Категории водительских прав 2016 и их расшифровка
Расшифровка категорий водительских прав
Под категорией водительских прав подразумевается группа транспортных средств, которыми может управлять человек, имеющий водительское удостоверение. Управляя транспортом, на которое нет разрешения, вас могут оштрафовать и взыскать штраф, предусмотренный законом страны. Поскольку новые водительские права, которые были выпущены в 2016 году, имеют некоторые изменения, прежде чем сесть за руль автомобиля, водитель должен ознакомиться с поправками. В противном случае можно оказаться в очень неприятной ситуации.
Что можно увидеть на удостоверении?
Как любой документ, водительские права обладают лицевой и обратной стороной. Что можно увидеть на лицевой стороне?
- Название документа и название страны, которая его выдала можно увидеть в самом верху.
-
Фотография владельца размещается с левой стороны.

- Под фотографией стоит подпись владельца. Она должна быть такой, как на всех остальных документах.
- Справой стороны можно увидеть инициалы владельца и транслитный перевод.
- Ниже – сведения о месте и дате рождения.
- В следующей строчке можно увидеть «срок годности» документа и дату выдачи.
- Еще ниже – организацию, которая выдала документ.
- 5 строчка – серия и номер.
- Регион проживания.
- В самом низу – категории.
На заметку: до появления новых прав, старые имели только 5 общепринятых категорий: А, В, С, D, Е.
Теперь об обратной стороне водительских прав.
-
Штрих-код, размеров 10 на 42 см, содержащий личную информацию о владельце можно увидеть с левой стороны документа.
- Под штрих-кодом, в последней строчке указаны личные сведения водителя и ограничения для общих категорий.
- Таблица, с размещением категории водительских прав размещена справа.

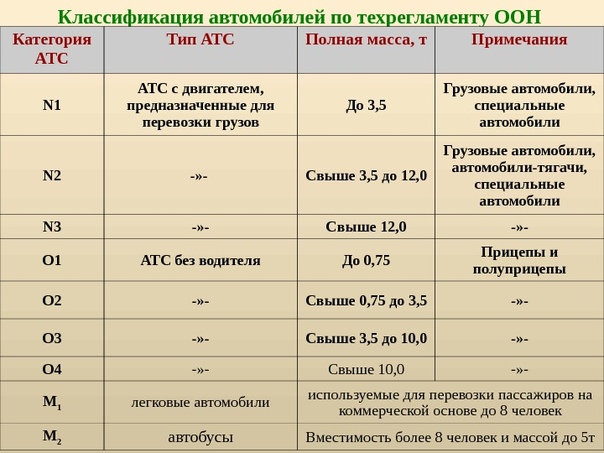
Категории
«А» — Позволяет ездить на двухколесных мотоциклах с прицепом и без него. Сюда относятся также трех и четырехколесные машины, вес которых не больше 400 кг.
«С» — Имея данную категорию, можно управлять машинами, вес которых больше 3,5 т. и сцепленными прицепами до 750 кг.
«D» — Позволяет управлять машинами, которые имеют больше 8 мест, не считая сиденья для водителя. Под эту категорию попадают различные виды автобусов.
«М» — Можно ездить на квадроциклах и мопедах.
«Tm и Тb» — Нужна для управления троллейбусами и трамваями.
«ВЕ» — Дает право управлять транспортными средствами массой, не превышающей 3,5 т м прицепами.

«СЕ» — Почти ничем не отличается от категории «ВЕ», но позволяет управлять машинами из категории «С». Масса прицепа – не больше 750 кг.
«DЕ» — Позволяет управлять автобусами. Количество мест – больше 8. Разрешается наличие прицепа массой до 3,5 т.
Подкатегории
«А1» — Разрешается управление скутером.
«В1» — Можно водить машину, массой 550 кг. Скорость – 50 км/ч.
«С1» — Позволяет управлять автомобилем, масса которого от 3,5 до 7,5 т. Разрешен прицеп – масса до 750 кг.
«D1» — Позволяет управлять машинами, способными перевозить до 16 пассажиров.
«D1Е» — Можно ездить на автомобилях из категории «С», а также и прицепом.
Категории водительских прав: расшифровка 2019 года
Водительское удостоверение категории А
Итак, категория А – это разрешение управлять любыми мотоциклами, включая оснащенными боковым прицепом (коляской). Согласно Правилам дорожного движения, категория А также разрешает управлять трех- и четырехколесными транспортными средствами снаряженной массой не более 400 кг.
Согласно Правилам дорожного движения, категория А также разрешает управлять трех- и четырехколесными транспортными средствами снаряженной массой не более 400 кг.
Подкатегория А1 – условно «младшая», допускающая езду на мотоциклах с объемом двигателя не более 125 куб. см и мощностью, не превышающей 11 кВт. Кстати, подкатегорию А1 разрешается открывать в 16 лет и, разумеется, те, у кого в водительском удостоверении открыта категория «А», могут управлять техникой подкатегории А1.
Водительское удостоверение категории B
Самая распространенная категория B. Согласно определению ПДД это «автомобили (за исключением транспортных средств категории «А»), разрешенная максимальная масса которых не превышает 3500 килограммов и число сидячих мест которых, помимо сиденья водителя, не превышает восьми; автомобили категории В, сцепленные с прицепом, разрешенная максимальная масса которого не превышает 750 килограммов; автомобили категории В, сцепленные с прицепом, разрешенная максимальная масса которого превышает 750 килограммов, но не превышает массы автомобиля без нагрузки, при условии, что общая разрешенная максимальная масса такого состава транспортных средств не превышает 3500 килограммов».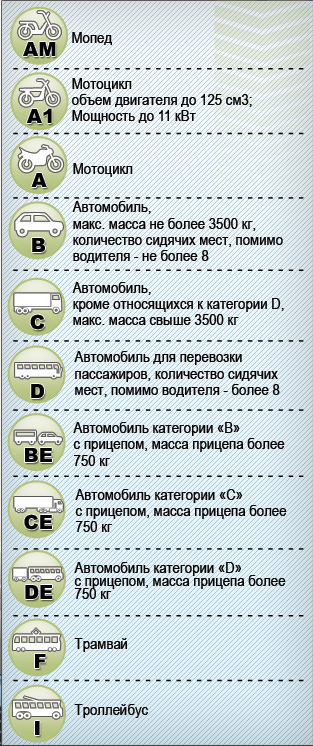 То есть, сюда относятся легковушки, легкие грузовики и микроавтобусы, а также мотоколяски и автомобили с прицепом, разрешенная максимальная масса которого не более 750 кг. Главное, чтобы разрешенная максимальная масса прицепа не превышала массу машины без нагрузки, а их суммарная масса не выходила за пределы 3,5 тонн.
