; Mattila, 2000; Phillips and McQuarrie, 2010).Чтобы понять потребности потребителей, маркетологи ставят цели для желаемой эффективности рекламы и коммуникации (Lavidge and Steiner, 1961; Foekens et al., 1997). Котлер (2000) резюмировал процесс в следующих трех стадиях: (i) когнитивная стадия, (ii) эффективная стадия и (iii) поведенческая стадия. Уровень предпочтения рекламы считается лучшим показателем ее эффективности и коммуникабельности. Таким образом, широко распространенное коммерческое рекламное видео вызывает положительный отклик в отношении бренда и помогает ему противостоять конкуренции (Edith et al., 2006).
В существующих исследованиях fNIRS использовался в качестве превосходного метода нейровизуализации для мониторинга гемодинамических реакций мозга с использованием нейроваскулярного сопряжения по сравнению с другими методами. Кроме того, сосудисто-нервное соединение, которое фиксирует снижение деоксигенированного гемоглобина (HbR) и увеличение оксигенированного гемоглобина (HbO) во время активности мозга, происходит в коре головного мозга. Для проведения эксперимента в системе fNIRS использовались несколько излучателей и детекторов света; длина волны света составляла от 650 до 950 нм.Вариации концентраций HbO и HbR рассчитывались с использованием модифицированного закона Бера-Ламберта (MBLL) (Villringer et al., 1993). Многие алгоритмы машинного обучения (Naseer and Hong, 2015), такие как глубокое обучение, глубокая нейронная сеть и сверточная нейронная сеть, ранее применялись в нейробиологии, чтобы сосредоточиться на извлечении признаков и повышении точности классификации. Для выделения признаков было показано, что сигналы во временной области (Naseer and Hong, 2015) и коэффициенты фильтра из непрерывных и дискретных вейвлет-преобразований (DWT) (Khoa and Nakagawa, 2008; Abibullaev and An, 2012) определяют статистические свойства, такие как среднее значение, асимметрия, эксцесс и наклон, а измерения основывались на объединенной общей информации.Кроме того, для модальностей нейровизуализации на основе машинного обучения была представлена классификация на основе функциональной связности фМРТ в состоянии покоя с использованием архитектуры CNN (Meszlenyi et al., 2017). Он также продемонстрировал, что применение глубокого обучения к этому объекту исследования подходит, учитывая характер записей fNIRS (Rosas-Romero et al., 2019; Janani et al., 2020). Hiwa et al. (2016) проанализировали функции мозга, выполнив предметную классификацию данных fNIRS с использованием анализа CNN.Для обработки характеристик сигналов, полученных с помощью методов нейровизуализации, в большинстве предыдущих исследований были извлечены статистические значения сигналов во временной области. Однако размер временного окна (Hong et al., 2015) и лучший набор комбинированных характеристик (Naseer et al., 2016) являются критическими факторами в достижении высокой точности классификации.
В целом, нейромаркетинг — это инновационная область исследований, позволяющая интерпретировать конкурентное поведение потребителей и расшифровывать познания потребителей. С развитием инструментов нейровизуализации метод fNIRS постепенно приближается к пониманию исследователя, позволяющему напрямую обнаружить кору головного мозга.Среди этих методов некоторые базовые и традиционные методы, такие как машина опорных векторов, линейный дискриминантный анализ, многопараметрическое линейное программирование и т. Д., Используются для извлечения и классификации собранных мозговых данных. Судя по предыдущим исследованиям обработки массивных данных, традиционные методы продемонстрировали низкий уровень интеллекта, более низкую производительность извлечения и более низкую точность классификации в понимании намерений потребителей. Благодаря успешному применению CNN, он используется в нашей работе, демонстрируя его специфическую структуру для нейромаркетинга.Короче говоря, метод fNIRS на основе CNN приводит к новой структуре обработки, которая является превосходным методом для извлечения и классификации признаков.
Цели этого документа: (i) выяснить, существуют ли подходящие длительности видео для типов продуктов с точки зрения зрителя (возможно, существует оптимальная продолжительность, но в этом документе сравнивались только три продолжительности), (ii) продемонстрировать использование fNIRS в доступе к намерениям потребителей с точки зрения типов продуктов и продолжительности видео, (iii) проиллюстрировать конкретную структуру CNN, подходящую для декодирования гемодинамических ответов для нейромаркетинга, и (iv) разработать основанную на CNN метод расшифровки уровней предпочтений потребителей.Связь между fNIRS и нейромаркетингом заключается в том, что fNIRS — это носимое устройство, которое может измерять активность мозга, не спрашивая о нераскрытом намерении человека: особенно при оценке видео, экзаменатор с fNIRS может оценивать несколько видео одновременно, потому что fNIRS безвреден, бесшумный, недорогой, пригодный для использования в обычных условиях и т. д.
Остальная часть этого документа организована следующим образом. В разделе «Методы и материалы» кратко описаны экспериментальная процедура, предварительная обработка и преобразование сигналов, а также предлагаемые структуры CNN – fNIRS.В разделах «Результаты», «Обсуждение», «Ограничения» и «Будущие перспективы» и «Заключение» представлены результаты, обсуждение, ограничения и выводы исследования.
Методы и материалы
Заявление об этикеЭксперимент проводился с одобрения Институционального наблюдательного совета Пусанского национального университета (номер IRB PNU IRB / 2016_101_HR). Письменное согласие было получено от всех субъектов до начала эксперимента, а процедура эксперимента была проведена в соответствии с этическими стандартами, установленными в последней Хельсинкской декларации (Santosa et al., 2013; Нгуен и др., 2016).
Участников
В этом исследовании восемь здоровых взрослых, включая четырех женщин (участники 1, 2, 3, 4) и четырех мужчин (участники 5, 6, 7, 8), были набраны из Пусанского национального университета. Таблица 1 показывает обобщенную информацию для восьми участников ( M возраст = 26, SD возраст = 1,85; возраст мин. = 24, возраст макс. = 29), включая возраст, пол и образование. задний план. В этом эксперименте все участники находятся справа, чтобы уменьшить разницу в доминировании полушария в зрительных стимулах.У них не было никаких зрительных, психических или неврологических расстройств. Перед началом эксперимента участников просили воздерживаться от употребления кофе и курения перед визуальными стимулами, и всем участникам была проведена исчерпывающая инструкция по всему содержанию эксперимента. Во время визуальных стимулов участников просили сосредоточиться на каждом видео в расслабленной позе.
Таблица 1 . Статистическая информация участников.
Экспериментальная парадигма
Был проведен онлайн-опрос об участии бренда в различных продуктах, чтобы уменьшить влияние бренда продукта во время экспериментов и получить соответствующую коммерческую рекламу.В видеороликах представлены три различных типа брендов, включая колу, шоколад и перформанс. Участников попросили написать рейтинг от 1 до 100 на основе знания бренда и покупательского поведения. По результатам вовлеченности бренда были получены комплексные баллы (F1: 84 ± 0,61; F2: 79 ± 0,39; F3: 80 ± 0,56). Среди этих выступлений кола показала наивысший балл, позволивший продолжить поиск стимулирующих материалов. Рекламные видеоролики (например, рекламные видеоролики Coca-Cola и Pepsi Cola) были использованы для проведения эксперимента по стимуляции: два разных типа и три разных продолжительности (т.е., 15, 30 и 60 с). Они были получены с профессионального рекламного видео-сайта с помощью поиска Google. Участникам впервые были показаны видеоролики с отличным разрешением. Вкратце, шесть коммерческих рекламных видеороликов были разделены на два типа (Coca-Cola и Pepsi Cola): каждый тип состоит из видеороликов с тремя разными длительностями (15, 30 и 60 секунд). В этом исследовании за пробой стимуляции следовал период отдыха продолжительностью 35 с (оценка: 5 с, отдых: 30 с). Каждое видео было представлено отдельно в последовательности, образуя три разные комбинации (см. Рисунок 1).
Рисунок 1 . Экспериментальная парадигма: (A) видеороликов Coca-Cola, (B) видеороликов Pepsi Cola.
Участников попросили сесть на удобные стулья перед экраном компьютера (модель Samsung LED: LS24A300), на котором отображались экспериментальные задания. Расстояние просмотра от экрана составляло ~ 45–55 см, разрешение видео — 1080 × 720 пикселей. Вся коммерческая реклама воспроизводилась на экране в порядке продолжительности 15, 30, 60 с.Одно испытание состоит из 2-х секундных визуальных уведомлений, видеостимула, за которым следуют 5-секундная оценка и 30-секундный отдых, а продолжительность видеостимула включает 15, 30, 60 секунд отдельно. Один раздел содержит начальные 120-секундные перерывы и 216-секундный процесс задания (последовательно были показаны три попытки по 15, 30 и 60 секунд). Задание было выполнено дважды, в результате чего было проведено 12 испытаний. Продолжительность всего эксперимента составила 1104 с (см. Рисунок 1). Все участники были разделены на две группы: мужскую и женскую.Двум группам было предложено завершить экспериментальные стимулы в выходные дни соответственно.
Анализ поведенческих данных
Для анализа поведенческих данных были получены оценки отдельных испытаний. Статистический метод, называемый односторонним дисперсионным анализом (ANOVA), был использован для анализа всесторонних оценок, включая предпочтительную продолжительность воспроизведения видео (нравится ли вам продолжительность воспроизведения этого видео?) И предпочтения бренда продукта (вам нравится этот продукт?) . Статистически проанализированы шесть групп рекламы в стимулирующих различиях.Попарные сравнения поведенческих данных были выполнены с использованием апостериорных тестов Scheffe . С другой стороны, шесть различных коммерческих видеороликов состояли из двух типов, включая две независимые переменные: брендинг продукта и продолжительность воспроизведения. Независимый образец t -тест был использован для анализа влияния двух независимых переменных на предпочтения в отношении продолжительности воспроизведения видео и бренда продукта.
Сбор данных fNIRS
Для конфигурации каналов церебральной префронтальной области, 12 измерительных каналов, включая три детектора и восемь излучателей, были размещены над префронтальной областью (рис. 2).Слева и справа от префронтальной коры каналы с 1 по 6 и с 7 по 12 определялись отдельно. Свет имеет способность неинвазивно проходить через ткань коры головного мозга, образуя форму «банана». Fp1 и Fp2 использовались в качестве стандартных эталонов для международной системы 10–20. Для сбора данных использовалась многоканальная система непрерывного fNIRS (ISS Imagent, ISS Inc., США) для измерения гемодинамических ответов. Система измеряет оптическую интенсивность двух длин волн (690 и 830 нм), что позволяет оценить концентрацию гемоглобина.Для регистрации сигналов использовалась частота дискретизации 15,625 Гц, а расстояние между источником и детектором составляло 2,828 см.
Рисунок 2 . Конфигурация каналов в префронтальной коре.
Предварительная обработка данных fNIRS
Необработанные данные об оптической интенсивности ΔHbO и ΔHbR были получены для всех каналов измерения с использованием системы сбора данных ISS Imagent. Затем необработанные данные были преобразованы в ΔHbO и ΔHbR с использованием программного обеспечения для анализа ISS-Boxy с коэффициентом дифференциального пути (DPF), расстоянием эмиттер-детектор и коэффициентами экстинкции εHbO = 2.135 мкМ −1 см −1 и εHbO = 1,791 мкМ −1 см −1 для длины волны 830 нм и εHbO = 0,95 мкМ −1 см −1 и εHbO = 4,93 мкМ -1 см -1 для длины волны 690 нм, рассчитано с использованием модифицированного закона Бера-Ламберта (MBLL) (Delpy et al., 1988).
В полученном гемодинамическом сигнале присутствовали различные физиологические шумы, и эти шумы характеризовались частотой дыхания 0,2 Гц, частотой сердечных сокращений 0,8 Гц и очень низкочастотными колебаниями при 0.03 Гц (Cui et al., 2010; Naseer, Hong, 2015). Таким образом, был использован фильтр нижних частот Баттерворта 4-го порядка с частотой среза 0,15 Гц (Ye et al., 2009; Hong and Santosa, 2016; Zafar and Hong, 2017) для удаления физиологических шумов, связанных с сердечными сигналами и дыханием. . Кроме того, в программе NIRS-SPM выполнялось условие устранения тренда, чтобы устранить дрейф гемодинамического сигнала (Ye et al., 2009).
Извлечение и классификация признаков
Структура нейромаркетинга на основе CNN
Оценка коммерческих рекламных видеороликов, основанная на когнитивных способностях, является первым шагом в исследовании нейромаркетинга для расшифровки поведения потребителей.Для исследователей нейромаркетинга крайне важно детально расшифровать поведение и уровни предпочтений потребителей. Поэтому в этом исследовании представлен алгоритм искусственного интеллекта, который представляет собой глубокую нейронную сеть, называемую CNN, для классификации и декодирования различных уровней предпочтений, таких как «неприязнь», «так себе» и «нравится». В этом исследовании, в соответствии с церебральными гемодинамическими ответами и концентрацией HbR, HbO изменялся, когда испытуемых стимулировали коммерческими рекламными видеороликами, и, следовательно, для декодирования этих результатов стимуляции была предложена CNN.Структура и процесс декодирования CNN представлены на рисунках 3, 4 соответственно.
Рисунок 3 . Структура сверточной нейронной сети для расшифровки предпочтений потребителей.
Рисунок 4 . Процесс декодирования CNN.
С точки зрения извлечения и классификации CNN, состоящая из нескольких уровней, включая входной, сверточный, полностью связанный и выходной уровни (см. Рисунок 3), используется в качестве автоматического алгоритма для обучения и тестирования наборов данных.Ширина сверточного слоя равна размеру ядра (высоте) х , а размер входных данных свертывается с входными данными. Выходной сигнал i -го фильтра выражается следующим образом:
zi = w · x [i: i + h-1] (1), где w — матрица весов, x [ i : j ] — подматрица входных данных из строк с i до j , а z — это значение результата. Выходной уровень включает в себя три различных выходных уровня: низкий отклик, представленный «неприязнью», средний отклик, обозначаемый «так себе», и высокий отклик — «нравится».По завершении каждой сверточной обработки некоторые операции подвыборки, включая максимальное объединение и выпадение, используются для повышения производительности структуры CNN. Среди этих операций max-pooling используется как общий метод уменьшения размера данных. Чтобы избежать переобучения данных, выпадение используется в качестве шага регуляризации, чтобы игнорировать один или несколько скрытых узлов во время процесса обучения. Кроме того, гиперпараметры, такие как скорость обучения, размер пакета и количество эпох, используются для повышения точности классификации.
Процесс декодирования CNN показан на рисунке 4. Отфильтрованные функции декодирования коммерческой рекламы состоят из трех подпроцедур, которые вводятся в структуры декодирования CNN. Характеристики видео длительностью 15, 30 и 60 секунд используются в качестве входных слоев для построения набора матриц данных декодирования (рисунок 5). В процессах извлечения и классификации сверточные слои обрабатываются трижды, происходит максимальное объединение и выпадение, а полностью связанные операции обрабатываются дважды; все это критические операции декодирования.
Рисунок 5 . Входные данные: HbO (зеленый) и HbR (голубой) всех каналов. Сверточный фильтр использовался для фильтрации входных данных по вертикальной оси.
В случае выделения и классификации каждого отдельного участника классификатор был обучен и протестирован с использованием извлеченных признаков после обработки сигнала. После этапа обучения мы вычислили точность классификации, используя предложенный подход fNIRS на основе CNN. В следующем разделе обсуждаются детали предлагаемой структуры CNN и гемодинамической конверсии.
Предлагаемые структуры сверточных нейронных сетей
В этой статье представлено новое исследование по выявлению поведенческого познания. Предложенная структура CNN использовалась для декодирования различных уровней предпочтений потребителей. В качестве автоматического экстрактора и классификатора структура может обеспечить высокую эффективность классификации. Для обработки входных данных на рисунке 5 показан метод преобразования для представления изменений концентраций HbO и HbR во всех префронтальных каналах, а общий процесс был представлен с использованием матрицы набора данных, чтобы заменить обычную обработку изображений структуры CNN.Матрица M на N представляет входные данные CNN, где M обозначает количество точек в течение периода на основе частоты дискретизации (M = время × частота дискретизации), а период a устанавливается в соответствии с продолжительностью видео ( 15, 30 и 60 с). Количество каналов для HbO и HbR (по 12 каналов) представлено буквой N. Кроме того, рассматриваются три структуры CNN: CNN с одним сверточным слоем (CNN21), двумя сверточными слоями (CNN2) и тремя сверточными слоями ( CNN3). Кроме того, в таблице 2 представлено количество фильтров для каждой структуры CNN.
Таблица 2 . Количество фильтров для каждой структуры CNN.
Обработка входных данных по вертикальной оси включала одномерную свертку (рис. 5). Важнейшие элементы свертки состояли из сверточных фильтров в сверточных слоях и матрицы входного набора данных преобразования церебральной гемодинамики. Для обучения данных в процессе свертки использовался типичный алгоритм (He, 2016) для автоматического обновления значений весов фильтров каждого сверточного слоя, а размер ядра фильтров составлял 3.После каждого сверточного слоя для поиска более полезных данных использовалось максимальное объединение с размером ядра 2, за которым следовал этап исключения с частотой исключения 50%. Первый и второй связанные слои на основе выходного слоя содержали 52 и 26 скрытых узлов соответственно. Выходной уровень имел три узла, соответствующих трем случаям, которые представляли высокую активацию, среднюю активацию и низкую активацию. Они были классифицированы с использованием функции softmax. Чтобы лучше понять структуру CNN, используемую в этом исследовании, в таблице 3 представлены входные и выходные размеры каждого слоя в предлагаемой нами CNN3-a.
Таблица 3 . Размеры входа и выхода CNN 3-a для видео длительностью 15 с.
Для предложенной структуры выпрямленный линейный блок (ReLU), который является нелинейной функцией, был использован для активации всех слоев в структурах CNN, как показано в Nair and Hinton (2010). По сравнению с другими
α (х) = {0, х <0x, x≥0 (2), функция ReLU может улучшить процесс обучения архитектур глубоких нейронных сетей для сложных и крупномасштабных наборов данных, избежать исчезающего градиента и на практике добиться гораздо более быстрой сходимости к оптимальной точке.Кроме того, гиперпараметры CNN, такие как скорость обучения, количество эпох и размер пакета, использовались для обучения всех структур CNN. Эти параметры были выбраны для каждого отдельного участника методом поиска по сетке (таблица 4). В качестве алгоритма оптимизации градиентного спуска применялся Адам, параметры которого β 1 , β 2 и ε были установлены равными 0,9, 0,1 и 10 -8 соответственно (Kingma and Ba, 2015).
Таблица 4 . Гиперпараметры каждой отдельной темы для CNN.
Сверточные фильтры структуры декодирования
Одна идея CNN может различать три различных предпочтения для каждого видео длительности, обновляя значения веса его фильтров в этой работе. Таким образом, чтобы гарантировать производительность фильтров CNN, идентификация различимого входного канала является важной операцией для исследования первого уровня CNN. Прямое и обратное распространение используются для обучения собранных данных. CNN может узнать, как выделить некоторые каналы, содержащие различимые сигналы, с увеличением связанных значений веса из-за взаимодействия между каждым столбцом фильтров.Каждый канал получил входные данные. После обучения данных столбец каждого сверточного фильтра был усреднен, чтобы приблизиться к наиболее различимому каналу. Наконец, канал для всех выборок входных данных с наивысшим значением веса усредненного сверточного фильтра был завершен для визуализации. Вкратце, у каждого сверточного фильтра есть конкретная задача по определению уровней предпочтений. Для каждой конкретной длительности видео его сверточный фильтр декодирования структуры CNN специфичен после обучения.Следующее уравнение используется для вычисления точности классификации уровня предпочтения для каждой длительности видео.
P = ND + NS + NLNT × 100% (3), где N D , N S и N L — это числа образцов «неприязнь», «так себе» и «нравится» после процесса. идентификатора CNN соответственно, а N T — количество выборок входных данных.Точность классификации определяется как P для каждого испытания, а окончательная точность классификации достигается усреднением результатов всех испытаний. Тот же принцип используется для достижения точности классификации результатов попарной классификации на основе разных полов.
Визуализация элементов извлечения
Некоторые методы экстракции и классификации, использованные в предыдущих исследованиях, не достигли высокой эффективности классификации большого количества образцов.Следовательно, в этом исследовании для достижения высокой эффективности классификации предложенная структура fNIRS на основе CNN использовалась для извлечения и классификации признаков из-за ее преимущества автоматического выделения признаков. В дополнение к представлению CNN, подход визуализации использовался для демонстрации результатов декодирования различных предпочтений и полов. Во время обработки данных трудно визуализировать многомерные данные при классификации предпочтений. Таким образом, анализ главных компонентов (PCA) был использован для уменьшения количества и размерности данных.
В этом исследовании визуализация извлеченных признаков позволяет анализировать гемодинамическую активацию и расшифровывать различные предпочтения потребителей. Результаты визуализации отображаются с использованием первого и двух основных компонентов PCA. Процедура визуализации характеристик сигнала показана в следующем разделе.
Области интереса для предпочтений
Карта значений t представляет собой более интуитивно понятный подход для отображения активации мозга в соответствии с данными fNIRS.В этом исследовании значения t были вычислены с использованием функции robustfit , доступной в Matlab, в сравнении с ожидаемым гемодинамическим ответом. Значение t определяли для коэффициента активации коры головного мозга человека, если форма ответа HbO ближе к ожидаемому гемодинамическому ответу. Значение t crt зависит от степеней свободы (номер: N −1), если канал с вычисленным значением t больше, чем t crt , канал определяется как активный (Khan et al., 2014). Области, представляющие интерес для каждого предмета, исследуются с помощью карт.
Результаты
Поведенческие результаты
На рисунке 6 показаны результаты поведенческого анализа с использованием двух методов, называемых тестом независимой выборки t и односторонним дисперсионным анализом для различных типов видео. Две независимые переменные, а именно продолжительность воспроизведения видео и бренд продукта, используются для анализа предпочтений участников. Все рекламные ролики делятся на шесть типов на основе этих переменных, включая 15 s-Coca, 15 s-Pepsi, 30 s-Coca, 30 s-Pepsi, 60 s-Coca, 60 s-Pepsi соответственно.Независимый образец t- тест был использован для анализа продолжительности воспроизведения видео и бренда продукта для двух переменных (рисунки 6A, C). Односторонний дисперсионный анализ был использован для анализа эффектов шести различных типов стимуляции с использованием двух независимых переменных (рисунки 6B, D). Результаты показали, что продолжительность воспроизведения 30-секундных рекламных роликов Coca [т. Е. Среднее (M) = 7,13, стандартное отклонение (SD) = 0,835, p = 0,043] была значительно выше, чем у 30-секундных рекламных роликов Pepsi. видео (т.е., M = 6,75, SD = 1,035, p = 0,043). Продолжительность воспроизведения 60-секундных рекламных роликов Pepsi (M = 6.50, SD = 1.195, p = 0,045) была немного выше, чем у 60 коммерческих видеороликов s-Coca (M = 6.25, SD = 1.035, p = 0,045). Кроме того, что касается предпочтений товарных брендов, 30 рекламных видеороликов s-Coca (M = 7,38, SD = 1,061, p = 0,035) были больше, чем 30 рекламных видеороликов s-Pepsi (M = 7,13, SD = 0,641, ). p = 0,035), 60 рекламных роликов s-Coca (M = 6.50, SD = 1,069, p = 0,037) были значительно выше, чем 60 коммерческих видеороликов S-Pepsi (M = 6,13, SD = 0,835, p = 0,037). С другой стороны, продолжительность воспроизведения 30-секундных рекламных видеороликов Coca-Cola (M = 7,13, SD = 0,835) была значительно выше, чем оценки предпочтений для других типов: 15 видеороликов s-Coca (M = 6,50, SD = 0,925, p = 0,012), 15 видеороликов s-Pepsi (M = 6,38, SD = 0,916, p = 0,002), 30 видеороликов s-Pepsi (M = 6,75, SD = 1.035, p = 0,000), 60 видеороликов s-Coca (M = 6,25, SD = 1,035, p = 0,000), 60 видеороликов s-Pepsi (M = 6,50, SD = 1,195, p = 0,002) . С точки зрения предпочтений бренда продукта 30 рекламных видеороликов s-Coca cola (M = 7,38, SD = 1,061) также были значительно выше, чем остальные типы: 15 видеороликов s-Coca (M = 6,63, SD = 1,061). , p = 0,000), 15 видеороликов s-Pepsi (M = 6,51, SD = 0,744, p = 0,001), 30 видеороликов s-Pepsi (M = 7,13, SD = 0.641, p = 0,005), 60 видеороликов s-Coca (M = 6,50, SD = 1,069, p = 0,000), 60 видеороликов s-Pepsi (M = 6,13, SD = 0,835, p = 0,012) .
Рисунок 6 . Статистические результаты поведенческих данных: (A, B) по независимой выборке, t -тест и (C, D) с помощью однофакторного дисперсионного анализа. * p <0,05.
Классификация предпочтений в результатах визуализации
Точность классификации каждого участника для видеороликов разной продолжительности использовалась для получения общей точности классификации каждого участника путем усреднения результатов по каналам и испытаниям (рис. 7).Средние значения точности классификации видео длительностью 15, 30 и 60 секунд составляют 84,3, 87,9 и 86,4% соответственно. Среди них точность классификации 30-секундного видео самая высокая. По результатам измерения трех различных предпочтений восьми участников, участник 7 достиг наивысшей точности классификации 89,2 и 90,6% для видео длительностью 15 и 30 секунд, соответственно, а участник 5 достиг наивысшей точности 89,8% для видео 60 секунд. Для 30-секундного видео точность классификации всех участников превышает 85% и более четко соответствует этим рекламным решениям.Более того, по сравнению с другими длительностями (рис. 8), точность классификации 30-секундного видео является наивысшей, когда количество отсчетов> 80, а CNN достигает точности> 83,5 и 90,6% с 80 отсчетами и 200 отсчетами соответственно. . По мере увеличения количества сэмплов для видео разной продолжительности повышение точности классификации постепенно снижается и достигает 90%.
Рисунок 7 . Средняя точность классификации отдельных предметов за разную продолжительность.
Рисунок 8 . Средняя точность классификации всех предметов на основе разного количества выборок и разной продолжительности.
Что касается характеристик классификации (рисунки 7, 11 и таблица 5) на основе пола, было замечено, что предпочтения «нравится» и «не нравится» представляют более высокую эффективность классификации для участников женского и мужского пола по сравнению с другими комбинациями, такими как « нравится против «такой-то» и «не нравится» против «так-то». Более того, мужчины-участники отдали предпочтение коммерческой рекламе, и показатели классификации «нравится» и «не нравится» были лучше.Участники 1, 4, 5 и 7 показывают лучшие результаты визуализации для классификации различных уровней предпочтений после стимулирования коммерческой рекламы.
Таблица 5 . Предпочтение результатов попарной классификации для разных полов.
Качество ROI в префронтальной коре
На рисунке 9 показаны различные карты активации коры головного мозга восьми субъектов для коммерческих видеороликов о 15 s-Coca, 15 s-Pepsi, 30 s-Coca, 30 s-Pepsi, 60 s-Coca, 60 s-Pepsi, которые взяты из префронтальная кора.Области интереса (ROI) для разных видео оказались разными. Усредненные карты активации мозга разных полов для восьми субъектов были получены на рисунке 9 на основе данных ROI каждого испытания. На обоих рисунках 9A, B были усредненные женские тематические карты и усредненные мужские тематические карты, основанные на шести различных типах видео, соответственно. На женской карте видео 15 s-Coca, 15 s-Pepsi и 30 s-Coca показали больше каналов активации, чем другие. Среди них каналы 8, 9, 10 и каналы 1, 2, 3, 4 были активированы, когда были показаны 15 видео s-Coca и 30 s-Coca, соответственно.Каналы 6, 7, 8, 10, 11 и 12 были активированы при просмотре видео 15 s-Coca. На мужской карте видео 15 s-Coca, 15 s-Pepsi и 30 s-Coca также показали большую активацию, чем другие: каналы 1, 2, 3, 4, 5, 6 и 10 были активированы при просмотре 15 видео s-Coca, каналы 1, 2, 3, 4, 8 и 10 были активированы, когда было показано видео 15 s-Pepsi, каналы 1, 2, 4 и 10 были активированы при просмотре видео 30 s-Pepsi . Из приведенного выше описания считается, что видеоролики 15 s-Coca, 15 s-Pepsi, 30 s-Coca показали больше каналов активации как для женщин, так и для мужчин.Результаты ROI также показывают, что рекламные видеоролики с меньшей продолжительностью могут генерировать больше областей интереса, чем долгосрочное стимулирование. Кроме того, значительная асимметрия ROI была получена от префронтальной коры.
Рисунок 9 . Усредненные карты активации мозга из шести разных видео для разных полов. (A) Усредненные карты женских субъектов. (B) Усредненные карты субъектов мужского пола.
Обсуждение
Точность классификации нейромаркетинга на основе CNN
Для определения точности классификации CNN и оценки эффективности классификации прогнозной модели (Arlot and Celisse, 2009; Zheng et al., 2019), в этом исследовании использовался 8-кратный метод перекрестной проверки для оценки прогнозирующей модели с точки зрения эффективности классификации. Первый доступ состоит в том, чтобы разделить собранные данные на 8 частей во время процесса, и идентичное количество входных данных состоит из каждой кратности. Затем 1-кратная кратность используется в качестве набора тестов для оценки производительности модели, а остальные кратности используются в качестве обучающих наборов для обучения предлагаемой модели (рис. 10). Наконец, к выбранным тестовым и обучающим выборкам применяется процедура классификации.Каждый из 8-кратных показателей сыграл важную роль в процессах тестирования и обучения, и соответствующие точности, полученные из отдельных наборов тестирования, были усреднены для оценки производительности модели. Мы попытались различить три случая предпочтений, включая высокую, среднюю и низкую активацию, и определили их как три различных предпочтения потребителей: «нравится», «так-то» и «не нравится». Высокая точность классификации, структуры CNN – fNIRS были применены для классификации общих характеристик сигнала.
Рисунок 10 . Процедура перекрестной проверки.
В частности, на рисунке 7 показана точность классификации отдельных участников, и, как и ожидалось, результаты, полученные с использованием структур CNN, показывают более высокую точность классификации по сравнению с традиционными методами. Средние значения точности классификации видео длительностью 15, 30 и 60 секунд составляют 84,3, 87,9 и 86,4% соответственно. Среди них точность классификации 30-секундных видеороликов была самой высокой.По результатам измерения трех различных предпочтений восьми участников, участник 7 достиг наивысшей точности 89,2 и 90,6% для видео длительностью 15 и 30 секунд соответственно. Более того, участник 5 показывает самую высокую точность 89,8% для 60 s-video. Для достижения высокой производительности классификации для видео с разной продолжительностью способность CNN к автоматическому обучению для обработки входного набора данных имела решающее значение для достижения превосходного классификатора, а значения веса сверточных фильтров были обновлены с использованием присущих сверточных шаблонов.
Размер обучающего набора данных как критический элемент повлиял на производительность обучения, и это особенно верно для CNN и других искусственных алгоритмов. Кроме того, чтобы изучить взаимосвязь между размером набора данных и точностью классификации, были получены средние значения точности классификации всех участников. Для оценки эффективности классификации CNN использовался 8-кратный метод перекрестной проверки. Было замечено, что для всех типов точности классификации при разной продолжительности эффективность классификации увеличивалась с увеличением количества выборок в наборе данных.На рисунке 8 показана точность классификации CNN для разного количества выборок. Более того, по сравнению с другими длительностями, точность классификации 30-секундного видео является наивысшей, когда количество отсчетов> 80. Кроме того, CNN обеспечивает точность> 83,5 и 90,6% для 80 и 200 образцов соответственно. С увеличением количества выборок также улучшаются характеристики классификации предпочтений. Таким образом, для дальнейшей классификации различных предпочтений и принятия решений потребителями следует учитывать большее количество участников и количество выборок.
Визуализация различных уровней предпочтений с использованием CNN
Чтобы декодировать различные уровни предпочтений потребителей с помощью fNIRS на основе CNN и лучше понять результаты декодирования и производительность извлечения признаков, мы визуализировали три случая высокой, средней и низкой активации (определяемых как разные уровни предпочтений: «как , »« Так себе »и« не нравится »соответственно). В частности, три случая были визуализированы с помощью сверточной обработки. На рисунке 11 показаны результаты PCA по первому и второму принципам.Результаты участников-женщин 1 и 4, а также участников-мужчин 5 и 7 показывают, что извлеченные с помощью сверточных фильтров признаки лучше различимы на разных уровнях активации для разных коммерческих рекламных объявлений, и результаты сравниваются по полу.
Рисунок 11 . Классификация предпочтений: визуализация сигналов гемодинамического ответа с использованием CNN для разных полов и продолжительности. (А) Женщина (участница 4): 15 сек-реклама. (В) Мужской (участник 7): 15 сек-реклама. (В) Женщина (участница 1): 30 сек-реклама. (D) Мужской (участник 7): 30 сек-реклама. (E) Женщина (участница 1): 60 сек-реклама. (Ж) Мужской (участник 5): 60 сек-реклама.
Классификационные характеристики (рисунки 7, 11) показали, что в случае участников мужского пола предпочтения «нравится» и «не нравится» представляют более высокую эффективность классификации по сравнению с другими комбинациями, такими как «нравится» или «нравится» или «не нравится».«Так себе» и «не нравится» vs. «так себе». В частности, с помощью fNIRS на основе CNN легко классифицировать широкий диапазон гемодинамических реакций. Напротив, в случае женщин-участниц визуализация различных предпочтений потребителей показывает хорошие результаты классификации. По сравнению с участниками-женщинами существуют определенные различия в уровнях принятия решений участниками-мужчинами. Среди них мужчины-участники имеют более целенаправленные предпочтения в отношении коммерческой рекламы, и показатели классификации «нравится» и «не нравится» были лучше.