То есть, сюда относятся легковушки, легкие грузовики и микроавтобусы, а также мотоколяски и автомобили с прицепом, разрешенная максимальная масса которого не более 750 кг. Главное, чтобы разрешенная максимальная масса прицепа не превышала массу машины без нагрузки, а их суммарная масса не выходила за пределы 3,5 тонн.
Водительское удостоверение категории BE
Если есть необходимость таскать за собой тяжелый прицеп массой более 750 кг и превышающей массу автомобиля без нагрузки, то потребуется категория BE. Также она позволяет управлять автомобилями категории В с прицепами, разрешенная максимальная масса которых превышает 750 килограммов, при условии, что общая разрешенная максимальная масса такого состава транспортных средств превышает 3500 килограммов.
Подкатегория B1 открывает доступ к трициклам и квадрициклам.
Водительское удостоверение категории М
Раз уж зашла речь о «квадриках», то следует упомянуть и эту категорию для мопедов и легких квадрициклов. Она же по умолчанию является открытой для тех, у кого открыта любая категория.
Она же по умолчанию является открытой для тех, у кого открыта любая категория.
Водительское удостоверение категории С
Это – та самая «грузовая» категория, дающая право на управление серьезными транспортными средствами: средними (разрешенной максимальной массой от 3500 кг до 7500 кг) и тяжелыми (более 7500 кг) грузовиками, а также грузовиками с прицепом, разрешенная максимальная масса которого не превышает 750 кг. Важный момент — категория C не разрешает ездить на небольших (меньше 3500 кг) грузовиках и легковушках.
Водительское удостоверение категории СE
Категория CE нужна для езды с тяжелым (более 750 кг) прицепом или полуприцепом.
Подкатегория С1 – это средние грузовики, разрешенной максимальной массой от 3 500 до 7 500 кг. Она же допускает езду с легким прицепом массой до 750 кг. Соответственно, при открытой категории С можно управлять машинами подкатегории С1.
Наконец есть подкатегория С1Е, введенная для транспортных средств С1 с тяжелыми прицепами массой более 750 кг, но суммарной разрешенной максимальной массой грузовика и прицепа не более 12 тонн. Управлять транспортными средствами подкатегории C1E можно с открытой категорией СЕ.
Управлять транспортными средствами подкатегории C1E можно с открытой категорией СЕ.
Водительское удостоверение категории D
Разрешает управлять автобусами самых разных размеров и без привязки к разрешенной максимальной массе, а также автобусами с прицепом, разрешенной максимальной массой не более 750 кг. Впрочем, есть и исключения – категория D не позволяет ездить на сочлененных автобусах, известных как автобусы с «гармошкой».
Водительское удостоверение категории DE
Это автомобили категории D с прицепом, разрешенная максимальная масса которого превышает 750 килограммов, а также сочлененные автобусы.
Есть и две подкатегории – D1 и D1E. Первая введена для автомобилей, предназначенных для перевозки пассажиров и имеющие более восьми, но не более шестнадцати сидячих мест, помимо сиденья водителя, а также для машин с прицепом, разрешенной максимальной массой до 750 кг. Вторая же — автомобили подкатегории D1 с прицепом, не предназначенные для перевозки пассажиров, разрешенной максимальной массой свыше 750 кг, но не более массы автомобиля без нагрузки, при условии, что общая разрешенная максимальная масса такого состава транспортных средств не превышает 12 000 кг.
Водительское удостоверение категории Tm и Tb
Специфичные категории для трамваев Tm и троллейбусов Tb.
Категории водительских прав | Новые категории водительских прав
В соответствии со статьей 2.1.1 ПДД Российской Федерации, в 2021 году человек, который управляет автомобильным транспортом, обязан иметь документы, удостоверяющие личность, и бумаги, подтверждающие право управления автомобилем соответствующей категории или подкатегории. Все категории водительских прав обладают своими уникальными параметрами. Теория вождения все время обновляется, поэтому сегодня поговорим о нововведениях следующего года.
Какие будут категории прав в 2021 году
Категория, указанная в удостоверении – это указание на тип транспортного средства, которым может управлять человек. С каждым годом появляются новые категории водительских прав.
В 2021 году утверждено пять основных групп:
- А – мототранспорт;
- В – легковые автомобили;
- С – грузовые авто;
- D – автомобильный транспорт для перевозки пассажиров;
- М – мопеды и прочие транспортные средства, имеющие небольшую мощность.

Расшифровка категорий водительских прав
Каждая категория и подкатегория имеет свои индивидуальные требования к автомобильному транспорту. Расшифровка категорий водительского удостоверения приведена ниже.
A
Транспортное удостоверение категории А разрешает управлять следующим мототранспортом:
- мотоколяски;
- мотоциклы;
- мотоциклы с мотоприцепами.
Под определение мотоцикла подходит двухколесный транспорт, имеющий объём двигателя от 50 кубических сантиметров и максимальную скорость более пятидесяти км/ч. Допускается наличие боковой коляски. Ещё к мотоциклам относятся трёхколесные и четырехколесные средства передвижения, масса которых не превышает 0,4 т. без учета аккумулятора.
A1
Литер А1 разрешает управлять только мотоциклами. Эти удостоверения выдаются для управления скутером или квадроциклом. Транспорт должен соответствовать следующим характеристикам:
- мощность до одиннадцати киловатт;
- объём двигателя от 50 до 125 кубов;
- отсутствие мотоприцепа.