Для декодирования различных уровней предпочтений потребителей в нейромаркетинге используется новый автоматический метод, который включает алгоритм CNN и процесс декодирования, чтобы исследовать поведение и намерения потребителей. По сравнению с другими общими методами извлечения и классификации признаков, в этом исследовании метод fNIRS на основе CNN демонстрирует превосходные характеристики классификации и визуализации. В будущей работе следует рассмотреть другие структуры CNN и оптимизированные процессы декодирования для повышения точности классификации.
Активация префрональной коры в настройках
Область префронтальной коры (ПФК) является важной частью всей коры головного мозга, и она участвует в принятии решений, регулировании социального поведения, планировании сложного когнитивного поведения и т. Д. В этой работе префронтальная кора для активации карт ( На рисунке 9) были представлены активированные каналы, когда участников стимулировали различными типами коммерческих видео. С точки зрения активированных карт, по сравнению с правой областью PFC, левая и центральная области PFC имели более высокую активацию коры головного мозга, когда видео 15 s-Coca, 30 s-Coca и 30 s-Pepsi воспроизводились перед участниками женского пола.В остальном другие типы видео показали в основном схожую активацию в сравниваемых областях PFC. С другой стороны, судя по карте активации участников-мужчин, видео 15 s-Pepsi, 30 s-Coca и 30 s-Pepsi демонстрируют значительно более высокую активацию в левой и центральной области PFC по сравнению с правой. область, край. Кроме того, видео 60 s-Coca и 60 s-Pepsi имеют немного более высокую активацию, за исключением видео 15 s-Coca. Сделан вывод, что левая и центральная области PFC играют решающую роль в принятии решений, поведении, связанном с предпочтениями, и позитивном поведенческом познании при демонстрации привлекательных коммерческих видеороликов.
Ограничения и перспективы на будущее
В этом исследовании количество участников (восемь участников) в процессе обучения и тестирования структур CNN было меньше, чем реальное количество уровней предпочтения классификации. Что касается познания поведения потребителей, многие факторы воздействия вызывают изменения в принятии решений потребителями, и эксперимент был разработан и разработан без каких-либо изменений в окружающей среде. Для решения этих проблем в этом эксперименте должно быть задействовано большое количество участников для оптимизации модели глубокой нейронной сети и дальнейшего повышения стабильности и универсальности этой модели.Посредством постоянной оптимизации модели декодирования может быть достигнута высокая точность классификации для разных потребителей в любой конкретной коммерческой рекламе, и, следовательно, корпоративный маркетинг и маркетинг продаж могут получить более точную информацию о вовлечении продукта.
Заключение
Это исследование продемонстрировало основанную на fNIRS классификацию высокой, средней и низкой активации с использованием CNN в качестве классификатора в области нейромаркетинга и сравнило эффективность классификации результатов визуализации участников эксперимента.Участникам было предложено сосредоточиться на коммерческой рекламе разной продолжительности (15, 30, 60 с), отображаемой на мониторе компьютера. Высокая, средняя и низкая активация, которые назывались разными уровнями предпочтений: «нравится», «так себе» и «не нравится», были классифицированы с использованием CNN вместе с различными характеристиками, такими как среднее значение, пик , наклон, дисперсия, эксцесс и асимметрия. По результатам измерения трех разных уровней предпочтений восьми участников, превосходная точность классификации составляет 87.Наблюдалось 9% для 30-секундного рекламного ролика по сравнению с роликами другой продолжительности. Производительность классификации участника 7 показала наивысшую точность 89,2 и 90,6% для видео длительностью 15 и 30 секунд, соответственно, а участник 5 достиг наивысшей точности классификации 89,8% для видео 60 секунд. По результатам визуализации классификации было отмечено, что участники-мужчины имели целевые предпочтения в отношении коммерческой рекламы по сравнению с участниками-женщинами, и показатели классификации «нравится» и «не нравится» были лучше.Результаты fNIRS на основе CNN, которые демонстрируют хорошие характеристики классификации, указывают на применимость BCI в нейромаркетинге, которые могут быть использованы в практической разработке систем BCI.
Поскольку эффективность классификации является критическим фактором при расшифровке предпочтений потребителей, а о превосходстве CNN как классификатора высшего качества над другими традиционными методами сообщалось в других публикациях, мы планируем оптимизировать производительность систем нейромаркетинга на основе CNN. путем применения различных глубоких нейронных сетей и разработки новых подходов в отношении гибридных методов визуализации, таких как сочетание электроэнцефалографии с fNIRS.
Заявление о доступности данныхНаборы данных, представленные в этой статье, недоступны, потому что наборы данных, созданные для этого исследования, доступны по запросу соответствующему автору. Запросы на доступ к наборам данных следует направлять по адресу [email protected] (Кеум-Шик Хонг).
Заявление об этике
Исследования с участием людей были рассмотрены и одобрены институциональным наблюдательным советом Пусанского национального университета. Пациенты / участники предоставили письменное информированное согласие на участие в этом исследовании.
Авторские взносы
KQ провел обработку данных и написал первый черновик рукописи. RH участвовал в сборе экспериментальных данных. K-SH предложила теоретические аспекты текущего исследования, исправила рукопись и контролировала весь процесс, ведущий к созданию рукописи. Все авторы внесли свой вклад в статью и одобрили представленную версию.
Финансирование
Это исследование было поддержано Национальным исследовательским фондом (NRF) Кореи под эгидой Министерства науки и информационных технологий Республики Корея (грант №NRF- 2020R1A2B5B03096000).
Конфликт интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Список литературы
Абибуллаев Б., Ан Дж. (2012). Классификация гемодинамических ответов лобной коры во время когнитивных задач с использованием вейвлет-преобразований и алгоритмов машинного обучения. Med. Англ. Phys . 34, 1394–1410.DOI: 10.1016 / j.medengphy.2012.01.002
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ансари А. Х., Чериан П. Дж., Кайседо А., Наулаерс Г., Де Вос М. и Ван Хаффель С. (2019). Обнаружение неонатальных припадков с использованием глубоких сверточных нейронных сетей. Внутр. J. Neural Syst . 29: 1850011. DOI: 10.1142 / S01218500119
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Арлот С., Селисс А. (2009). Обзор процедур перекрестной проверки для выбора модели. Stat. Surv . 4, 40–79. DOI: 10.1214 / 09-SS054
CrossRef Полный текст | Google Scholar
Бирбаумер Н., Ганаим Н., Хинтербергер Т., Иверсен И., Кочубей Б., Кублер А. и др. (1999). Орфографическое устройство для парализованных. Природа 398, 297–298. DOI: 10.1038 / 18581
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Бланкерц Б., Дорнхеге Г., Крауледат М., Мюллер К. Р. и Курио Г. (2007). Неинвазивный интерфейс мозг-компьютер Берлин: быстрое достижение эффективных результатов у неподготовленных субъектов. NeuroImage 37, 539–550. DOI: 10.1016 / j.neuroimage.2007.01.051
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Buch, E., Weber, C., Cohen, L.G., Braun, C., Dimyan, M.A., Ard, T., et al. (2008). Подумайте, чтобы двигаться: система нейромагнитного интерфейса мозг-компьютер (BCI) для хронического инсульта. Инсульт 39, 910–917. DOI: 10.1161 / STROKEAHA.107.505313
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Баттфилд, А., Феррез, П. В., и Миллан, Дж. Р. (2006). На пути к надежному BCI: потенциальные ошибки и онлайн-обучение. IEEE Trans. Neural Syst. Rehabil. Eng . 14, 164–168. DOI: 10.1109 / TNSRE.2006.875555
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Чераволо М. Г., Фабри М., Фаттобене Л., Полонара Г. и Раггетти Г. (2019). Наличные, карта или смартфон: нейронные корреляты способов оплаты. Фронт. Neurosci . 13: 1188. DOI: 10.3389 / fnins.2019.01188
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Чаудхари, У., Ся, Б., Сильвони, С., Коэн, Л. Г., и Бирбаумер, Н. (2017). Коммуникация на основе интерфейса мозг-компьютер в полностью заблокированном состоянии. ПЛоС Биол . 15: e1002593. DOI: 10.1371 / journal.pbio.1002593
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ченг, М., Гао, Х. Р., Гао, С. Г., и Сюй, Д. Ф. (2002). Разработка и реализация интерфейса мозг-компьютер с высокой скоростью передачи данных. IEEE Trans. Биомед. Eng . 49, 1181–1186. DOI: 10.1109 / TBME.2002.803536
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Цуй, X., Брей, С., и Рейсс, А. Л. (2010). Улучшение сигнала функциональной ближней инфракрасной спектроскопии (NIRS) на основе отрицательной корреляции между динамикой оксигенированного и деоксигенированного гемоглобина. NeuroImage 49, 3039–3046. DOI: 10.1016 / j.neuroimage.2009.11.050
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Дельпи, Д. Т., Коуп, М., ван дер Зи, П., Арридж, С., Рэй, С., и Вятт, Дж. (1988). Оценка длины оптического пути через ткань по прямым измерениям времени пролета. Phys. Med. Биол. 33, 1433–1442. DOI: 10.1088 / 0031-9155 / 33/12/008
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Дорнхеге, Г. (2007). К взаимодействию мозг-компьютер . Кембридж, Массачусетс: MIT Press.
Google Scholar
Эдит Г., Смит Л. В. М. и Нейенс П. К. (2006). Эффект привлекательности рекламы: 10-летняя перспектива. J. Advert. Res . 46, 73–83. DOI: 10.2501 / S0021849
0089CrossRef Полный текст | Google Scholar
Fazli, S., Mehnert, J., Steinbrink, J., Curio, G., Villringer, A., Müller, K. R., et al. (2012). Повышенная производительность за счет гибридного интерфейса мозг-компьютер NIRS-EEG. NeuroImage 59, 519–529. DOI: 10.1016 / j.neuroimage.2011.07.084
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Фидерер, Л. Д. Дж., Фёлькер, М., Ширрмейстер, Р.Т., Бургард В., Бёдекер Дж. И Болл Т. (2019). Гибридный интерфейс мозг-компьютер для роботов, соответствующих требованиям человека: получение непрерывных субъективных оценок с глубокой регрессией. Фронт. Нейроробот. 13:76. DOI: 10.3389 / fnbot.2019.00076
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Фоекенс, Э. У., Лифланг, П. С. Х. и Уиттинк, Д. Р. (1997). Иерархическая модель в сравнении с другими моделями доли рынка для рынков с большим количеством позиций. J. Market Res . 14, 359–378.DOI: 10.1016 / S0167-8116 (97) 00017-7
CrossRef Полный текст | Google Scholar
Фурлан Ф., Рубио Э., Сосса Х. и Понсе В. (2020). Детекторы на основе CNN на планетных средах: оценка производительности. Фронт. Нейроробот. 14: 5
. DOI: 10.3389 / fnbot.2020.5
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Джустиниани Дж., Николье М., Тети Майер Дж., Шабин Т., Массе К., Гальмес Н. и др. (2020). Поведенческие и нейронные аргументы мотивационного влияния на принятие решений в условиях неопределенности. Фронт. Neurosci . 14: 583. DOI: 10.3389 / fnins.2020.00583
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Гроссберг, С. (2020). Путь к объяснимому ИИ и автономному адаптивному интеллекту: глубокое обучение, адаптивный резонанс и модели восприятия, эмоций и действий. Фронт. Нейроробот. 14:36. DOI: 10.3389 / fnbot.2020.00036
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хан, С.-Х., Хван, Х.-J., Lim, J.-H., и Im, C.-H. (2018). Оценка добровольного участия пользователей во время нейрореабилитации с использованием функциональной ближней инфракрасной спектроскопии: предварительное исследование. J. Neuroeng. Rehabili. 15:27. DOI: 10.1186 / s12984-018-0365-z
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Он, К. М. (2016). «Глубокое остаточное обучение для распознавания изображений», в Proc. IEEE Conf. по компьютерному зрению и распознаванию образов (Лас-Вегас, Невада), 770–778.
Google Scholar
Хива С., Ханава К., Тамура Р., Хатисука К. и Хироясу Т. (2016). Анализ функций мозга по предметной классификации данных функциональной ближней инфракрасной спектроскопии с использованием сверточного анализа нейронных сетей. Comput. Intell. Neurosci . 2016: 1841945. DOI: 10.1155 / 2016/1841945
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Hong, K.-S., Naseer, N., and Kim, Y.-H. (2015). Классификация сигналов префронтальной и моторной коры для трехклассового fNIRS-BCI. Neurosci. Lett . 587, 87–92. DOI: 10.1016 / j.neulet.2014.12.029
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Hong, K.-S., and Pham, P.-T. (2019). Управление аксиально движущимися системами: обзор. Внутр. J. Cont. Авто. Syst . 17, 2983–3008. DOI: 10.1007 / s12555-019-0592-5
CrossRef Полный текст | Google Scholar
Хонг, К.-С., и Сантоза, Х. (2016). Расшифровка четырех различных категорий звуков в слуховой коре с помощью функциональной спектроскопии в ближнем инфракрасном диапазоне. Слушайте. Res . 333, 157–166. DOI: 10.1016 / j.heares.2016.01.009
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ху, Ф., Ву, К., Ли, Ю., Сюй, В., Чжао, Л., и Сун, К. (2020). Любовь с первого взгляда, но не после глубоких размышлений: влияние сексуально привлекательной рекламы на предпочтения продукта. Фронт. Neurosci . 14: 465. DOI: 10.3389 / fnins.2020.00465
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ху, Х., Чжуан, К., Ван, Ф., Лю, Ю., Им, С.-Х., и Чжан, Д. (2019). Свидетельство fNIRS для распознавания различных положительных эмоций. Фронт. Гм. Neurosci. 13: 120. DOI: 10.3389 / fnhum.2019.00120
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Джанани А., Сасикала М., Чхабра Х., Шаджил Н. и Венкатасубраманян Г. (2020). Исследование глубокой сверточной нейронной сети для классификации сигналов fNIRS изображений движения для приложений BCI. Биомед. Signal Proc. Продолж. 62: 102133. DOI: 10.1016 / j.bspc.2020.102133
CrossRef Полный текст | Google Scholar
Канг, Дж. Х., Ким, С. Дж., Чо, Ю. С., и Ким, С.-П. (2015). Модуляция альфа-колебаний ЭЭГ человека с предпочтением лица. PLOS ONE 10: e0138153. DOI: 10.1371 / journal.pone.0138153
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Канг, С.С., Макдональд, А.В., Чафи, М.В., Им, Ч.-Х., Бернат, Э.М., Дэвенпорт, Н. Д. и др. (2018). Аномальная корковая нервная синхронизация во время рабочей памяти при шизофрении. Clin. Neurophysiol. 129, 210–221. DOI: 10.1016 / j.clinph.2017.10.024
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Хан, М. Дж., Хонг, М. Дж., И Хонг, К.-С. (2014). Расшифровка четырех направлений движения с использованием гибридного мозг-компьютерного интерфейса НИРС-ЭЭГ. Фронт. Гм. Neurosci . 8: 244. DOI: 10.3389 / fnhum.2014.00244
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Кхоа, Т.К. Д. и Накагава М. (2008). Функциональный ближний инфракрасный спектроскоп для задач познания мозга с помощью вейвлет-анализа и нейронных сетей. Внутр. J. Biol. Med. Sci . 1, 28–33. DOI: 10.5281 / zenodo.1082245
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Kim, H.-H., Jo, J.-H., Teng, Z., and Kang, D.-J. (2019). Обнаружение текста с помощью глубокой нейросетевой системы на основе перекрывающихся меток и иерархической сегментации карт функций. Внутр. J. Cont. Авто.Syst . 17, 1599–1610. DOI: 10.1007 / s12555-018-0578-8
CrossRef Полный текст | Google Scholar
Kim, S.-H., and Choi, H.-L. (2019). Сверточная нейронная сеть для отслеживания нескольких целей на основе монокулярного зрения. Внутр. J. Cont. Авто. Syst . 17, 2284–2296. DOI: 10.1007 / s12555-018-0134-6
CrossRef Полный текст | Google Scholar
Ким Т. Ю., Ким Б. С., Парк Т. К. и Йео Ю. К. (2018). Разработка схемы управления на основе прогнозной модели для процесса жидкого карбонатного топливного элемента (MCFC). Внутр. J. Cont. Авто. Syst. 16, 791–803. DOI: 10.1007 / s12555-016-0234-0
CrossRef Полный текст | Google Scholar
Кингма Д. и Ба Дж. (2015). Адам: метод стохастической оптимизации. arXiv. arXiv: 1412.6980v9.
Google Scholar
Котлер П. (2000). Управление маркетингом. Millenium Edn (Глава 10). Река Аппер Сэдл, штат Нью-Джерси: Prentice Hall.
Kwon, J., Shin, J., and Im, C.-H. (2020). На пути к компактному гибридному интерфейсу мозг-компьютер (BCI): оценка производительности мультиклассовых гибридных BCI EEG-fNIRS с ограниченным количеством каналов. PLOS ONE 15: e0230491. DOI: 10.1371 / journal.pone.0230491
PubMed Аннотация | CrossRef Полный текст | Google Scholar
ЛаФлер, К., Кэссиди, К., Доуд, А., Шейдс, К., Рогин, Э., и Хе, Б. (2013). Управление квадрокоптером в трехмерном пространстве с помощью неинвазивного интерфейса мозг-компьютер на основе изображений движения. J. Neural Eng . 10: 046003. DOI: 10.1088 / 1741-2560 / 10/4/046003
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Лал, Т.Н., Хинтербергер Т., Видман Г. и Тангерманн М. (2004). «Методы инвазивного взаимодействия мозга человека с компьютером», в конференции Conf. по системам обработки нейронной информации (NIPS) (Ванкувер, Британская Колумбия), 737–744.