B
В категорию В входит легковой автотранспорт. Он должен соответствовать следующим требованиям:
- масса не более трех с половиной тонн;
- девять сидячих мест вместе с креслом водителя;
- возможно наличие груза до 0,75 т.;
- прицеп может иметь больший вес, но тогда он должен быть меньше авто.
BE
- вес более 0,75 т.;
- общая масса больше 3,5 т.;
- масса груза больше массы автомобиля без нагрузки.
Для получения ВЕ требуется сдача дополнительного экзамена, так как удостоверение относится к отдельной группе.
B1
Это подкатегория, которая появилась сравнительно недавно. В официальных документах практически нет четкой информации о том, что подходит под определение этого авто. В статье 25 ФЗ№196 указано, что сюда относятся трициклы и квадроциклы.
C
В категорию С включены грузовые машины разнообразной вместимости:
- массой от трех с половиной тонн;
- машины с прицепом меньше 0,75 т.
Литера С включает в себя весь автомобильный транспорт, применяющейся для грузоперевозок.
CE
Категория СЕ включает в себя автотранспорт с прицепом более 0,75 т. Т/С обязывает иметь определенные навыки управления, потому что сложно совершать маневры на таком тяжелом автомобиле. Существует запрет на движение по некоторым трассам.
C1
В С1 входят облегченные транспортные средства для грузоперевозок. Параметры для этих автомобилей:
- автомобиль с грузом до 0,75 т.
Когда гражданин получает права категории С, то С1 ставится автоматом. В 2021 году появляется возможность сдать на подкатегорию С1 отдельно.
C1E
Сюда относятся машины с прицепом, к которому имеются чёткие требования. Это более лёгкий вариант СЕ, ведь здесь масса прицепа может быть больше 0,75 т, но только при соблюдении следующих условий:
Это более лёгкий вариант СЕ, ведь здесь масса прицепа может быть больше 0,75 т, но только при соблюдении следующих условий:
- общий вес менее двенадцати тонн;
- вес груза не должен превышать массу основного автомобиля без нагрузки.
Подкатегория получается при сдаче на СЕ, но существует возможность сдать на нее отдельно.
D
D – это автомобильный транспорт, предназначенный для перевозки пассажиров. Основной упор прав – число сидячих мест. Здесь присутствуют определенные требования по массе.
Трамваи и троллейбусы не входят в эти водительские категории.
DE
Буква Е обычно говорит о наличии прицепа, но на дорогах крайне редко встречаются пассажирские автобусы с прицепом для грузов. В основном к этой подкатегории относятся сочлененные автобусы.
D1
В эту подкатегорию включены маршрутки, в которых находится от 9 до 17 мест вместе с водительским сидением. Этот автомобильный транспорт может иметь прицеп для перевозки грузов, весом в 0,75 т.
D1E
К этой подкатегории имеют отношения различные пассажирские транспортные средства, которые обладают следующими параметрами:
- от девяти до семнадцати сидячих мест, включая место водителя;
- общий вес автомобиля с грузом не должен превышать двенадцать тонн;
- имеется специальный прицеп для перевозки различных грузов менее 0,75 тонн.
M
Эта группа появилась с недавних пор и разработана для регулирования езды на мопедах. В 2021 году сюда входят легкие квадроциклы.
Мопед – это вид двухколесного или трехколесного транспортного средства, соответствующего следующим параметрам:
- максимальная скорость – не более пятидесяти километров в час;
- объем двигателя – до пятидесяти сантиметров в кубе;
- мощность до четырёх киловатт.
Удостоверение с пометкой М получается при сдаче на права на абсолютно любой другой вид прав. Стоит заметить, что помимо мопедов сюда включены электрические велосипеды и остальные средства передвижения.
Tm
В эту категорию входят трамваи. Можно управлять как одинарными, так и сочлененными моделями.
Tb
Сюда относятся троллейбусы. Как и Tm можно использовать права для управления сочлененными и одинарными транспортными средствами.
В статье были рассмотрены требования ко всем категориям водительских прав. Важно, чтобы транспортное средство подходило под указанные параметры.
Расшифровка категорий водительских прав | Пдд онлайн
Здравствуйте, уважаемый автолюбитель!
Из этой статьи вы узнаете, какое отношение имеют категории водительских прав к автомобилям или на какие категории подразделяют транспортные средства. Чтобы начать управлять автомобилем, не достаточно просто получить права и начать ездить. Права нужно получить с определенной категорией.
Например, если вы хотите управлять мотоциклом, то и права должны быть с открытой категорией на право управления мотоциклами. Если хотите управлять легковым автомобилем, категория должна быть соответствующая — на право управления легковыми автомобилями. А для грузовиков и автобусов идут уже отдельные категории. Ну а теперь давайте приступим к расшифровке категорий водительских прав.
А для грузовиков и автобусов идут уже отдельные категории. Ну а теперь давайте приступим к расшифровке категорий водительских прав.
Категории водительского удостоверения обозначаются латинскими буквами. И самая первая категория начинается с первой буквы алфавита — A!
Категория A
Водительское удостоверение с отметкой «категория А» — подтверждает наличие права на управление мотоциклами, мотороллерами и другими мототранспортными средствами. Давайте обратимся к общим положениям ПДД, там написано, что «Мотоцикл» — двухколесное механическое транспортное средство с боковым прицепом или без него. К мотоциклам приравниваются трех- и четырехколесные механические транспортные средства, имеющие массу в снаряженном состоянии не более 400 кг.
Также имеется подпункт категории А, используемый для обозначения мотоциклов, количество которых не превышает 15 лошадиных сил. У таких мотоциклов, объем двигателя не превышает 125 см3. И использование таких мотоциклов разрешено с 16-ти лет.
Итак, категория «A» разрешает управлять мотоциклами.
Категория B
Водительское удостоверение с отметкой «категория В» — подтверждает наличие права на управление автомобилями, разрешенная максимальная масса которых не превышает 3500 килограммов и число сидячих мест, помимо сиденья водителя, не превышает 8. То есть вы можете управлять легковыми автомобилями, джипами и небольшими микроавтобусами. Но их разрешенная максимальная масса не должна быть более 3,5 тонн и число сидячих мест не должно быть более 8-ми, иначе это уже категория «C» или «D».