Google Scholar
Лэвидж Р. Дж. И Штайнер Г. А. (1961). Модель для прогнозных измерений эффективности рекламы. J. Рынок . 25, 59–62. DOI: 10.1177 / 002224296102500611
CrossRef Полный текст | Google Scholar
Ли, Н., Бродерик, А., Чемберлен, Л. (2007). Что такое «нейромаркетинг»? Обсуждение и повестка дня для будущих исследований. Внутр. Дж. Психофизиол . 63, 199–204. DOI: 10.1016 / j.ijpsycho.2006.03.007
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ли, С. Дж., Чой, Х., и Хван, С. С. (2020). Оценка глубины в реальном времени с использованием повторяющейся CNN с разреженными сигналами глубины для системы захвата. Внутр. J. Cont. Авто. Syst . 18, 206–216. DOI: 10.1007 / s12555-019-0350-8
CrossRef Полный текст | Google Scholar
Леминг, М., Мануэль Горриз, Дж., И Саклинг, Дж. (2020). Ансамбль глубокого обучения на больших, смешанных наборах данных фМРТ при аутизме и других задачах. Внутр. J. Neural Syst . 30: 2050012. DOI: 10.1142 / S01220500124
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Leuthardt, E.C., Schalk, G., Wolpaw, J.R., Ojemann, J.G., и Moran, D.W. (2004). Интерфейс мозг-компьютер с использованием электрокортикографических сигналов у людей. J. Neural Eng . 1, 63–71. DOI: 10.1088 / 1741-2560 / 1/2/001
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ляо, В. Ю., Чжан, Ю., и Пэн, X. З. (2019). Нейрофизиологический эффект воздействия сплетен на одобрение продукта и готовность платить. Нейропсихология 132: 107123. DOI: 10.1016 / j.neuropsychologia.2019.107123
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Лю Г., Чжоу В. и Гэн М. (2020). Автоматическое обнаружение захвата на основе S-преобразования и глубокой сверточной нейронной сети. Внутр. J. Neural Syst . 30: 1950024. DOI: 10.1142 / S01219500242
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Лун, X. М., Ю, З., Чен, Т., Ван, Ф., и Хоу, Ф. (2020). Упрощенный метод классификации CNN для MI-EEG через сигналы пар электродов. Фронт. Гм. Neurosci. 14: 338. DOI: 10.3389 / fnhum.2020.00338
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ма, К., Абдельджелил, Х. М., и Ху, Л.(2019). Влияние потребительского этноцентризма и культурной близости на предпочтения бренда: доказательство потенциала, связанного с событием (ERP). Фронт. Гм. Neurosci. 13: 220. DOI: 10.3389 / fnhum.2019.00220
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Манзанера, О. М., Мелес, С. К., Лендерс, К. Л., Ренкен, Р. Дж., Пагани, М., Арнальди, Д., и др. (2019). Масштабируемое моделирование подпрофиля и сверточные нейронные сети для идентификации болезни Паркинсона в данных трехмерной ядерной визуализации. Внутр. J. Neural Syst. 29: 1950010. DOI: 10.1142 / S01219500102
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Маттила А.С. (2000). Роль повествований в рекламе экспериментальных услуг. J. Serv. Res . 3, 35–45. DOI: 10.1177 / 109467050031003
CrossRef Полный текст | Google Scholar
Месленый, Р. Дж., Буза, К., Виднянский, З. (2017). Классификация на основе функциональной связности фМРТ в состоянии покоя с использованием архитектуры сверточной нейронной сети. Фронт. Нейроинформ . 11:61. DOI: 10.3389 / fninf.2017.00061
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Могими С., Хушки А., Пауэр С. Д., Гергерян А. М., Чау Т. (2012). Автоматическое обнаружение префронтальной корковой реакции на эмоционально оцененную музыку с помощью многоканальной спектроскопии в ближнем инфракрасном диапазоне. J. Neural Eng . 9: 026022. DOI: 10.1088 / 1741-2560 / 9/2/026022
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Луна, Дж., Ким, Х., и Ли, Б. (2018). Инвариантная к точке обзора 3D-классификация мобильных роботов с использованием сверточной нейронной сети. Внутр. J. Cont. Авто. Syst. 16, 2888–2895. DOI: 10.1007 / s12555-018-0182-y
CrossRef Полный текст | Google Scholar
Наир В., Хинтон Г. Э. (2010). «Выпрямленные линейные блоки улучшают ограниченные машины Boltzmann», в Proc. Int. Конф. по машинному обучению (ICML) (Хайфа), 807–814.
Google Scholar
Насир, Н., и Хонг, К.-С. (2015). Интерфейсы мозг-компьютер на основе fNIRS: обзор. Фронт. Гм. Neurosci . 9: 3. DOI: 10.3389 / fnhum.2015.00003
CrossRef Полный текст | Google Scholar
Насир Н., Куреши Н. К., Нури Ф. М. и Хонг К.-С. (2016). Анализ различных методов классификации для двухклассового функционального интерфейса мозг-компьютер на основе ближней инфракрасной спектроскопии. Comput. Intell. Neurosci . 2016: 5480760. DOI: 10.1155 / 2016/5480760
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Neo, П.С.-Х., Тинкер, Дж., И МакНотон, Н. (2020). Конфликт целей, тета ЭЭГ и необъективные экономические решения: роль второй системы негативной мотивации. Фронт. Neurosci . 14: 342. DOI: 10.3389 / fnins.2020.00342
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Pamosoaji, A.K., Piao, M., and Hong, K.-S. (2019). Планирование движения за минимальное время на основе PSO для нескольких транспортных средств с ограничениями по ускорению и скорости. Внутр. J. Cont. Авто. Syst .17, 2610–2623. DOI: 10.1007 / s12555-018-0176-9
CrossRef Полный текст | Google Scholar
Парк, Дж., Ким, Х., Сон, Дж. В., Чой, Дж .-Р. и Ким, С.-П. (2018). Бета-колебания ЭЭГ в височно-теменной области связаны с точностью оценки предпочтений окружающих. Фронт. Гм. Neurosci. 12:43. DOI: 10.3389 / fnhum.2018.00043
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Парра, Л., Альвино, К., Танг, А., Перлмуттер, Б., Юнг, Н., Осман А. и др. (2002). Линейная пространственная интеграция для однократного обнаружения в энцефалографии. NeuroImage 17, 223–230. DOI: 10.1006 / nimg.2002.1212
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Pham, P.-T., and Hong, K.-S. (2020). Динамические модели аксиально движущихся систем: обзор. Нелинейная Дин. 100, 315–349. DOI: 10.1007 / s11071-020-05491-z
CrossRef Полный текст | Google Scholar
Филлипс, Б. Дж., И Маккуорри, Э.Ф. (2010). Повествование и убеждение в модной рекламе. J. Consum. Res. 37, 368–392. DOI: 10.1086 / 653087
CrossRef Полный текст | Google Scholar
Росас-Ромеро, Р., Гевара, Э., Пенг, К., Нгуен, Д. К., Лесаж, Ф., Пулиот, П., и др. (2019). Прогнозирование эпилептических припадков с помощью сверточных нейронных сетей и функциональных сигналов ближней инфракрасной спектроскопии. Комп. Биол. Мед . 111: 103355. DOI: 10.1016 / j.compbiomed.2019.103355
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Сантоза, Х., Hong, M.J., Kim, S.P., и Hong, K.-S. (2013). Снижение шума в сигналах функциональной ближней инфракрасной спектроскопии с помощью независимого компонентного анализа. Rev. Sci. Instrum. 84: 073106. DOI: 10.1063 / 1.4812785
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Сеньор К., Ли Н. и Брейтигам С. (2015). Общество, организации и мозг: построение единой точки зрения когнитивной нейробиологии. Фронт. Гм. Neurosci. 9: 289. DOI: 10.3389 / fnhum.2015.00411
CrossRef Полный текст | Google Scholar
Shan, C.-H., Guo, X.-R., и Ou, J. (2019). Нейронные сети с глубоким дырявым однопостовым треугольником. Внутр. J. Cont. Авто. Syst. 17, 2693–2701. DOI: 10.1007 / s12555-018-0796-0
CrossRef Полный текст | Google Scholar
Shin, J., Kwon, J., Choi, J., and Im, C.-H. (2018). Интерфейс мозг-компьютер для тройной спектроскопии в ближней инфракрасной области с повышенной скоростью передачи информации с использованием изменений префронтальной гемодинамики во время мысленных вычислений, задержки дыхания и состояния покоя. IEEE Access 6, 19491–19498. DOI: 10.1109 / ACCESS.2018.2822238
CrossRef Полный текст | Google Scholar
Стерн, Б. Б. (1994). Классические и виньетки телевизионные рекламные драмы: структурные модели, формальный анализ и потребительские эффекты. J. Consum. Res . 20, 601–615. DOI: 10.1086 / 209373
CrossRef Полный текст | Google Scholar
Thomas, J., Jin, J., Thangavel, P., Bagheri, E., Yuvaraj, R., Dauwels, J., et al. (2020). Автоматическое обнаружение межприступных эпилептических разрядов на электроэнцефалограммах кожи головы с помощью сверточных нейронных сетей. Внутр. J. Neural Syst . 30: 2050030. DOI: 10.1142 / S01220500306
CrossRef Полный текст | Google Scholar
Валериани Д. и Поли Р. (2019). Группы киборгов улучшают распознавание лиц в людных местах. PLoS ONE 14: e0214557. DOI: 10.1371 / journal.pone.0214557
CrossRef Полный текст | Google Scholar
Венцес, Н. А., Диас-Кампо, Дж., И Росалес, Д. Ф. Г. (2020). Нейромаркетинг как инструмент эмоциональной связи между организациями и аудиторией в социальных сетях.Теоретический обзор. Фронт. Психол . 11: 1787. DOI: 10.3389 / fpsyg.2020.01787
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Виллринджер А., Планк Дж., Хок К., Шлейнкофер Л. и Дирнагл У. (1993). Спектроскопия в ближнем инфракрасном диапазоне (NIRS): новый инструмент для изучения гемодинамических изменений во время активации функции мозга у взрослых людей. Neurosci. Lett . 154, 101–104. DOI: 10.1016 / 0304-3940 (93)
-J
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ван, Р.В. Ю., Чанг, Ю. К., Чуанг, С. В. (2016). Спектральная динамика ЭЭГ рекламных роликов: влияние повествования на предпочтение брендового продукта. Sci. Репутация . 6: 36487. DOI: 10.1038 / srep36487
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Вэй, З., Ву, К., Ван, X., Супратак, А., Ван, П., и Го, Ю. (2018). Использование машины опорных векторов на ЭЭГ для оценки воздействия рекламы. Фронт. Neurosci . 12:76. DOI: 10.3389 / fnins.2018.00076
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Ян Д., Хонг, К.-С., Ю, С.Х., и Ким, С.С. (2019). Оценка биомаркеров нейральной дегенерации в префронтальной коре для раннего выявления пациентов с легкими когнитивными нарушениями: исследование fNIRS. Фронт. Гм. Neurosci. 13: 317. DOI: 10.3389 / fnhum.2019.00317
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Yang, T.Y., Lee, D.-Y., Kwak, Y. S., Choi, J. S., Kim, C.J., and Kim, S.-P. (2015). Оценка телевизионных рекламных роликов с использованием нейрофизиологических ответов. J. Phys. Anth . 34:19. DOI: 10.1186 / s40101-015-0056-4
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Йе Д., Чжан Х., Тянь Ю., Чжао Ю. и Сунь З. (2020). Нечеткое скользящее управление спутником с непараллельной траекторией движения с высокой точностью. Внутр. J. Cont. Авто. Syst . 18: 1617–1628. DOI: 10.1007 / s12555-018-0369-2
CrossRef Полный текст | Google Scholar
Ye, J.C., Tak, S., Jang, K.E., Jung, J., and Jang, J.(2009). NIRS-SPM: статистическое параметрическое отображение для ближней инфракрасной спектроскопии. NeuroImage 44, 428–447. DOI: 10.1016 / j.neuroimage.2008.08.036
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Юн, Дж. Х., Чжан, Дж., И Ли, Э.-Дж. (2019). Электрофизиологические механизмы, лежащие в основе зависимых от времени оценок при принятии моральных решений. Фронт. Neurosci . 13: 1021. DOI: 10.3389 / fnins.2019.01021
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Зандер Т.О., и Кот, К. (2011). К пассивным интерфейсам мозг-компьютер: применение технологии интерфейса мозг-компьютер к человеко-машинным системам в целом. J. Neural Eng . 8: 025005. DOI: 10.1088 / 1741-2560 / 8/2/025005
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Чжан, К., Цяо, К., Ван, Л. Ю., Тонг, Л., Цзэн, Ю. и Янь, Б. (2018). Восстановление естественного изображения без ограничений по сигналам фМРТ на основе сверточной нейронной сети. Фронт. Гм.Neurosci. 12: 242. DOI: 10.3389 / fnhum.2018.00242
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Zheng, W., Wang, H.-B., Zhang, Z.-M., Li, N., and Yin, P.-H. (2019). Управление глубоким обучением многослойной нейронной сети с прямой связью с гибридным алгоритмом положения и виртуальной силы для обхода препятствий мобильным роботом. Внутр. J. Cont. Авто. Syst. 17, 1007–1018. DOI: 10.1007 / s12555-018-0140-8
CrossRef Полный текст | Google Scholar
Общее декодирование видимых и воображаемых объектов с использованием иерархических визуальных признаков
Субъекты
В экспериментах участвовали пять здоровых субъектов (одна женщина и четыре мужчины в возрасте от 23 до 38 лет) с нормальным зрением или зрением, скорректированным до нормального.Вместо использования статистических методов для определения размера выборки, размер выборки был выбран в соответствии с предыдущими исследованиями фМРТ с аналогичными поведенческими протоколами. Все испытуемые имели значительный опыт участия в экспериментах фМРТ и были хорошо обучены. Все субъекты предоставили письменное информированное согласие на участие в экспериментах, а протокол исследования был одобрен этическим комитетом ATR.
Визуальные изображения
Изображения были собраны из онлайн-базы данных изображений ImageNet 31 (2011, осенний выпуск), базы данных изображений, в которой изображения сгруппированы в соответствии с иерархией в WordNet 38 .Мы выбрали 200 репрезентативных категорий объектов (синсетов) в качестве стимулов в эксперименте с визуальным представлением изображений. После исключения изображений с шириной или высотой <100 пикселей или соотношением сторон> 1,5 или <2/3 все оставшиеся изображения в ImageNet были обрезаны по центру. По причинам авторского права изображения на рис. 1, 2, 3, 8 и 9 не являются фактическими изображениями из ImageNet, используемыми в наших экспериментах. Исходные изображения заменяются изображениями с аналогичным содержанием для отображения.
Схема эксперимента
Мы провели два типа экспериментов: эксперимент с изображением и эксперимент с изображениями.Все визуальные стимулы повторно проецировались на экран в отверстии сканера fMRI с использованием жидкокристаллического проектора с калибровкой яркости. Данные от каждого субъекта были собраны в течение нескольких сеансов сканирования, продолжавшихся примерно 2 месяца. В каждый день эксперимента проводился один последовательный сеанс не более 2 часов. Испытуемым давали достаточно времени для отдыха между запусками (каждые 3–10 мин) и разрешали сделать перерыв или прекратить эксперимент в любое время.
Эксперимент по представлению изображений состоял из двух различных типов сеансов: сеансов с обучающими изображениями и сеансов с тестовыми изображениями, каждый из которых состоял из 24 и 35 отдельных прогонов (9 мин 54 сек для каждого прогона), соответственно.Каждый запуск содержал 55 блоков стимулов, состоящих из 50 блоков с разными изображениями и пяти случайно перемежающихся блоков повторения, в которых было представлено то же изображение, что и в предыдущем блоке. В каждом блоке стимулов изображение (угол обзора 12 × 12 градусов) мигало с частотой 2 Гц в течение 9 с. Изображения были представлены в центре дисплея с центральной точкой фиксации. Цвет пятна фиксации менялся с белого на красный за 0,5 с до того, как каждый блок стимулов начинал указывать на начало блока.Дополнительные 33- и 6-секундные периоды отдыха были добавлены к началу и концу каждого бега соответственно. Субъекты сохраняли устойчивую фиксацию на протяжении каждого прогона и выполняли одноразовую задачу обнаружения повторения на изображениях, отвечая нажатием кнопки для каждого повторения, чтобы удерживать свое внимание на представленных изображениях (среднее выполнение задания по пяти субъектам; чувствительность = 0,930; специфичность = 0,995). В сеансе тренировочного образа всего 1200 изображений из 150 категорий объектов (по 8 изображений из каждой категории) были представлены только один раз.В сеансе тестового изображения было представлено всего 50 изображений из 50 категорий объектов (по 1 изображению из каждой категории) по 35 раз каждое. Важно отметить, что категории в сеансе тестового изображения не использовались в сеансе тренировочного изображения. Порядок представления категорий был рандомизирован по запускам.