В дополнение, существует категория B1 описывающие транспортные средства с мотоциклетным мотором, массой не превышающей 550 кг и объемом двигателя до 50 см3.
С данной категорией вы можете подцепить прицеп к вашему автомобилю. Но разрешенная максимальная масса прицепа не должна превышать 750 кг, иначе это уже категория «E». Кроме этого, вам можно управлять мототранспортом масса которого превышает 400 кг.
Итак, категория «B» разрешает управлять легковыми автомобилями.
Категория C
Водительское удостоверение с отметкой категория «С» — подтверждает наличие права на управление автомобилями, за исключением относящихся к категории «D», разрешенная максимальная масса которых превышает 3500 килограммов. Эти автомобили называются грузовики. Но опять же, число сидячих мест, помимо сиденья водителя, не должно превышать 8. Так же как и в категории «B», вы можете подцепить прицеп с разрешенной максимальной массой не более 750 кг.
Подпункт категории С, который применяется к грузовым транспортным средствам общей массой от 3500 до 7500кг, обозначаемой категорией С1.
Категорией CE обозначается грузовой транспорт с прицепом, весом не более 750 кг.
И, в завершение, категорией C1E обозначается грузовой транспорт с прицепом, массой от 3500 до 7500 кг.
Итак, категория «C» разрешает управлять грузовыми автомобилями.
Категория D
Почитав предыдущие категории, вы уже поняли, что категория Д напрямую зависит от количества сидячих мест в транспортном средстве. Водительское удостоверение с отметкой категория «D» — подтверждает наличие права на управление автомобилями, предназначенными для перевозки пассажиров и имеющими более 8 сидячих мест, помимо сиденья водителя. То есть с категорией Д вы можете управлять любыми автобусами, причем не зависимо от разрешенной максимальной массы. И опять же, вы можете прицепить к автобусу прицеп, но с разрешенной максимальной массой не более 750 кг, иначе это уже следующая и последняя категория Е.
Также, имеется категория D1 описывающие автобусы малой вместимости, с количеством сидячих от 8 до 16 мест.
И, есть категория D1E применяющаяся к автобусам малой вместимости с прицепом, чей вес превышает 750 кг.
Итак, категория «D» разрешает управлять автобусами.
Категория E
Водительское удостоверение с отметкой категория «Е» — подтверждает наличие права на управление составами транспортных средств с тягачом, относящимся к категориям «В», «С» или «D», которыми водитель имеет право управлять, но которые не входят сами в одну из этих категорий или в эти категории.
Но чтобы открыть категорию «Е», у вас должны быть открыта одна из категорий (или все) B,C,D. То есть категория «Е» идет как дополнение к основным категориям. При получении категории «Е» в графу «Особые отметки» проставляются следующие отметки: E-B, E-C, E-D, E-BC, E-BD, E-CD, E-BCD. В предыдущих категориях упоминалось о прицепе. Так вот, в зависимости от того, к какому транспортному средству будет подцеплен прицеп, соответственно будет проставлена отметка.
Категория E разрешает управлять транспортными средствами:
«E-B» — с прицепом, разрешенная максимальная масса которого по крайней мере 1000 кг, а разрешенная максимальная масса состава транспортных средств превышает 3500 кг.
«E-C» — с полуприцепом или прицепом, имеющим не менее двух осей с расстоянием между ними более 1 м. «E-D» — на сочлененном автобусе.
Комбинации E-BC, E-BD, E-CD, E-BCD дают возможность управлять транспортными средствами из двух или трех подкатегорий.
Итак, категория «E» разрешает управлять транспортными средствами с прицепом.
Теперь мы знаем, на какие категории делятся транспортные средства и какие категории должны быть открыты в правах для конкретного вида транспорта. Но имейте в виду, что имя водительское удостоверение с одной категорией, например «C» (грузовики), вы не имеете право управлять легковыми автомобилями, для этого уже нужна категория «B».
В общем, чтобы управлять определенным видом транспорта, вам нужно открыть соответствующую категорию водительского удостоверения. Ну а если у вас в водительском удостоверении одна категория, а автомобиль, которым в управляете, относится к другой категории, то за это предусмотрен штраф!
На этом все, желаю вам успехов!
Содержание статьи:
- расшифровка категорий водительских прав
- водительские категории
- расшифровка водительского удостоверения
- тюфшЄхы№ёъшх ърЄхуюЁшш
Категории водительских прав в 2020 году
Категория в правах формирует конкретную группу транспортных средств (ТС) право управлять которой имеет владелец водительского удостоверения.
С 5 ноября 2013 года вступили в силу изменения в закон «О безопасности дорожного движения», которые не только изменили перечень категорий водительского удостоверения, но и добавили совершенно новые подкатегории.
Новые категории водительских прав 2019 года — их расшифровка и классификация
Имеющиеся категории классифицируются на 7 основных:
- «A» — мотоциклы;
- «B» — легковые автомобили;
- «C» — грузовые автомобили;
- «D» — автобусы;
- «Tm, Tb» — тролебусы, трамваи;
- «M»— мопеды и скутеры;
- специальные категории «BE», «CE», «DE», «C1E», «D1E» дающие право на управление ТС с прицепом.
И 4 группы подкатегорий: «A1», «B1», «C1», «D1».
Рассмотрим подробнее каждую категорию/подкатегорию водительских прав и выясним их особенности использования для управления конкретным транспортным средством.
Категория «А» — мотоцикл
Категория «А» дает право управлять любым типом мотоциклов, в их числе — оборудованных коляской.
Кроме вышесказанного, категории «A» разрешает управлять мотоколяской (если кто-то еще помнит что это).
Напомним: в соответствии с ПДД, мотоцикл – двухколесное транспортное средство без бокового прицепа либо с ним. Категория «А» разрешает управлять трехколесным либо четырехколесным транспортным средством массой менее 400 килограмм в снаряженном состоянии.