В эксперименте с изображениями испытуемые должны были визуально представить изображения из одной из 50 категорий, которые были представлены в сеансе тестовых изображений эксперимента по представлению изображений.Перед экспериментом 50 образцов изображений из каждой категории были выставлены для тренировки соответствия между именами объектов и визуальными образами, указанными в именах. Эксперимент с изображениями состоял из 20 отдельных прогонов, и каждый прогон содержал 25 блоков изображений (10 мин 39 с для каждого прогона). Каждый блок изображений состоял из 3-секундного периода подсказки, 15-секундного периода изображения, 3-секундного периода оценки и 3-секундного периода отдыха. Дополнительные 33- и 6-секундные периоды отдыха были добавлены к началу и концу каждого бега соответственно.В периоды покоя в центре дисплея отображалось белое пятно фиксации. Цвет пятна фиксации изменился с белого на красный в течение 0,5 с, чтобы указать начало блоков за 0,8 с до начала каждого периода сигнала. Во время периода подсказки слова, описывающие названия 50 категорий, представленных в сеансе тестового изображения, были визуально представлены вокруг центра дисплея (1 цель и 49 отвлекающих факторов). Положение каждого слова было случайным образом изменено между блоками, чтобы избежать искажения специфических для сигналов эффектов на ответ фМРТ во время периодов визуализации.Слово, соответствующее воображаемой категории, было выделено красным цветом (цель), а другие слова — черным цветом (отвлекающие факторы). Начало и конец периодов изображения сигнализировались звуковыми сигналами. Испытуемые должны были начать воображать как можно больше изображений объектов, относящихся к категории, описанной красным словом, и были проинструктированы держать глаза закрытыми от первого сигнала до второго сигнала. После второго звукового сигнала было представлено слово, соответствующее целевой категории, чтобы испытуемые могли оценить яркость своих мысленных образов по пятибалльной шкале (очень яркая, довольно яркая, довольно яркая, не яркая, не может распознать цель). нажатие кнопки.25 категорий в каждом прогоне были псевдослучайно выбраны из 50 категорий, так что два последовательных прогона содержали все 50 категорий.
Эксперимент с ретинотопией
Эксперимент с ретинотопией проводился по стандартному протоколу 51,52 с использованием вращающегося клина и расширяющегося кольца мерцающей шахматной доски. Данные были использованы для определения границ между каждой зрительной корковой областью и для определения ретинотопической карты (V1 – V4) на плоских кортикальных поверхностях отдельных субъектов.
Эксперимент с локализатором
Мы провели функциональные эксперименты с локализатором для определения LOC, FFA и PPA для каждого индивидуального объекта 53,54,55 . Эксперимент с локализатором состоял из 4–8 запусков, каждый из которых содержал 16 блоков стимулов. В этом эксперименте неповрежденные или зашифрованные изображения (угол обзора 12 × 12 градусов) из категорий лиц, объектов, домов и сцен были представлены в центре экрана. Каждый из восьми типов стимулов (четыре категории × два условия) предъявлялся дважды за цикл.Каждый блок стимула состоял из 15-секундного неповрежденного или зашифрованного предъявления стимула. Неповрежденные и зашифрованные блоки стимулов предъявлялись последовательно (порядок неповрежденных и зашифрованных блоков стимулов был случайным) с последующим 15-секундным периодом отдыха, состоящим из однородного серого фона. Дополнительные 33- и 6-секундные периоды отдыха были добавлены к началу и концу каждого бега соответственно. В каждом блоке стимулов 20 различных изображений одного и того же типа были представлены в течение 0,3 с с последующим пустым экраном 0.4 с.
Получение МРТ
Данные фМРТ были собраны с использованием 3,0-Тесла-сканера Siemens MAGNETOM Trio A Tim, расположенного в Центре визуализации активности мозга ATR. Для получения функциональных изображений, охватывающих весь мозг, было выполнено сканирование с чередованием T2 * -взвешенного градиентного EPI (эхо-планарное изображение) (представление изображений, эксперименты с изображениями и локализаторами: время повторения (TR), 3000 мс; время эхо (TE), 30 мс; угол поворота 80 градусов; поле зрения (FOV) 192 × 192 мм 2 ; размер вокселя 3 × 3 × 3 мм 3 ; промежуток между срезами 0 мм; количество срезов 50) или вся затылочная доля (эксперимент с ретинотопией: TR, 2000 мс; TE, 30 мс; угол поворота, 80 градусов; FOV, 192 × 192 мм 2 ; размер вокселя, 3 × 3 × 3 мм 3 ; промежуток в срезе, 0 мм; количество ломтиков 30).T2-взвешенные изображения турбо спинового эхо-сигнала сканировались для получения анатомических изображений с высоким разрешением тех же срезов, которые использовались для EPI (представление изображений, эксперименты с изображениями и локализатором: TR, 7020 мс; TE, 69 мс; угол поворота, 160 градусов; FOV. , 192 × 192 мм 2 ; размер вокселя, 0,75 × 0,75 × 3,0 мм 3 ; эксперимент с ретинотопией: TR, 6000 мс; TE, 57 мс; угол переворота, 160 градусов; FOV, 192 × 192 мм 2 ; размер вокселя 0,75 × 0,75 × 3,0 мм 3 ). Также были получены тонкоструктурные изображения всей головы, подготовленные с помощью T1-взвешенной намагниченности для быстрого получения градиент-эхо (TR, 2250 мс; TE, 3.06 мс; TI, 900 мс; угол переворота, 9 град, FOV, 256 × 256 мм 2 ; размер вокселя, 1.0 × 1.0 × 1.0 мм 3 ).
Предварительная обработка данных МРТ
Первые 9-секундные сканы для экспериментов с TR = 3 с (представление изображений, эксперименты с изображениями и локализатором) и 8-секундные сканы для экспериментов с TR = 2 с (эксперимент с ретинотопией) каждого прогона были отброшены. чтобы избежать нестабильности МРТ сканера. Полученные данные фМРТ подверглись трехмерной коррекции движения с использованием SPM5 (http: //www.fil.ion.ucl.ac.uk/spm). Затем данные были сопоставлены с анатомическим изображением с высоким разрешением внутри сеанса тех же срезов, которые использовались для EPI, а затем с анатомическим изображением всей головы с высоким разрешением. Затем зарегистрированные данные были повторно интерполированы на 3 × 3 × 3 мм 3 вокселей.
Для данных эксперимента по представлению изображений и экспериментов с изображениями после удаления линейного тренда внутри прогона амплитуды вокселей были нормализованы относительно средней амплитуды всего временного хода в каждом прогоне.Нормализованные амплитуды вокселей из каждого эксперимента затем усреднялись в пределах каждого 9-секундного блока стимулов (три тома; эксперимент с изображением) или в течение каждого 15-секундного периода изображения (пять объемов; эксперимент с изображениями), соответственно (если не указано иное), после сдвига данные на 3 секунды (один объем) для компенсации задержек гемодинамики.
Выбор области интереса
V1 – V4 были выделены стандартным ретинотопическим экспериментом 51,52 . Данные ретинотопического эксперимента были преобразованы в координаты Талаираха, а визуальные корковые границы были очерчены на уплощенных корковых поверхностях с помощью BrainVoyager QX (http: // www.brainvoyager.com). Координаты вокселей вокруг границы серого и белого вещества в V1 – V4 были идентифицированы и преобразованы обратно в исходные координаты изображений EPI. Воксели от V1 до V3 были объединены и определены как «LVC». LOC, FFA и PPA были идентифицированы с использованием обычных функциональных локализаторов 53,54,55 . Данные экспериментов с локализатором были проанализированы с помощью SPM5. Воксели показывают значительно более высокие отклики на объекты, лица или сцены, чем для скремблированных изображений (двусторонний t -тест, нескорректированный P <0.05 или 0,01) были идентифицированы и определены как LOC, FFA и PPA соответственно. Смежная область, покрывающая LOC, FFA и PPA, была вручную очерчена на сплющенных кортикальных поверхностях, и область была определена как «HVC». Вокселы, перекрывающиеся с LVC, были исключены из HVC. Вокселы от V1 до V4 и HVC были объединены для определения «VC». В регрессионном анализе воксели, показывающие наивысший коэффициент корреляции с целевой переменной в сеансе обучающего изображения, были выбраны для прогнозирования каждой функции (максимум 500 вокселей для V1 – V4, LOC, FFA и PPA; 1000 вокселей для LVC, HVC и ВК).
Визуальные особенности
Мы использовали четыре типа вычислительных моделей: CNN 20 , HMAX 21,22,23 , GIST 24 и SIFT 18 в сочетании с ‘BoF’ 16 для построения визуальных особенности из изображений. Функции с фазой обучения модели (HMAX и SIFT + BoF) использовали для обучения 1000 изображений, принадлежащих к категориям, используемым в сеансе обучающих изображений (150 категорий). Каждая модель подробно описана в следующих подразделах.
Сверточная нейронная сеть
Мы использовали реализацию MatConvNet (http: // www.vlfeat.org/matconvnet/) модели CNN 20 , которая была обучена с изображениями в ImageNet 31 для классификации 1000 категорий объектов. CNN состояла из пяти сверточных слоев и трех полностью связанных слоев. Мы случайным образом выбрали 1000 единиц в каждом из слоев с первого по седьмой и использовали все 1000 единиц на восьмом уровне. Мы представили каждое изображение вектором выходных данных этих устройств и назвали их CNN1 – CNN8 соответственно.
HMAX
HMAX 21,22,23 — это иерархическая модель, которая расширяет простые и сложные ячейки, описанные Hubel и Wiesel 56,57 , и вычисляемые функции через иерархические уровни.Эти слои состоят из слоя изображения и шести последующих слоев (S1, C1, S2, C2, S3 и C3), которые построены из предыдущих слоев путем чередования операций сопоставления шаблонов и max. В расчетах на каждом слое мы использовали те же параметры, что и в предыдущем исследовании 22 , за исключением того, что количество элементов в слоях C2 и C3 было установлено на 1000. Мы представили каждое изображение вектором трех типов функций HMAX, который состоял из 1000 случайно выбранных выходных данных единиц в слоях S1, S2 и C2, и всех 1000 выходных данных в слое C3.Мы определили эти выходы как HMAX1, HMAX2 и HMAX3 соответственно.
GIST
GIST — это модель, разработанная для компьютерной задачи категоризации сцены 24 . Для вычисления GIST изображение сначала было преобразовано в шкалу серого, а его размер был изменен до максимальной ширины 256 пикселей. Далее изображение фильтровали с помощью набора фильтров Габора (16 ориентаций, 4 шкалы). После этого отфильтрованные изображения были сегментированы сеткой 4 × 4 (16 блоков), а затем отфильтрованные выходные данные в каждом блоке были усреднены для извлечения 16 ответов для каждого фильтра.Ответы от нескольких фильтров были объединены, чтобы создать 1024-мерный вектор признаков для каждого изображения (16 (ориентации) × 4 (масштаб) × 16 (блоков) = 1024).
SIFT с BoF (SIFT + BoF)
Визуальные характеристики с использованием SIFT с подходом BoF были рассчитаны на основе дескрипторов SIFT. Мы вычислили дескрипторы SIFT из изображений, используя реализацию VLFeat 58 плотного SIFT. В подходе BoF каждый компонент вектора признаков (визуальные слова) создается путем векторного квантования извлеченных дескрипторов.Используя ~ 1000000 дескрипторов SIFT, рассчитанных из независимого набора обучающих образов, мы выполнили кластеризацию k-средних, чтобы создать набор из 1000 визуальных слов. Дескрипторы SIFT, извлеченные из каждого изображения, были квантованы в визуальные слова с использованием ближайшего центра кластера, и частота каждого визуального слова была вычислена для создания гистограммы BoF для каждого изображения. Наконец, все гистограммы, полученные в результате описанной выше обработки, прошли L-1 нормализацию, чтобы стать векторами единичной нормы. Следовательно, функции из SIFT с подходом BoF инвариантны к масштабированию, перемещению и повороту изображения и частично инвариантны к изменениям освещения и аффинной или трехмерной проекции.
Декодирование визуальных признаков
Мы построили модели декодирования для прогнозирования векторов визуальных признаков видимых объектов по активности фМРТ с использованием функции линейной регрессии. Здесь мы использовали SLR (http://www.cns.atr.jp/cbi/sparse_estimation/index.html) 32 , который может автоматически выбирать важные функции для прогнозирования. Известно, что разреженная оценка хорошо работает, когда размерность объясняющей переменной высока, как в случае с данными фМРТ 59 .
Учитывая образец фМРТ, состоящий из активности d вокселей в качестве входных данных, функция регрессии может быть выражена как
, где x i — скалярное значение, определяющее амплитуду фМРТ воксела i , w i — вес вокселя i и w 0 — смещение.Для простоты смещение w 0 поглощается вектором весов, так что. В данные вводится фиктивная переменная x 0 = 1, так что. Используя эту функцию, мы смоделировали l -й компонент каждого вектора визуальных признаков как целевую переменную t l ( l ∈ {1,…, L }), что объясняется регрессией функция y ( x ) с аддитивным гауссовым шумом, как описано в
, где ∈ — гауссовская случайная величина с нулевым средним с точностью до шума β .
Учитывая набор обучающих данных, SLR вычисляет веса для функции регрессии, так что функция регрессии оптимизирует целевую функцию. Чтобы построить целевую функцию, мы сначала выражаем функцию правдоподобия как
, где N — количество выборок, а X — это матрица данных фМРТ N × ( d +1), у которой n -я строка — это d + одномерный вектор x n и являются выборками компонента вектора визуальных признаков.
Мы выполнили оценку байесовского параметра и приняли автоматическое определение релевантности до 32 , чтобы внести разреженность в оценку веса. Мы рассмотрели оценку весового параметра w с учетом наборов обучающих данных { X , t l }. Мы приняли априорное распределение Гаусса для весов w и неинформативные априорные значения для параметров точности веса и параметра точности шума β , которые описаны как
. оцениваемые параметры и веса могут быть оценены путем оценки следующей совместной апостериорной вероятности w :
. Учитывая, что оценка совместной апостериорной вероятности аналитически неразрешима, мы аппроксимировали ее, используя вариационный байесовский метод 32,60, 61 .Хотя результаты, показанные на основных рисунках, основаны на этой модели автоматического определения релевантности, мы получили качественно аналогичные результаты с использованием других регрессионных моделей (дополнительные рисунки 21 и 22).
Мы обучили модели линейной регрессии, которые предсказывают векторы признаков отдельных типов / слоев признаков для категорий наблюдаемых объектов по образцам фМРТ в сеансе обучающего изображения. Для наборов тестовых данных образцы фМРТ, соответствующие тем же категориям (35 образцов в сеансе тестового изображения, 10 образцов в эксперименте с изображениями), были усреднены по испытаниям для увеличения отношения сигнал / шум сигналов фМРТ.Используя изученные модели, мы спрогнозировали векторы признаков видимых / воображаемых объектов на основе усредненных образцов фМРТ, чтобы построить один прогнозируемый вектор признаков для каждой из 50 тестовых категорий.
Синтез предпочтительных изображений с использованием максимизации активации
Мы использовали метод максимизации активации для генерации предпочтительных изображений для отдельных единиц в каждом слое CNN 33,34,35,36 . Синтез предпочтительных изображений начинается со случайного изображения и оптимизирует изображение, чтобы максимально активировать целевой блок CNN, итеративно вычисляя, как изображение должно быть изменено с помощью обратного распространения.Этот анализ был реализован с использованием специального программного обеспечения, написанного в MATLAB на основе кодов Python, представленных в серии сообщений в блогах (Mordvintsev, A., Olah, C., Tyka, M., DeepDream — пример кода для визуализации нейронных сетей, https: / /github.com/google/deepdream, 2015; Ойгард, AM, Визуализация классов GoogLeNet, https://github.com/auduno/deepdraw, 2015).
Идентификационный анализ
В ходе идентификационного анализа категории видимых / воображаемых объектов были идентифицированы с использованием векторов визуальных признаков, декодированных из сигналов фМРТ.Перед анализом идентификации были вычислены векторы визуальных признаков для всех предварительно обработанных изображений во всех категориях (15 372 категории в ImageNet 31 ), за исключением тех, которые использовались в экспериментах фМРТ и их категорий гиперонимов / гипонимов, а также тех, которые использовались для визуальных обучение функциональной модели (HMAX и SIFT + BoF). Векторы визуальных признаков отдельных изображений были усреднены внутри каждой категории, чтобы создать средние по категории векторы признаков для всех категорий, чтобы сформировать набор кандидатов.Мы вычислили коэффициенты корреляции Пирсона между декодированными и средними по категории векторами признаков в наборах кандидатов. Для количественной оценки точности мы создали наборы кандидатов, состоящие из увиденных / воображаемых категорий и указанного количества случайно выбранных категорий. Ни одна из категорий в наборе кандидатов не использовалась для обучения декодера. Учитывая декодированный вектор признаков, идентификация категории проводилась путем выбора категории с наивысшим коэффициентом корреляции среди наборов кандидатов.
Статистика
В основном анализе мы использовали t -тесты, чтобы проверить, превышает ли среднее значение коэффициентов корреляции и среднее значение точности идентификации по субъектам уровень вероятности (0 для коэффициента корреляции и 50% для точность идентификации). Для коэффициентов корреляции перед статистическими тестами применялось преобразование Фишера z . Перед каждым тестом t мы выполняли тест Шапиро-Уилка для проверки нормальности и подтвердили, что нулевая гипотеза о том, что данные, полученные из нормального распределения, не была отклонена для всех случаев ( P > 0.01).
Доступность данных и кода
Экспериментальные данные и коды, подтверждающие выводы этого исследования, доступны в нашем репозитории: https://github.com/KamitaniLab/GenericObjectDecoding.
Простых штриховых рисунков достаточно для функционального МРТ-декодирования категорий природных сцен
С доисторических времен люди запечатлевали сцены повседневной жизни простыми линиями (1). Штриховые рисунки пронизывают историю искусства в большинстве культур на Земле (см. Примеры на Рис. 1 A – C ).Хотя линейным рисункам не хватает многих определяющих характеристик, которые можно увидеть в реальном мире (цвет, большая часть текстуры, большая часть затенения и т. Д.), Они, тем не менее, отражают некоторую существенную структуру, которая делает их полезными как способ изобразить мир для художественного выражения или художественного выражения. как наглядная запись. Фактически, дети используют «граничные линии» или «охватывающие линии» для определения формы предметов и частей предметов в своих первых попытках изобразить окружающий их мир (2) (см. Пример на рис. 1 D ).Естественная способность людей распознавать и интерпретировать штриховые рисунки также сделала их полезным инструментом для изучения объектов и сцен (3–5).
В экспериментах, описанных в этой статье, мы использовали линейные рисунки природных сцен шести категорий (пляжи, городские улицы, леса, шоссе, горы и офисы; рис. S1), чтобы исследовать способность человека эффективно классифицировать природные сцены. Люди могут распознать суть сцены с презентацией всего за 120 мс (6), даже если их внимание сосредоточено в другом месте поля зрения (7, 8).Эта суть может включать много деталей помимо базового описания на уровне категории (9–11).
Одна из причин, по которой люди могут так быстро обрабатывать естественные сцены, заключается в том, что наша визуальная система эволюционировала для эффективного кодирования статистических закономерностей в нашей окружающей среде. Тем не менее, мы можем распознавать и классифицировать линейные рисунки природных сцен, несмотря на то, что они имеют очень разные статистические характеристики от фотографий (Рис. 2 D и Рис. S1). Действительно, тот факт, что ранние художники, а также маленькие дети представляют свой мир штриховыми рисунками, предполагает, что такие изображения отражают суть нашего природного мира.Как штриховые рисунки обрабатываются в мозгу? В чем сходство и различие в обработке линейных рисунков и цветных фотографий природных сцен? Здесь мы подходим к этим вопросам, расшифровывая информацию о категории сцены из паттернов мозговой активности, измеренной с помощью функциональной МРТ (фМРТ) у наблюдателей, просматривающих фотографии и линейные рисунки естественных сцен.
Ранее мы обнаружили, что информация о категории сцены содержится в паттернах активности фМРТ в парагиппокампальной области (PPA), ретросплениальной коре (RSC), латеральном затылочном комплексе (LOC) и первичной зрительной коре головного мозга (V1). (12).Паттерны активности PPA, по-видимому, наиболее тесно связаны с поведением человека (12), а активность в V1, PPA и RSC, вызванная хорошими образцами категорий сцены, содержит значительно больше информации, относящейся к категории сцены, чем модели, вызванные плохими образцами (13) . Интересно, что проверка средних изображений хороших и плохих образцов категории предполагает, что хорошие образцы могут содержать более определенную глобальную структуру, видимую на изображениях, чем плохие образцы (13), предполагая, что функции, которые фиксируют глобальную информацию в изображении, могут играть особенно важную роль. важная роль в категоризации сцены.
В работе, представленной здесь, мы исследуем влияние структуры сцены, или макета, более непосредственно, сокращая изображения естественных сцен до самого минимума, простых линий. Если такая структура действительно критична, означает ли это, что мы можем декодировать категории сцен из активности мозга, вызванной штриховыми рисунками? Если да, то как эти изображения связаны с изображениями на полноцветных фотографиях?
Наконец, какие аспекты структуры, сохраненные в линейных рисунках, позволяют классифицировать естественные сцены? Когда цвет и большая часть текстуры отсутствуют на изображении, все, что остается, — это структура сцены, захваченная линиями.В поведенческом эксперименте мы пытаемся различить вклад локальной и глобальной структуры путем выборочного удаления длинных или коротких контуров из линейных рисунков природных сцен.
Результаты
Расшифровка фМРТ.
Чтобы исследовать и сравнить паттерны нейронной активации, вызванные цветными фотографиями и штриховыми рисунками естественных сцен, мы попросили участников пассивно просматривать блоки изображений, находясь внутри сканера МРТ. В половине запусков участники видели цветные фотографии шести категорий (пляжи, городские улицы, леса, шоссе, горы и офисы), а в другой половине — линейные рисунки тех же изображений (рис.2 и рис. S1). Порядок блоков с фотографиями и соответствующими линейными рисунками был уравновешен участниками. Активность, зависящая от уровня кислорода в крови, была зарегистрирована в 35 коронарных срезах, покрывающих примерно две трети заднего отдела мозга.
Мы проанализировали активность, зависящую от уровня кислорода в крови, в ретинотопных областях зрительной коры, а также в PPA, RSC и LOC. V1 представляет собой интересную область мозга для сравнения фотографий с линейными рисунками, поскольку она оптимизирована для выделения краев и линий из изображения сетчатки (14, 15).Следовательно, возможно, что V1 может аналогичным образом представлять фотографии и линейные рисунки. Зрительные области V2, VP (известные как V3v, для вентральной V3 в некоторых номенклатурах) и V4 представляют интерес, потому что они создают более сложные представления на основе информации в V1, включая представления, основанные на более глобальных аспектах изображения (16 –18). PPA и RSC, которые, как было показано, предпочитают сцены объектам и другим визуальным стимулам (19, 20), представляют интерес для этого анализа, потому что они (и, в некоторой степени, LOC) содержат информацию о категории сцены в своих паттерны активности, которые тесно связаны с характеристиками категоризации поведенческих сцен (12).
Отдельный сеанс фМРТ для измерения ретинотопии позволил нам очертить области V1 и V4, но граница между V2 и VP не была очевидна для всех участников, поэтому мы рассматривали эти области как группу (V2 + VP). PPA, RSC и LOC были определены на основе линейных контрастов в стандартном сеансе локализатора, показывающем лица, сцены, объекты и зашифрованные объекты ( SI Materials and Methods ).
Расшифровка фотографий.
Используя только данные прогонов, когда участники просматривали цветные фотографии, мы обучили и протестировали декодер, чтобы предсказать, какую из шести категорий сцены участники просматривали, в процедуре перекрестной проверки с использованием данных из каждой интересующей области (ROI) по очереди.Мы обнаружили, что точность декодирования выше вероятности (> 16,7%) по всей иерархии визуальной обработки (рис. 3): 24% в V1 [ t (9) = 3,03, P = 0,0071; односторонний t тест в сравнении с уровнем вероятности], 27% в V2 + VP [ t (9) = 7,40, P = 2,05 × 10 −5 ], 24% в V4 [ t ( 9) = 5,18, P = 2,9 × 10 −4 ], 32% в PPA [ t (9) = 3,97, P = 0,0016] и 23% в RSC [ t (9) = 3.02, P = 0,0073]. Эти результаты подтверждают наши более ранние наблюдения, что эти регионы содержат информацию, которая различает категории природных сцен (12). В отличие от наших предыдущих данных (12), точность декодирования 21% в LOC не достигла значимости [ t (9) = 1,5, P = 0,080], возможно, из-за различий в категориях сцен, используемых в двух исследования и, в частности, различия в количестве объектов, однозначно идентифицирующих категорию. Например, в текущем эксперименте автомобили появились как на автомагистралях, так и на городских улицах, тогда как в предыдущем эксперименте автомобили однозначно идентифицировали шоссе.Хотя было показано, что LOC кодирует объекты в сценах (21), а также пространственные отношения между объектами (22, 23), его вклад в категоризацию сцен, вероятно, зависит от таких диагностических объектов.
Рис. 3.Точность прямого декодирования категорий сцен из мозговой активности, когда участники просматривали цветные фотографии (CP) и линейные рисунки (LD), а также перекрестное декодирование от CP к LD и от LD к CP. Точность была значительно выше вероятности (1/6) во всех условиях, за исключением перекрестного декодирования от LD к CP в RSC.Прямое декодирование для CP и LD было статистически одинаковым для всех ROI. Падение от прямого декодирования LD к перекрестному декодированию от LD к CP было значительным в V1 (* P <0,05). Планки погрешностей - это SEM более 10 участников.
Расшифровка штриховых рисунков.
Как происходит декодирование, когда фотографии сокращаются до простых строк? Чтобы ответить на этот вопрос, мы повторили анализ перекрестной проверки LORO, используя прогоны, во время которых участники видели линейные рисунки естественных сцен.Декодирование категории из штриховых рисунков было возможно не только во всех тех же областях мозга, что и декодирование из цветных фотографий [V1: 29%, t (9) = 4,71, P = 5,5 × 10 −4 ; V2 + VP: 27%, t (9) = 4,09, P = 0,0014; V4: 26%, t (9) = 3,72, P = 0,0024; PPA: 29%, t (9) = 7,24, P = 2,4 × 10 −5 ; и RSC: 23%, t (9) = 3,17, P = 0,0057; все односторонние тесты t по сравнению с уровнем вероятности], но, что еще более удивительно, точность декодирования штриховых рисунков также была на том же уровне, что и декодирование цветных фотографий во всех областях интереса [V1: t (9) = 1.18, P = 0,27; V2 + VP: t (9) = 0,15, P = 0,88; V4: t (9) = 0,77, P = 0,46; PPA: t (9) = 0,79, P = 0,45; и RSC: t (9) = 0,02, P = 0,98; все парные, двусторонние t тестов] (рис. 3). То есть, несмотря на заметные различия в статистике сцен и значительную деградацию информации, штриховые рисунки можно декодировать так же точно, как и фотографии, в каждом тестируемом регионе. Фактически, в V1 мы даже увидели несколько более высокую, хотя и незначительную, точность декодирования для штриховых рисунков, чем для фотографий.Хотя мы предсказали, что штриховые рисунки могут содержать некоторые важные черты категорий естественных сцен, что делает возможным декодирование, удивительно, что для фотографий, похоже, нет никакой дополнительной пользы. Однако следует иметь в виду, что линейные рисунки, использованные в этом исследовании, были созданы обученными художниками, отслеживающими только те контуры на изображении, которые лучше всего отражают сцену. Четко определенные контуры могут облегчить извлечение, в частности, в V1, различий и закономерностей в ориентации в определенных областях изображения по категориям.Ранее было показано, что такая преобладающая информация об ориентации может быть декодирована из паттернов активности мультивокселей в V1 (24).
В эксперименте фМРТ блоки фотографий чередовались с блоками линейных рисунков. Может ли высокая точность декодирования штриховых рисунков быть результатом визуального изображения соответствующих цветных фотографий, представленных в предыдущем блоке? Чтобы рассмотреть эту возможность, мы сравнили скорость декодирования для пяти участников, которые первыми увидели фотографии, с пятью участниками, которые первыми увидели линейные рисунки.Ни в одной из рентабельности инвестиций мы не увидели значительного улучшения декодирования штриховых рисунков для группы, которая первой увидела фотографии ( P > 0,22; односторонние непарные тесты t ), и, фактически, во всех регионах, кроме V1 скорости декодирования были численно ниже для группы «первые фотографии».
Сходная точность декодирования штриховых рисунков и фотографий поднимает интересный вопрос: декодируем ли мы аналогичную информацию в двух случаях? Хотя представления цветных фотографий и штриховых рисунков должны в некоторой степени отличаться, возможно, что те особенности, которые обозначают категорию сцены, лучше всего улавливаются краями и линиями изображения.Однако, прежде чем сделать такой вывод, мы должны рассмотреть альтернативную возможность: мозг использует другую, но одинаково эффективную информацию для определения категории сцены для фотографий и штриховых рисунков.
Декодирование по типам изображений.
Если мозг использует различную информацию для декодирования категории сцены из фотографий и штриховых рисунков, то мы должны увидеть снижение точности декодирования, когда мы тренируемся на одном типе изображения и тестируем другой (например, тренируемся на линейных рисунках и тестируем на фотографиях). ).Если, с другой стороны, информация, которая различает категории, одинакова для фотографий и штриховых рисунков, то мы должны увидеть аналогичную точность декодирования для перекрестного декодирования одного типа изображения в другой, как и для прямого декодирования одного типа изображения в другой. тот же тип изображения.
Чтобы проверить эти две гипотезы, мы скрестили факторы обучения на фотографиях или штриховых рисунках с тестированием на одном и том же типе изображения (прямое декодирование) или на другом типе изображения (перекрестное декодирование) (рис.3). Для каждой области интереса мы выполнили двухфакторный дисперсионный анализ с двумя независимыми переменными: ( i ) обучение на фотографиях по сравнению с линейными рисунками и ( ii ) прямое декодирование в сравнении с перекрестным декодированием. Ни основные эффекты обучения и прямого и перекрестного декодирования, ни их взаимодействие не достигли значимости ни в одной области инвестиций, хотя было незначительное снижение точности перекрестного декодирования в V1 ( F 1,9 = 3,74, P = 0,061). Эти данные предполагают, за возможным исключением V1, что категория декодирования из линейных чертежей основывается на той же информации, что и категория декодирования из фотографий.Однако мы не можем сделать какие-либо убедительные выводы из нулевых результатов. Поэтому мы проверили сходство представлений категорий, выявленных штриховыми рисунками и фотографиями, далее, обращаясь к ошибкам декодирования.
Корреляция ошибок декодирования.
В качестве дополнительной меры сходства моделей активности, выявленных фотографиями и штриховыми рисунками, мы сравнили ошибки декодирования двух типов изображений. Конкретные ошибки или недоразумения, допущенные декодером, которые записываются в матрицу неточностей, могут выявить аспекты лежащего в основе представления наших категорий (12, 25).Если линейные рисунки и фотографии вызывают сходные представления категорий в области, то путаница, вносимая декодером, неизбежно будет аналогичной. Строки матрицы путаницы указывают, какая категория сцены была представлена участникам, а столбцы представляют собой прогноз декодера. Диагональные элементы соответствуют правильному декодированию, а недиагональные элементы соответствуют ошибкам декодирования (рис. 4). Для этого анализа мы объединили записи об ошибках для симметричных пар категорий (например,g., смешанные пляжи с автомагистралями были объединены с запутанными автомагистралями для пляжей), и мы усреднили матрицы путаницы по всем 10 участникам. Чтобы сравнить путаницу, вызванную фотографиями, с ошибками, вызванными штриховыми рисунками, мы вычислили коэффициент корреляции Пирсона для корреляции недиагональных элементов матрицы неточностей для двух типов изображений (рис. S2).
Рис. 4.Матрицы путаницы для прямого декодирования категорий сцен из цветных фотографий и штриховых рисунков в PPA.Диагональные записи — это правильные скорости декодирования для соответствующих категорий, а недиагональные записи указывают на ошибки декодирования.
Шаблоны ошибок при декодировании с линейных рисунков сильно коррелировали с шаблонами ошибок при декодировании по фотографиям в PPA [ r (13) = 0,86, P = 3,3 × 10 −5 ] и RSC [ r (13) = 0,76, P = 9,7 × 10 −4 ], несколько коррелировано в V4 [ r (13) = 0,52, P = 0.047], но не коррелирован в V1 [ r (13) = 0,47, P = 0,075] или V2 + VP [ r (13) = 0,47, P = 0,081]. Эти результаты дополнительно подтверждают утверждение о том, что информация, относящаяся к категории, полученная с помощью цветных фотографий или штриховых рисунков, наиболее похожа в PPA, в некоторой степени аналогична в V4 и наименее похожа в V1 и V2 + VP. Другими словами, этот образец результатов предполагает увеличение сходства представлений фотографий и штриховых рисунков по мере того, как мы поднимаемся по визуальной иерархии.
Чтобы исключить возможность того, что различия между областями мозга могут быть отнесены к разнице в количестве вокселей в каждой области интереса, мы повторили анализ путем субдискретизации равного количества вокселей в каждой области интереса. Хотя численно несколько различаются, результаты, полученные в результате этого анализа, подтверждают те же паттерны эффектов, о которых сообщалось выше ( SI Materials and Methods ). Наконец, мы провели анализ прожектором всего мозга, чтобы найти области за пределами наших предопределенных областей интереса, которые кодируют категорию сцены.В дополнение к известным областям интереса мы обнаружили небольшой кластер вокселей с точностью декодирования, значительно превышающей вероятность в левом предклинье (рис. S3 и S4).
Глобальная и локальная структура.