Подкатегория «А1»
К этой подкатегории причисляют мотоцикл с объемом двигателя не более 125 см. куб., а мощностью – не более 11 кВт.
Эта подкатегория, грубо говоря, относится к мотоциклам с небольшим двигателем и невысокой мощностью.
Отметим, что человек с правами в которых категория «А» открыта может законно управлять и ТС по категории «А1».
Категория «M» — мопед / легкий квадрицикл
С 05.11.13 определена новая категория «М» для мопеда и легкого квадрицикла.
Если у человека есть права в принципе с любой открытой категорией – у него есть законное право на управление по категории «М».
Нюанс: удостоверение тракториста-машиниста права на управление обозначенными мопедами не дает.
Категория «В» — легковой автомобиль
Категория «В» в водительском удостоверении разрешает управление легковым авто и небольшими джипами/ микроавтобусами/ грузовиками, отвечающим таким требованиям:
- категория «В» — машина (за исключением ТС по категории «А») массой не более 3,5 тонны, числом мест (сидячих) не более восьми, не включая водительского;
- автомобиль категории «В» в связке с прицепом весом не более 750 кг;
- автомобиль категории «В» в связке с прицепом весом более 750 кг, но массы машины без нагрузки он не превышает, а также с условием того, что масса состава автомобиль плюс прицеп не более 3,5 тонны.
Категория «B», в том числе, разрешает управление мотоколяской, а также еще и машиной с прицепом весом не более 750 кг.
В случае если прицеп весит более 750 кг – к такому составу предъявляют дополнительные требования, а именно:
- Нагруженный прицеп не может весить больше чем машина без нагрузки;
- Разрешенный максимальный вес состава «автомобиль плюс прицеп» не может быть более 3,5 тонн.
Категория «BE» — тяжелый прицеп
Чтобы управлять машиной категории «B» в связке с тяжелым прицепом, человек должен получить категорию «BE»:
- «ВЕ» – авто категории «В» в связке с прицепом весом более 750 кг и который весит более чем сама машина без нагрузки;
- ТС категории «В» в связке с прицепом массой более 750 кг, но с условием того, что вес состава «автомобиль плюс прицеп» не должен превышать 3,5 тонн.
Подкатегория «B1» — трицикл / квадрицикл
На данный момент мы готовим подробный данные для подкатегории «B1». Ждите обновленной информации.
Сразу уточним: «квадрИцикл» и «квадрОцикл» технически разные понятия. В силу этого водительские права для квадроцикла не подходят для управления квадрициклом.
Сразу уточним: «квадрИцикл» и «квадрОцикл» технически разные понятия. В силу этого водительские права для квадроцикла не подходят для управления квадрициклом.
Категория «С» — грузовой автомобиль
Категория «C» нужна водителю для управления грузовиком весом более 3500 кг:
- категория «С» – автомобиль (кроме транспорта из категории «D») весящий более 3,5 тонн;
- машины категории «С» в связке с прицепом весом не более 750 кг.
Человек с правами категории «С» может водить только средние и тяжелые грузовики (3500-7500 кг и более 7500 кг, соответственно), а также грузовую машину с прицепом весом не более 750 кг.
Стоит обратить внимание что категория «C» абсолютно не дает водителю прав на управление небольшим грузовиком (менее 3,5 тонн) и легковой машиной.
Водительские права категории «СE» — с тяжелым прицепом
Категория «CE» пригодится водителю с открытой категорией «С» для управления автомобилем с тяжелым прицепом (больше чем 750 кг).
Подкатегория «С1»
Чтобы иметь право управлять грузовым автомобилем с весом 3,5-7,5 тонны, человек должен иметь права с действующей категорией «C1»:
- подкатегория «С1» — машины (кроме авто категории «D») с массой более 3500 килограммов, но менее 7500 килограммов;
- авто подкатегории «С1» в связке с прицепом который весит не больше чем 750 килограмм;
- к этой подкатегории относятся также и средние грузовики массой в пределах 3500-7500 кг
- подкатегория разрешает управлять связкой с легким прицепом весом до 750 кг.
Открытая категория «С» разрешает управлять машинами и по категории «С1».
Подкатегория «С1E» — тяжелый прицеп
Дополняющая подкатегория «C1E» характеризует автомобили категории «С1», однако уже весящими более 750 кг (тяжелыми прицепами). Согласно ПДД, в таком случае общий вес всего состава не должен быть более 12 тонн.
Водители со старшей подкатегорий «CE» имеют право управлять грузовиками, относящимся к категории «C1E».
Категория «D» — автобус
Чтобы иметь право управлять автобусами, человек должен обладать водительскими правами по категории «D»:
- категория «D» — транспорт перевозящий пассажиров с более чем 8 сидячими местами. Водительское место в общее число мест не входит;
- транспорт категории «D» в связке с прицепом, весящим не больше чем 750 килограмм.
Категория «D» дает право управления автобусами различных типоразмеров не зависимо от их массы, в том числе связкой «автобус плюс прицеп» с максимальный весом последнего не более 750 кг. В том случае если масса самого прицепа более 750 кг – необходима открытая категория «DE».
Категория «DE»
«DЕ» – транспорт из категории «D» в связке с прицепом весящим более больше чем 750 килограммов. Сюда же причислен сочлененный автобус.
Подкатегория «D1»
- подкатегория «D1» — автомобиль для транспортировки пассажиров имеющий больше 8 и меньше 16 сидячих мест, не включая водительское сиденья;
- автомобиль подкатегории «D1» в связке с прицепом весом не более 750 килограмм;
Такая подкатегория разрешает управлять маленьким автобусом ( от 9 до 16 мест), а также эксплуатировать легкий прицеп (вес — менее 750 кг).
Подкатегория «D1E» — тяжелый прицеп
Если есть необходимость использовать более тяжелые прицепы – нужна будет подкатегория «D1E» для водителя автобуса:
- подкатегория «D1Е» — машины подкатегории «D1» в связке с прицепом, весящим не больше чем 750 килограмм и который не эксплуатируется для перевозки людей. Масса прицепа не должна быть больше массы самого основного транспорта без нагрузки и общая масса такой сцепки не должна быть больше 12 тонн.