Поскольку информация, содержащаяся в линейных рисунках, достаточна для категоризации и приводит к сопоставимой производительности декодирования, как и в случае с фотографиями, мы можем начать задаться вопросом, что в линейных рисунках делает возможной такую удивительно хорошую производительность. В своей хорошо принятой модели Олива и Торральба использовали свойства амплитудного спектра пространственных частот («пространственная огибающая») для выделения категорий природных сцен (26).Однако пространственно-частотные спектры штриховых рисунков радикально отличаются от спектров соответствующих фотографий (рис. S5), но люди все же могут легко классифицировать их. Какие свойства линейных рисунков позволяют людям классифицировать их таким образом? Поскольку форма или структура являются основным свойством изображения, сохраняемым в линейных чертежах, мы задаемся вопросом, является ли глобальная или локальная структура важным фактором для категоризации.
Что мы подразумеваем под глобальной и локальной структурой в этом контексте? Наши линейные рисунки были созданы обученными художниками, которые нарисовали контуры цветных фотографий на графическом планшете.Мы считаем, что все линии, нарисованные одним движением, не отрывая перо от планшета, принадлежат одному контуру. Каждый контур состоит из серии отрезков прямых линий, причем конечная точка одного отрезка является начальной точкой следующего. Мы предположили, что длинные контуры с большей вероятностью отражают глобальную структуру, а короткие контуры с большей вероятностью представляют локальную структуру на изображении. Здесь мы интерпретируем «глобальную структуру» как представление общих областей изображения, таких как небо, вода, песок или фасад здания, в отличие от более мелких деталей, таких как листья, окна в зданиях или отдельные выступы на склоне горы.Интуитивно понятно, что такие большие области изображения, вероятно, будут разделены длинными контурами, тогда как короткие контуры с большей вероятностью очертят более мелкие детали. Как мы можем проверить, сохраняется ли эта предполагаемая связь между длиной строки и глобальной / локальной структурой на наших изображениях? Если контур разделяет две большие области изображения, тогда области по обе стороны от контура должны различаться по своим свойствам изображения, например, по их цветовому распределению. Если контур определяет только локальную структуру на большой площади, то распределение цветов с обеих сторон, скорее всего, будет одинаковым.
Чтобы оценить области, разделенные нашими контурами, мы определили расстояние цветовой гистограммы (CHD) между областями, которые попали по обе стороны от линейных сегментов на исходных цветных фотографиях (рис. S6). В области на одной стороне линейного сегмента мы разделили каждый из трех цветовых каналов (красный, зеленый и синий) на четыре ячейки одинакового размера (всего 4 3 = 64 ячейки), подсчитали количество пикселей в каждую ячейку и делят на общее количество пикселей в области. Эта процедура была повторена для области изображения с другой стороны отрезка линии.Затем мы вычислили CHD как евклидово расстояние между двумя гистограммами и усреднили CHD по всем линейным сегментам, принадлежащим одному контуру.
Если длинные контуры действительно разделяют глобальные области изображения, то следует ожидать, что области изображения на противоположных сторонах контура отличаются друг от друга более длинными, чем для коротких контуров, т. Е. Что их ВПС больше. Для каждого изображения мы отсортировали контуры по их общей длине и вычислили средний CHD отдельно для верхнего и нижнего квартилей контуров, измеренный по доле покрытых пикселей.Среднее значение ВПС для длинных контуров было значительно больше, чем для коротких контуров [длинный: 0,589; короткий: 0,555; t (474) = 8,16, P = 3,01 × 10 −15 ; парный, двусторонний тест t ; относительно ИБС для отдельных категорий см. Таблицу S2]. Эти данные предполагают, что длинные контуры действительно разделяют глобальные структуры на изображении, определяемые здесь как большие области на изображении, которые различаются по своим свойствам изображения (зафиксированным здесь цветовой гистограммой), тогда как короткие контуры менее склонны к этому.
Ухудшение линейных чертежей.
Теперь мы можем исследовать роль глобальной и локальной структуры в способности классифицировать сцены, систематически удаляя контуры из линейных чертежей (опуская их при визуализации линейных чертежей), начиная с самых длинных или самых коротких контуров. Какое удаление больше влияет на классификацию человека? Наша процедура изменения линейных рисунков также позволила нам спросить, насколько далеко мы можем продвинуть деградацию линейных рисунков, не повлияв на производительность категоризации.В частности, мы удалили контуры из наших линейных рисунков, так что было удалено 50% и даже 75% пикселей (рис. 2). Удаление контуров также привело к удалению углов и пересечений с линейных рисунков: при удалении 50% пикселей, начиная с самых коротких / самых длинных контуров, в среднем 61% (SD = 12%) / 44% (SD = 10%) убраны пересечения углов и линий; при удалении 75% пикселей удалялось 81% (SD = 9%) / 70% (SD = 8%) углов. Другими словами, при удалении длинных контуров удалялось меньше углов и пересечений.
Мы использовали одну и ту же / другую задачу для оценки характеристик категоризации для различных форм ухудшения состояния линии. В каждом испытании участникам быстро последовательно показывали три линейных рисунка (рис. 5 A ). Первое и третье изображения были штриховыми рисунками двух разных природных сцен из одной категории (например, обеих городских улиц). Участников попросили указать, было ли второе изображение рисованием линии той же категории или другой, нажав «S» (то же) или «D» (разное) на клавиатуре компьютера.Уровень вероятности был на уровне 50%. Чтобы эффективно замаскировать критическое второе изображение, первое и третье изображения были показаны в виде белых линий на черном фоне, а второе изображение было показано черным на белом. Мы выбрали эту же / другую задачу суждения, потому что ( i ) то же самое / другое суждение было легче, чем суждение о шести альтернативных категориях принудительного выбора, и ( ii ) мы обнаружили, что другие линейные рисунки с обратным контрастом являются наиболее эффективные прямые и обратные маски для штриховых рисунков, позволяющие регулировать сложность задачи для каждого участника, изменяя продолжительность представления изображений.
Рис. 5.( A ) Динамика одной попытки поведенческого эксперимента. Асинхронность начала стимула (SOA) была скорректирована для каждого участника с использованием процедуры лестницы с неповрежденными линейными рисунками. ( B ) Производительность в поведенческом эксперименте для рисования линий с удаленными длинными или короткими контурами, так что было удалено 50% или 75% пикселей. Производительность значительно ( P <0,05) выше вероятности во всех случаях, и на 75% она значительно лучше для линейных чертежей с удаленными короткими, чем длинными контурами.Планки погрешностей - это SEM более 13 участников. * P <0,05, *** P <0,001.
После фазы практики для ознакомления участников с экспериментом, продолжительность представления каждого из трех изображений систематически сокращалась с 300 мс в порядке лестницы. Лестничное движение было прекращено при достижении стабильного уровня производительности 70% (SD на один блок меньше, чем частота обновления экрана). Примечательно, что такой уровень точности в том же / другом суждении все еще был возможен при времени представления всего 102 мс на изображение (среднее: 175 мс; стандартное отклонение: 66 мс).Этот вывод демонстрирует, что категоризация линейных рисунков природных сцен может быть достигнута с помощью одного беглого взгляда.
На последующем этапе тестирования время презентации оставалось неизменным на уровне значений, полученных для каждого участника во время подъема по лестнице. Чтобы проверить влияние удаления линий на поведенческие характеристики, мы заменили второе изображение четырьмя различными версиями ухудшенных изображений, пропуская линии, начинающиеся с самого длинного / самого короткого контура, до тех пор, пока не были удалены 50% или 75% пикселей (см.рис.2 и рис. S1 для примеров). Эти четыре типа деградации уравновешивались целевыми категориями и одинаковыми / разными испытаниями для каждого участника.
Примечательно, что производительность для всех четырех типов деградации все еще была значительно выше вероятности ( P <0,05; рис. 5 B ). Производительность была значительно лучше для штриховых рисунков с удалением 50% пикселей, чем с удалением 75% пикселей, когда эти пиксели были удалены в виде длинных контуров [ t (12) = 5.76, P = 9,0 × 10 −5 ], но не тогда, когда они были удалены в виде коротких контуров [ t (12) = 1,77, P = 0,10; парные, двусторонние t тестов]. Другими словами, ухудшение качества чертежей более чем на 50% ухудшает производительность только при удалении длинных контуров. Обратите внимание, что этот результат вряд ли будет вызван различиями в количестве удаленных углов и пересечений, поскольку при удалении длинных контуров было удалено меньше углов и пересечений.
Интересно, что производительность с 50% -ной деградацией была одинаковой, независимо от того, какой тип контуров был удален, предположительно потому, что в обоих случаях все еще было достаточно информации о сцене. Однако, когда изображения подверглись дальнейшей деградации, появилась значительная разница между длинными и короткими линиями: производительность с 75% -ной деградацией была значительно ниже при удалении длинных, а не коротких контуров [ t (12) = 2,67, P = 0,020 ], хотя доля пикселей, оставшихся на изображении, была одинаковой.Этот результат означает, что длинные контуры, которые, по нашему мнению, лучше отражают глобальную информацию об изображении, чем короткие контуры, были более важны для правильного определения категорий сцены. Вместе эти результаты предполагают основную роль глобальной, а не локальной информации об изображении в определении категории сцены. Информация о глобальном изображении может быть важным фактором при вычислении компоновки сцены, роль, которую часто приписывают PPA (19), который в значительной степени участвовал в категоризации естественной сцены здесь и в других местах (12, 27, 28).
Чтобы проверить, как эти поведенческие результаты соотносятся с результатами декодирования категории сцены из активности фМРТ, мы сравнили шаблоны ошибок в двух экспериментах ( SI Материалы и методы и рис. S7). Высокая корреляция ошибок с поведением в PPA ( r = 0,69, P = 0,0043), впервые установленная для шести альтернативных задач с принудительным выбором в исх. 12, усиливает тесную связь между нейронной активностью в этой области и поведением человека при категоризации сцен для самих изображений и категорий, в отличие от выполняемой задачи.
Обсуждение
Художественное выражение посредством рисования линий пронизывает большинство человеческих культур. Наши результаты показывают, что, несмотря на то, что это резко сокращенные версии естественных сцен, линейные рисунки отражают структуру сцен, которая позволяет категоризировать сцены. Нейронная активность, вызванная линейными рисунками, содержит достаточно информации, чтобы обеспечить шестистороннее декодирование категорий сцены по иерархии визуальной обработки, начиная с V1 по V4 вплоть до PPA и RSC.Примечательно, что декодирование категорий сцены из паттернов нейронной активности, вызванных линейными рисунками, было столь же точным, как декодирование из активности, генерируемой цветными фотографиями.
Успешное перекрестное декодирование, а также аналогичные шаблоны ошибок декодирования между цветными фотографиями и штриховыми рисунками предполагают, что два типа изображений генерируют схожую деятельность, зависящую от категории. Мы увидели увеличение корреляции паттернов ошибок по визуальной иерархии, начиная с низкой корреляции в V1 и V2 + VP, через промежуточную, но значимую корреляцию в V4, до высокой корреляции в PPA и RSC.Мы пришли к выводу, что структурной информации, сохраненной в линейных рисунках, достаточно для создания сильного категориально-зависимого представления категорий естественной сцены, которое хорошо совместимо с тем, которое создается с помощью цветных фотографий в PPA и RSC, но менее совместимо в ранних визуальных областях.
В версии V1 точность перекрестного декодирования штриховых рисунков в фотографии была значительно ниже, чем прямое декодирование штриховых рисунков. Кроме того, шаблоны ошибок, записанные в V1 для фотографий и штриховых рисунков, не были существенно коррелированы, что совместимо с представлением о том, что ранние визуальные области позволяют декодировать категории естественных сцен на основе общих низкоуровневых функций среди экземпляров данной сцены. категории, но эти особенности в некоторой степени различаются между фотографиями и штриховыми рисунками.Эта разница в надежности представлений категорий между областями V1 и более поздними также совместима с представлением о том, что, хотя категория сцены может быть различима на основе низкоуровневых функций, подобных V1, эти функции не обязательно все используются людьми для сделать такие категоризации (12).
По сравнению с полностью текстурированной и цветной фотографией, штриховой рисунок изображения — это резко обедненная версия изображения. Более того, преобразование фотографий в линейные рисунки значительно изменяет пространственно-частотный спектр.Однако наши поведенческие эксперименты, а также наши эксперименты по декодированию показывают, что человеческая способность классифицировать естественные сцены устойчиво к удалению этой информации. Эти результаты свидетельствуют против того, что богатые статистические свойства естественных сцен необходимы для быстрой и точной категоризации сцен.
Конечно, мозг может по-прежнему использовать информацию о цвете, затенении и текстуре на фотографиях, чтобы помочь в категоризации сцены, но наша работа предполагает, что функции, сохраненные в линейных рисунках, не только достаточны для категоризации сцены, но также вероятны. используется для классификации как штриховых рисунков, так и фотографий.Что это за особенности?
Мы предположили, что структура сцены, которая сохраняется в линейных рисунках, важна для категоризации. В частности, мы предсказали, что глобальная структура, которую мы определили как контуры, разделяющие большие, но относительно однородные области изображения, будет более важной, чем локальная структура, поскольку PPA участвует как в компоновке сцены (19), так и в категоризации сцены (12). , 28) и потому, что образцы хороших категорий, по-видимому, имеют более последовательную структуру глобальной сцены (13).Чтобы проверить эту гипотезу, мы изменили линейные рисунки, выборочно удалив длинные или короткие контуры. Мы обнаружили, что точность оценки одной и той же / другой категории была значительно ниже, когда мы удалили 75% пикселей из длинных контуров, чем когда мы удалили такой же процент пикселей из коротких контуров. Таким образом, похоже, что глобальная структура (лучше отражаемая длинными контурами) более важна для категоризации сцен из линейных чертежей, чем локальная структура (захваченная короткими контурами).
Таким образом, мы обнаружили, что можем выполнять шестистороннее декодирование категории сцены одинаково хорошо на основе мозговой активности, сгенерированной из линейных рисунков и цветных фотографий в ранних и промежуточных визуальных областях (V1, V2 + VP и V4), а также в PPA и RSC.Активность мозга в PPA и RSC для двух типов изображений особенно совместима, как показывают перекрестное декодирование и анализ ошибок декодирования. Систематически ухудшая линейные рисунки, мы определили, что глобальная структура, вероятно, будет играть более заметную роль, чем локальная структура, в определении категорий сцены из линейных рисунков.
Материалы и методы
Участники.
Десять добровольцев (средний возраст 29,5 года, стандартное отклонение 4,9 года; 6 женщин) участвовали в эксперименте фМРТ и 13 добровольцев (средний возраст 21 год.6 лет, СД 4,3 года; 11 женщин) участвовали в поведенческом эксперименте. Оба эксперимента были одобрены институциональным наблюдательным советом Университета Иллинойса. Все участники были здоровы, не имели в анамнезе психических или неврологических заболеваний и дали свое письменное информированное согласие. У участников было нормальное зрение или зрение с поправкой на нормальное.
Изображений.
Цветные фотографии (КП) шести категорий (пляжи, городские улицы, леса, шоссе, горы и офисы) были загружены из всемирной сети через несколько поисковых систем.Сотрудникам веб-службы Amazon Mechanical Turk платили за то, чтобы они оценивали качество изображений как образцы соответствующей категории. Для экспериментов в этой статье мы использовали только 80 изображений с наивысшим рейтингом для каждой категории. Изображения с огнем или другим потенциально неприятным содержанием были исключены из эксперимента (всего пять изображений). См. Torralbo et al. (13) для получения подробной информации о процедуре оценки изображений. Все фотографии были изменены до разрешения 800 × 600 пикселей для эксперимента.
Штриховые рисунки (LD) фотографий были созданы обученными художниками в Исследовательском институте Lotus Hill путем прорисовки контуров на цветных фотографиях с помощью настраиваемого графического пользовательского интерфейса.Порядок и координаты всех штрихов линий были записаны в цифровом виде, чтобы можно было позже реконструировать рисунки линий с любым разрешением. Для экспериментов штриховые рисунки визуализировались с разрешением 800 × 600 пикселей путем рисования черных линий на белом фоне.
Эксперимент с фМРТ.
В экспериментах фМРТ участники пассивно просматривали блоки из восьми изображений одной и той же категории. Каждое изображение было представлено в течение 2 с без перерыва. Перед первым блоком каждого прогона, между блоками и после последнего блока был вставлен 12-секундный интервал фиксации.Каждый запуск состоял из шести блоков, по одному на каждую из шести категорий. CP и LD были представлены в чередующихся прогонах, причем порядок типов изображений уравновешивался между участниками. Порядок блоков в прогонах, а также выбор и порядок изображений в блоках были рандомизированы для всех прогонов с нечетными номерами. В прогонах с четным номером повторялась блочная структура предыдущего прогона с нечетным номером, за исключением того, что использовался другой тип изображения (CP или LD). Двое участников просмотрели 14 пробежек, остальные восемь участников — 16 пробежек.Изображения были представлены с помощью системы обратной проекции с разрешением 800 × 600 пикселей, что соответствует углу обзора 23,5 × 17,6 °.
Сбор данных фМРТ.