Категория «D» разрешает водителю управлять ТС из категории «D1», а «DE» – из категории «D1E».
Категория «E»
На сегодня категории «E» уже не существует. Ее заменили охарактеризованные выше, категории BE, CE, C1E, DE, D1E.
В том случае если вас интересует обмен старого удостоверения с категорией «Е» — читайте наш материал «Перенос категории E в новые права«.
Категория «Tb» / «Tm» — трамвай /троллейбусы
Чтобы управлять трамваем или троллейбусом, начиная с 2016 года и уже в 2019 году, человеку потребуются права со специальной категорией «Tb» / «Tm».
Все ещё остались вопросы?
Задавайте Ваши вопросы здесь и наш автоюрист БЕСПЛАТНО ответит на все Ваши вопросы.
Последнее обновление: 04-09-2020
Расшифровка всех категорий на водительских правах 2018
В последние годы правительство значительно расширило список категорий в правах водителя, которые позволяют садиться за руль разного транспорта. Кроме того, существуют ещё и подкатегории. Водителям, давно получившим права, легко запутаться в таком разнообразии, что может привести к крупному штрафу за езду на машине без открытой категории.
Что у вас в правах?
Не так давно появилось документ водителя нового образца, оно стало меньше по размеру и удобнее. На лицевой стороне размещен цветной снимок, автомобилисты, носящие очки, должны обязательно фотографироваться в них. Также там находятся сведения о водителе, такая как: Ф.И.О, дата и место рождения, когда и кем выданы права, а также номер. Внизу перечислены открытые водителем категории, но более подробная информация по ним расположена на обратной стороне документа.
Какие бывают категории?
На обратной стороне прав есть табличка, где отмечены все доступные автомобилисту категории транспорта. Самая первая категория – это «А». Она позволяет садиться за руль мотоцикла с коляской или без него. Мотоцикл не должен превышать вес в 400 кг и может иметь два, три или четыре колеса. Получить такое удостоверение можно совершеннолетним. Следующая подкатегория «А1» разрешает управлять только лёгкими мотоциклами, с объёмом мотора до 125 см3. Её открыть можно уже в 16 лет. Ещё существует подкатегория «М» – она разрешает ездить на маленьких мопедах и квадрициклах, чтобы её открыть нужно сдать на любую другую категорию.
Далее идёт самая популярная категория – «В», она даёт право водить легковушки весом до 3,5 тонн, в салоне которых убирается не больше 8 человек. С этой категорией можно таскать прицепы с грузоподъёмностью не больше 750 кг. Если нужно увести в прицепе больший груз, то придётся открывать дополнительную категорию – «Ве». Также есть категория «В1» – она позволяет водить квадрициклы и трициклы с движком не более 50 см3. Получить все эти категории можно, начиная с совершеннолетия.
Тяжёлая техника
Следующая категория «С» разрешает садиться за баранку машин, масса которых может превышать 7,5 тонны, чаще всего это большие грузовики. Обычная категория разрешает возить небольшой прицеп грузоподъёмностью 750 кг, для более солидных прицепов нужна категория «Се». Также существуют подкатегории «С1» и «С1е» – они отличаются тем, что позволяют управлять только более «лёгкими» грузовиками, вес которых не превышает 7,5 тонн. Получить такие права можно по достижении 18 лет.
Чтобы стать водителем автобуса, нужно открыть категорию «D» – она разрешит водить машины, в которых установлено больше 16 посадочных мест. При необходимости перевозки большого прицепа придётся открывать ещё и категорию «De». Для тех, кто собирается ездить на небольшом автобусе, создана категория «D1» и «D1е». Они позволяют управлять машинами с количеством посадочных мест от 8 до 16, а также с прицепом до 750 кг. Открыть эти категории можно всем, кто старше 21 года.
В том случае, если вы решите попробовать себя в профессии водителя трамвая или троллейбуса, то вам придётся сдавать на категории «Тв» и «Тм». Так же, как и с автобусом, сделать это могут только те, кто уже достиг возраста в 21 год.
Еще одна возможность водить?
Чтобы получить право управлять более серьёзной техникой, чем легковой автомобиль, придётся заново учиться в автошколе и опять сдавать все экзамены. Такая необходимость может возникнуть не только, когда водитель решил устроиться на работу водителем грузовика или автобуса. Есть и те, кто покупает большие машины в личное пользование, например, полноприводный грузовик «Садко» берут, чтобы ездить на охоту. Придётся переучиваться, чтобы получить права на мотоцикл, даже если у вас уже есть категория «В» в удостоверении. Также стоит учитывать, что нельзя сразу открыть подкатегорию «е», которая позволяет водить машину с большим прицепом, перед этим нужно несколько лет отъездить в основной категории.