изображений МРТ были записаны на 3-T Siemens Allegra. Функциональные изображения были получены с градиентным эхом, эхо-планарной последовательностью (время повторения 2 с; время эхо-сигнала 30 мс; угол поворота 90 °; матрица 64 × 64 вокселя; поле зрения 22 см; 35 корональных срезов. Толщиной 2,8 мм с зазором 0,7 мм, разрешение в плоскости 2,8 × 2,8 мм).Мы также собрали структурное сканирование с высоким разрешением (1,25 × 1,25 × 1,25 мм вокселей) (MPRAGE; время повторения, 2 с; время эхо-сигнала, 2,22 мс, угол поворота, 8 °) в каждом сеансе сканирования, чтобы помочь в регистрации нашего планарного эхо-сигнала. изображения через сеансы.
Анализ данных фМРТ.
Функциональные данные были зарегистрированы в контрольном томе (45-й том восьмого прогона) с использованием AFNI (29) для компенсации движения испытуемого во время эксперимента. Затем данные были нормализованы, чтобы представить процентное изменение сигнала по отношению к временному среднему значению для каждого прогона.Никаких других шагов сглаживания или нормализации не выполнялось. Объемы мозга, соответствующие блокам изображений в каждом прогоне, были извлечены из временного ряда с задержкой 4 с, чтобы учесть задержку гемодинамического ответа. Данные обрабатывались отдельно для каждой из областей интереса.
Данные активации из всех прогонов с цветными фотографиями, кроме одного, использовались вместе с соответствующими метками категорий сцены для обучения классификатора машины опорных векторов (SVM) (линейное ядро, C = 0.02) с помощью LIBSVM. Классификатор SVM, представленный данными из оставшегося прогона, сгенерировал прогноз для меток категорий сцены для каждого захвата мозга. Разногласия в предсказанных метках для восьми томов мозга, принадлежащих одному блоку, были разрешены большинством голосов, в результате чего метка, предсказываемая наиболее часто из восьми томов, была выбрана в качестве метки для всего блока. Связи были нарушены путем принятия метки с наивысшим значением решения в классификаторе SVM.Путем повторения этой процедуры так, чтобы каждый из прогонов CP был пропущен один раз (перекрестная проверка LORO), прогнозы для категорий сцены были сгенерированы для блоков в каждом прогоне (прямое декодирование). Точность декодирования вычислялась как доля правильных прогнозов по всем прогонам. Та же процедура перекрестной проверки LORO использовалась для определения точности декодирования для прогонов с линейными чертежами.
Чтобы увидеть, распространяется ли информация по категориям, полученная из паттернов активации, извлеченных из цветных фотографий, на линейные рисунки, мы немного изменили процедуру анализа.Как и раньше, классификатор SVM был обучен на данных активации fMRI из всех прогонов CP, кроме одного. Однако вместо того, чтобы тестировать его с данными из пропущенного прогона CP, классификатор был протестирован с данными fMRI из прогона LD, структура блока и изображения которого была такой же, как и у пропущенного прогона CP (перекрестное декодирование ). Анализ повторяли, так что каждый прогон CP был пропущен один раз, таким образом создавая прогнозы для каждого из прогонов LD. Точность декодирования снова оценивалась как доля правильных предсказаний метки категории сцены.Перекрестное декодирование от линейных рисунков к цветным фотографиям вычислялось аналогичным образом, обучая классификатор на всех прогонах LD, кроме одного, и тестируя его на прогоне CP, соответствующем оставленному прогону LD.
Поведенческий эксперимент.
В поведенческом эксперименте участников попросили оценить одну и ту же / другую категорию среди трех изображений, представленных в быстрой последовательной визуальной презентации. Стимулы предъявлялись на ЭЛТ-мониторе с разрешением 800 × 600 пикселей, увеличивая угол обзора 23 ° × 18 °.В начале каждого испытания белый крест фиксации был представлен в центре экрана на 50% сером фоне в течение 1000 мс. Затем была показана последовательность из трех изображений в полноэкранном режиме в быстрой последовательности в течение заданной продолжительности без промежутков, после чего следовало 1500 мс пустого экрана, чтобы участники могли ответить (рис. 5 A ). Первое и третье изображения представляют собой линейные рисунки двух различных природных сцен из одной категории. В половине испытаний второе изображение было еще одним рисунком линии из той же категории, а в другой половине — рисунком линии из другой категории.Участников попросили нажать «S» на клавиатуре компьютера, когда второе изображение было из той же категории, что и первое и третье, или «D», когда оно было из другой категории. Чтобы эффективно замаскировать критическое второе изображение, первое и третье изображения были показаны в виде белых линий на черном фоне, а второе изображение было показано черным на белом.
Эксперимент состоял из трех частей: практика, спуск по лестнице и тестирование. Во время практики и спуска по лестнице вторые изображения представляли собой неповрежденные линейные рисунки, а в качестве обратной связи для ошибочных ответов подавался тон.Время представления трех изображений систематически сокращалось с 700 мс до 300 мс во время практики. На последующем этапе построения лестницы время презентации было дополнительно сокращено за счет использования алгоритма лестничной клетки Quest (30) до достижения стабильного уровня точности 70%. Эта продолжительность презентации, определяемая индивидуально для каждого участника, затем использовалась на этапе тестирования. Среднее время презентации после лестничной клетки составило 175 мс (стандартное отклонение: 66 мс).
На этапе тестирования вторые изображения были ухудшенными версиями исходных линейных рисунков.Смежные наборы линий (контуров) на каждом чертеже были отсортированы по их общей длине. Ухудшенные версии линейных рисунков были получены путем исключения контуров, так что было удалено 50% или 75% пикселей, начиная с самых длинных или начиная с самых коротких контуров (Рис. 2 и Рис. S1). При необходимости отдельные линейные сегменты укорачивались или удалялись из контуров для достижения точного процента пикселей. Эти четыре типа деградации уравновешивались по целевой категории и по одинаковым / различным испытаниям для каждого участника.Точность измерялась как доля испытаний, в которых участники правильно ответили, нажав «S» для одних и тех же испытаний и «D» для разных испытаний.
Расшифровка 3 категорий общепринятых представлений в анализе подобия образов
Используйте этот идентификатор для цитирования или ссылки на этот элемент: http://arks.princeton.edu/ark:/88435/dsp012n49t431c
| Название: | Расшифровка 3 категорий общепринятой мудрости в анализе подобия образов | ||||||||
| Авторы: | Чоу, Майкл Энтони | ||||||||
| Советники: | Хассон, Ури Конвей, Эндрю Р.A. | ||||||||
| Составители: | Департамент психологии | ||||||||
| Ключевые слова: | ковариационный анализ fmri нейробиология анализ сходства паттернов психология психометрия | ||||||||
| Субъекты: | психология | ||||||||
| Дата выпуска: | 2017 | ||||||||
| Издатель: | Принстон, штат Нью-Джерси: Принстонский университет | ||||||||
| Аннотация: | Многие методы нейробиологии характеризуют общие паттерны активности посредством анализа ковариационных матриц.В зависимости от экспериментального дизайна и представляющих интерес измерений области этих анализов иногда называют функциональной связностью, анализом сходства паттернов или межпредметной корреляцией. Прогресс в этих областях привел к более глубокому пониманию мозга. Однако неожиданные свойства обычно используемых методов ковариации в этих областях ставят под сомнение общепринятое мнение, которое иногда мотивирует анализ. Хотя обычная практика усреднения парных корреляций внутри и между группами наблюдений может показаться простой, а сравнение этих средних внутри и между группами легко выполнить, исследователи часто полагаются на словесные объяснения того, что может означать такой контраст.В этой диссертации мы показываем, что эти словесные объяснения основаны на строгих допущениях и, как таковые, не имеют смысла без оговорок. Процедуры, которые выборочно усредняют группы перед корреляцией, или используют сложные формы разделения данных и корреляции между участками, основываются на одних и тех же — часто неявных — допущениях. В этой статье мы демонстрируем, что эти анализы можно рассматривать как частные случаи модели скрытых факторов, в которой предполагается, что все дисперсии скрытых факторов равны.Более того, эта модель не только способна объяснить такие процедуры, но и была изучена и распространена на социальные, медицинские и физические науки. В результате мы устанавливаем связи с аналогичными проблемами, обсуждаемыми в литературе по психологии поведения и психометрии. Первый раздел диссертации представляет собой эмпирическое исследование индивидуальных различий в рабочей памяти и интеллекте, в котором используется модель скрытых факторов, общая для психологии индивидуальных различий. Во втором разделе диссертации эта модель используется для оценки трех вышеупомянутых процедур в нейробиологии.Такая перспектива ценна, потому что она создает четкое соответствие между методологическими проблемами, которые были (и часто продолжают оставаться) широко распространенными в ковариационных анализах поведенческой психологии и их коллег в нейробиологии. | ||||||||
| URI: | http://arks.princeton.edu/ark:/88435/dsp012n49t431c | ||||||||
| Альтернативный формат: | В библиотеке рукописей Мадда хранится одна переплетенная копия каждой диссертации. Ищите эти копии в главном каталоге библиотеки: catalog.princeton.edu | ||||||||
| Тип материала: | Академические диссертации (Ph.D.) | ||||||||
| Язык: | en | ||||||||
| Встречается в коллекциях: | Психология | ||||||||
| Файл | Описание | Размер | Формат | |
|---|---|---|---|---|
| Chow_princeton_0181D_12204.pdf | 12,1 МБ | Adobe PDF | Просмотр / загрузка |
Элементы в Dataspace защищены авторским правом, все права сохранены, если не указано иное.
(PDF) Расшифровка категорий визуальных объектов в ранней соматосенсорной коре
полушарие(оба P> 0,29). Следовательно, имеется четкое свидетельство декодирования
знакомых визуальных объектов в правой S2, будь то использование
всей анатомической области или предварительный выбор вокселей
в зависимости от чувствительности к тактильной стимуляции контралатеральной руки. . Существует также слабое предположение о надежном эффекте распознавания незнакомых объектов
при объединении в полусферы
для вокселей, предварительно выбранных как функция чувствительности к стимуляции подушечкой пальца
.
Дополнительные области
Как и ожидалось в V1, декодирование устойчиво присутствовало во всех
штанах для обоих знакомых (Рис. 4D: справа V1: 97% t
(9)
= 49,1,
P <0,0001 ; слева V1: 96,8% t
(9)
= 55,2, P <0,0001; объединенный: 98%
t
(9)
= 76,6, P <0,0001) и категории незнакомых объектов
(рис. . 4D: справа V1: 95,6% t
(9)
= 30,1, P <0.0001; слева V1: 94%
t
(9)
= 22,7, P <0,0001; в совокупности: 96,5% t
(9)
= 35,6, P <0,0001). Чтобы выяснить, различается ли декодирование для знакомых и незнакомых
объектов-лжецов в V1, мы провели двухфакторный дисперсионный анализ с
факторами (регион и знакомство): в этом анализе не было значительных основных эффектов или взаимодействий
. хотя был тренд
(P = 0,065) для основного эффекта региона.Таким образом, декодирование
как знакомых, так и незнакомых объектов было одинаковым в V1, как и ожидалось.
Мы использовали вероятностные анатомические маски, чтобы определить местоположение
нескольких дополнительных контрольных областей в наших штанах
. Расшифровка знакомых визуальных объектов (рис. 4E) была значительной —
косяков как слева (37% t
(9)
= 2,68, P = 0,013), так и справа (36%,
t
(9 )
= 1,97, P = 0,04) премоторная кора, но не при объединении
(36%, t
(9)
= 1.41, P = 0,097). Однако в самой моторной коре не было надежного декодирования
(рис. 4F: все P> 0,14). Кодирование незнакомых объектов De-
не имело значения ни в одном двигателе
или в премоторной области (рис. 4E, F: все P> 0,41).
Чтобы выяснить, различалась ли производительность декодирования как функция знакомства и региона
, мы также выполнили один и тот же двухсторонний дисперсионный анализ
для каждого другого ROI: критически только 2 региона показали основной эффект знакомства
на производительность декодирования: в PCG
, но только при ограничении чувствительных к пальцу вокселей от стимуляции
обеими руками, F
1,9
= 7.29, P = 0,024, среднее знакомое 38%,
незнакомое 33%; а в премоторной коре F
1,9
= 5,75, P = 0,04,
означает знакомые 37%, незнакомые 33%. Никакие другие основные эффекты или
взаимодействий не были значимыми в этих или любых других ROI. Следовательно, декодирование
было достоверно выше для знакомых по сравнению с
категорий неизвестных объектов в этих двух областях мозга, предполагая, что
— это специфика предшествующих знаний.
Наконец, мы также провели 3-сторонний дисперсионный анализ со следующими
факторами: рентабельность инвестиций (PCG, S2, V1, премотор, мотор), знакомство (знакомое,
знакомое, незнакомое) и сторона (справа, слева, или объединены).Этот анализ
выявил только основной эффект ROI, F
4,36
= 586,07, P <0,0001.
Последующие t-тесты показали, что производительность декодирования в V1
была надежно выше, чем в каждой другой области
(все t> 29,9, все P <0,0001). Никакие другие эффекты не были значительными
(все P> 0,05), хотя наблюдалась несущественная тенденция
для декодирования в более высоком уровне в PCG, чем в моторной коре
(P = 0.0787).
Внутрикатегорийное декодирование в PCG и V1
Внутрикатегориальное декодирование не было значимым ни в одной области
PCG (все P> 0,05) для знакомых объектов, для любой конкретной категории объектов
независимо или при усреднении по категориям
(см. дополнительный рис. 5). Таким образом, это открытие соответствует эксперименту 1. Однако для незнакомых объектов было обнаружено
, что неожиданно оказалось значительным внутрикатегорийным декодированием в пределах
правой PCG (38%, t
(9)
= 2.44, P = 0,019) и при объединении по
полушариям (37%, t
(9)
= 1,97, P = 0,04), но не в левом PCG
(34%, t
(9)
= 0,29, P = 0,39) для анализа с усреднением по
категориям объектов. Результаты этого анализа при разделении на
категорий объектов ясно показывают, что этот эффект полностью обусловлен
категорией объектов «шипы» (см. Дополнительный рис. 5) и
, что, следовательно, для 2 из 3 категорий незнакомых объектов , не наблюдалось декодирования внутри категории
(«кубики» и «смузи»; см.
Дополнительный рис.5). Ниже мы обсуждаем особенности
, присутствующие в категории «колючие» объекты, которые делают его в restros-
pect менее чем идеальным контролем в данном эксперименте (см. Обсуждение
). Трехфакторный дисперсионный анализ (тип декодирования: между
ивнутри; область: слева, справа, объединенный; знакомство: знакомый, незнакомый —
лжец) показал, что не было никакой разницы между типами декодирования —
(между по сравнению с внутри; P = 0,52) или любые взаимодействия с этим фактором
.Был основной эффект области (F
2,18
= 4,02, P = 0,036)
с общим декодированием, более высоким в правой, чем левой PCG.
В V1, как и ожидалось, декодирование внутри категории снова было
очень значимым для знакомых объектов (справа: 64%, t
(9)
= 7,22,
P <0,0001; слева: 58%, t
(9)
= 6,78, P <0,0001; объединенные: 64%,
т
(9)
= 7,04, P <0,0001). Такая же картина наблюдалась и для
незнакомых объектов (справа: 68%, t
(9)
= 8.35, P <0,0001; слева: 65%,
t
(9)
= 8,28, P <0,0001; в совокупности: 70%, t
(9)
= 10,26, P <0,0001). Кодирование De-
было выше для между (96%), чем внутри (65%) категорий
(F
1,9
= 141,56, P <0,001) классификаций в V1. Кроме того,
было взаимодействием между типом декодирования и фамилией —
арность (F
1,9
= 10,78, P = 0,009), причем декодирование между категориями
было немного лучше для знакомых, чем для незнакомых объектов. но декодирование внутри категории
немного лучше для незнакомых объектов
.Также наблюдалось взаимодействие между типом декодирования
и регионом (F
2,18
= 4,7, P = 0,023) из-за большего уменьшения кодирования de-
в левом V1 по сравнению с правым V1 (или объединенным) для внутрикатегорийного декодирования — не
.
Анализ всего мозга
На рис. 5B, C показаны результаты анализа света в целом
независимо для знакомых и незнакомых
категорий визуальных объектов в эксперименте 2.Широкая схема декодирования
схожа в обоих случаях: обширная область зрительной коры
, простирающаяся на височную и теменную кору, имеет очень высокую точность кодирования
. Имеются доказательства надежного декодирования в
SPOC, а также по IPS и верхней теменной доле
, как в эксперименте 1. Однако этот паттерн в целом аналогичен
как для знакомых, так и для незнакомых категорий объектов. Обнаружение
знакомых объектов хорошо согласуется с результатами эксперимента 1 в
терминах зрительной и теменной коры, хотя нет никаких доказательств достоверного декодирования вокруг постцентральной борозды /
постцентральной извилины в эксперименте 2. для знакомых предметов.В добавлении
меньше областей обнаруживается во фронтальных областях в Exper-
iment 2 для знакомых объектов (только левая дорсолатеральная префронтальная
и правая премоторная кора). Для увеличения мощности мы
объединили наши данные из экспериментов 1 и 2 в знакомых условиях объекта
(рис. 5D). Этот анализ выявил высокий уровень декодирования по всей зрительной коре, снова распространяющийся на заднюю
теменную (SPOC, IPS, SPL) кору, все области, важные для зрительного контроля моторики (например,
).