Фото с интернет-ресурсов
|
СРОТКЛ |
Возвращает среднее арифметическое абсолютных значений отклонений точек данных от среднего. |
|
СРЗНАЧ |
Возвращает среднее арифметическое аргументов. |
|
СРЗНАЧА |
Возвращает среднее арифметическое аргументов, включая числа, текст и логические значения. |
|
СРЗНАЧЕСЛИ |
Возвращает среднее значение (среднее арифметическое) всех ячеек в диапазоне, которые удовлетворяют заданному условию. |
|
Функция СРЗНАЧЕСЛИМН
|
Возвращает среднее значение (среднее арифметическое) всех ячеек, которые удовлетворяют нескольким условиям. |
|
БЕТА.РАСП
|
Возвращает интегральную функцию бета-распределения. |
|
БЕТА.ОБР
|
Возвращает обратную интегральную функцию указанного бета-распределения. |
|
БИНОМ.РАСП
|
Возвращает отдельное значение вероятности биномиального распределения. |
|
БИНОМ.РАСП.ДИАП
|
Возвращает вероятность пробного результата с помощью биномиального распределения. |
|
БИНОМ.ОБР
|
Возвращает наименьшее значение, для которого интегральное биномиальное распределение меньше заданного значения или равно ему. |
|
ХИ2.РАСП
|
Возвращает интегральную функцию плотности бета-вероятности. |
|
ХИ2.РАСП.ПХ
|
Возвращает одностороннюю вероятность распределения хи-квадрат. |
|
ХИ2.ОБР
|
Возвращает интегральную функцию плотности бета-вероятности. |
|
ХИ2.ОБР.ПХ
|
Возвращает обратное значение односторонней вероятности распределения хи-квадрат. |
|
ХИ2.ТЕСТ
|
Возвращает тест на независимость. |
|
ДОВЕРИТ.НОРМ
|
Возвращает доверительный интервал для среднего значения по генеральной совокупности. |
|
ДОВЕРИТ.СТЬЮДЕНТ
|
Возвращает доверительный интервал для среднего генеральной совокупности, используя t-распределение Стьюдента. |
|
КОРРЕЛ |
Возвращает коэффициент корреляции между двумя множествами данных. |
|
СЧЁТ |
Подсчитывает количество чисел в списке аргументов. |
|
СЧЁТЗ |
Подсчитывает количество значений в списке аргументов. |
|
СЧИТАТЬПУСТОТЫ |
Подсчитывает количество пустых ячеек в диапазоне. |
|
СЧЁТЕСЛИ |
Подсчитывает количество ячеек в диапазоне, удовлетворяющих заданному условию. |
|
Функция СЧЁТЕСЛИМН
|
Подсчитывает количество ячеек внутри диапазона, удовлетворяющих нескольким условиям. |
|
КОВАРИАЦИЯ.Г
|
Возвращает ковариацию, среднее произведений парных отклонений. |
|
КОВАРИАЦИЯ.В
|
Возвращает ковариацию выборки — среднее попарных произведений отклонений для всех точек данных в двух наборах данных. |
|
КВАДРОТКЛ |
Возвращает сумму квадратов отклонений. |
|
ЭКСП.РАСП
|
Возвращает экспоненциальное распределение. |
|
F.РАСП
|
Возвращает F-распределение вероятности. |
|
F.РАСП.ПХ
|
Возвращает F-распределение вероятности. |
|
F.ОБР
|
Возвращает обратное значение для F-распределения вероятности. |
|
F.ОБР.ПХ
|
Возвращает обратное значение для F-распределения вероятности. |
|
F.ТЕСТ
|
Возвращает результат F-теста. |
|
ФИШЕР |
Возвращает преобразование Фишера. |
|
ФИШЕРОБР |
Возвращает обратное преобразование Фишера. |
|
ПРЕДСКАЗ |
Возвращает значение линейного тренда. Примечание. В Excel 2016 эта функция заменена функцией ПРЕДСКАЗ.ЛИНЕЙН из нового наборафункций прогнозирования. Однако эта функция по-прежнему доступна в целях обеспечения совместимости с предыдущими версиями. |
|
ПРЕДСКАЗ.ETS
|
Возвращает будущее значение на основе существующих (ретроспективных) данных с использованием версии AAA алгоритма экспоненциального сглаживания (ETS). |
|
ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ
|
Возвращает доверительный интервал для прогнозной величины на указанную дату. |
|
ПРЕДСКАЗ.ETS.СЕЗОННОСТЬ
|
Возвращает длину повторяющегося фрагмента, обнаруженного программой Excel в заданном временном ряду. |
|
ПРЕДСКАЗ.ETS.СТАТ
|
Возвращает статистическое значение, являющееся результатом прогнозирования временного ряда. |
|
ПРЕДСКАЗ.ЛИНЕЙН
|
Возвращает будущее значение на основе существующих значений. |
|
ЧАСТОТА |
Возвращает распределение частот в виде вертикального массива. |
|
ГАММА
|
Возвращает значение функции гамма. |
|
ГАММА.РАСП
|
Возвращает гамма-распределение. |
|
ГАММА.ОБР
|
Возвращает обратное значение интегрального гамма-распределения. |
|
ГАММАНЛОГ |
Возвращает натуральный логарифм гамма-функции, Γ(x). |
|
ГАММАНЛОГ.ТОЧН
|
Возвращает натуральный логарифм гамма-функции, Γ(x). |
|
ГАУСС
|
Возвращает значение на 0,5 меньше стандартного нормального распределения. |
|
СРГЕОМ |
Возвращает среднее геометрическое. |
|
РОСТ |
Возвращает значения в соответствии с экспоненциальным трендом. |
|
СРГАРМ |
Возвращает среднее гармоническое. |
|
ГИПЕРГЕОМ.РАСП |
Возвращает гипергеометрическое распределение. |
|
ОТРЕЗОК |
Возвращает отрезок, отсекаемый на оси линией линейной регрессии. |
|
ЭКСЦЕСС |
Возвращает эксцесс множества данных. |
|
НАИБОЛЬШИЙ |
Возвращает k-ое наибольшее значение в множестве данных. |
|
ЛИНЕЙН |
Возвращает параметры линейного тренда. |
|
ЛГРФПРИБЛ |
Возвращает параметры экспоненциального тренда. |
|
ЛОГНОРМ.РАСП
|
Возвращает интегральное логарифмическое нормальное распределение. |
|
ЛОГНОРМ.ОБР
|
Возвращает обратное значение интегрального логарифмического нормального распределения. |
|
МАКС |
Возвращает наибольшее значение в списке аргументов. |
|
МАКСА |
Возвращает наибольшее значение в списке аргументов, включая числа, текст и логические значения. |
|
Функция МАКСЕСЛИ
|
Возвращает максимальное значение из заданных определенными условиями или критериями ячеек. |
|
МЕДИАНА |
Возвращает медиану заданных чисел. |
|
МИН |
Возвращает наименьшее значение в списке аргументов. |
|
МИНА |
Возвращает наименьшее значение в списке аргументов, включая числа, текст и логические значения. |
|
Функция МИНЕСЛИ
|
Возвращает минимальное значение из заданных определенными условиями или критериями ячеек. |
|
МОДА.НСК
|
Возвращает вертикальный массив наиболее часто встречающихся или повторяющихся значений в массиве или диапазоне данных. |
|
МОДА.ОДН
|
Возвращает значение моды набора данных. |
|
ОТРБИНОМ.РАСП
|
Возвращает отрицательное биномиальное распределение. |
|
НОРМ.РАСП
|
Возвращает нормальное интегральное распределение. |
|
НОРМ.ОБР
|
Возвращает обратное значение нормального интегрального распределения. |
|
НОРМ.СТ.РАСП
|
Возвращает стандартное нормальное интегральное распределение. |
|
НОРМ.СТ.ОБР
|
Возвращает обратное значение стандартного нормального интегрального распределения. |
|
ПИРСОН |
Возвращает коэффициент корреляции Пирсона. |
|
ПРОЦЕНТИЛЬ.ИСКЛ
|
Возвращает k-ю процентиль значений в диапазоне, где k может принимать значения от 0 до 1, исключая границы. |
|
ПРОЦЕНТИЛЬ.ВКЛ
|
Возвращает k-ю процентиль для значений диапазона. |
|
ПРОЦЕНТРАНГ.ИСКЛ
|
Возвращает ранг значения в наборе данных как процентную долю набора (от 0 до 1, исключая границы). |
|
ПРОЦЕНТРАНГ.ВКЛ
|
Возвращает процентную норму значения в наборе данных. |
|
ПЕРЕСТ |
Возвращает количество перестановок для заданного числа объектов. |
|
ПЕРЕСТА
|
Возвращает количество перестановок для заданного числа объектов (с повторами), которые можно выбрать из общего числа объектов. |
|
ФИ
|
Возвращает значение функции плотности для стандартного нормального распределения. |
|
ПУАССОН.РАСП
|
Возвращает распределение Пуассона. |
|
ВЕРОЯТНОСТЬ |
Возвращает вероятность того, что значение из диапазона находится внутри заданных пределов. |
|
КВАРТИЛЬ.ИСКЛ
|
Возвращает квартиль набора данных на основе значений процентили из диапазона от 0 до 1, исключая границы. |
|
КВАРТИЛЬ.ВКЛ
|
Возвращает квартиль набора данных. |
|
РАНГ.СР
|
Возвращает ранг числа в списке чисел. |
|
РАНГ.РВ
|
Возвращает ранг числа в списке чисел. |
|
КВПИРСОН |
Возвращает квадрат коэффициента корреляции Пирсона. |
|
СКОС |
Возвращает асимметрию распределения. |
|
СКОС.Г
|
Возвращает асимметрию распределения на основе заполнения: характеристика степени асимметрии распределения относительно его среднего. |
|
НАКЛОН |
Возвращает наклон линии линейной регрессии. |
|
НАИМЕНЬШИЙ |
Возвращает k-ое наименьшее значение в множестве данных. |
|
НОРМАЛИЗАЦИЯ |
Возвращает нормализованное значение. |
|
СТАНДОТКЛОН.Г
|
Вычисляет стандартное отклонение по генеральной совокупности. |
|
СТАНДОТКЛОН.В
|
Оценивает стандартное отклонение по выборке. |
|
СТАНДОТКЛОНА |
Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения. |
|
СТАНДОТКЛОНПА |
Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения. |
|
СТОШYX |
Возвращает стандартную ошибку предсказанных значений y для каждого значения x в регрессии. |
|
СТЬЮДРАСП
|
Возвращает процентные точки (вероятность) для t-распределения Стьюдента. |
|
СТЬЮДЕНТ.РАСП.2Х
|
Возвращает процентные точки (вероятность) для t-распределения Стьюдента. |
|
СТЬЮДЕНТ.РАСП.ПХ
|
Возвращает t-распределение Стьюдента. |
|
СТЬЮДЕНТ.ОБР
|
Возвращает значение t для t-распределения Стьюдента как функцию вероятности и степеней свободы. |
|
СТЬЮДЕНТ.ОБР.2Х
|
Возвращает обратное t-распределение Стьюдента. |
|
СТЬЮДЕНТ.ТЕСТ
|
Возвращает вероятность, соответствующую проверке по критерию Стьюдента. |
|
ТЕНДЕНЦИЯ |
Возвращает значения в соответствии с линейным трендом. |
|
УРЕЗСРЕДНЕЕ |
Возвращает среднее внутренности множества данных. |
|
ДИСП.Г
|
Вычисляет дисперсию по генеральной совокупности. |
|
ДИСП.В
|
Оценивает дисперсию по выборке. |
|
ДИСПА |
Оценивает дисперсию по выборке, включая числа, текст и логические значения. |
|
ДИСПРА |
Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения. |
|
ВЕЙБУЛЛ.РАСП
|
Возвращает распределение Вейбулла. |
|
Z.ТЕСТ
|
Возвращает одностороннее значение вероятности z-теста. |
Общее декодирование видимых и воображаемых объектов с использованием иерархических визуальных признаков
Субъекты
В экспериментах участвовали пять здоровых субъектов (одна женщина и четыре мужчины в возрасте от 23 до 38 лет) с нормальным зрением или зрением, скорректированным до нормального. Вместо использования статистических методов для определения размера выборки, размер выборки был выбран в соответствии с предыдущими исследованиями фМРТ с аналогичными поведенческими протоколами. Все испытуемые имели значительный опыт участия в экспериментах фМРТ и были хорошо обучены.Все субъекты предоставили письменное информированное согласие на участие в экспериментах, а протокол исследования был одобрен этическим комитетом ATR.
Визуальные изображения
Изображения были собраны из онлайн-базы данных изображений ImageNet 31 (2011 г., осенний выпуск), базы данных изображений, в которой изображения сгруппированы в соответствии с иерархией в WordNet 38 . Мы выбрали 200 репрезентативных категорий объектов (синсетов) в качестве стимулов в эксперименте с визуальным представлением изображений.После исключения изображений с шириной или высотой <100 пикселей или соотношением сторон> 1,5 или <2/3 все оставшиеся изображения в ImageNet были обрезаны по центру. По причинам авторского права изображения на рис. 1, 2, 3, 8 и 9 не являются фактическими изображениями из ImageNet, используемыми в наших экспериментах. Исходные изображения заменяются изображениями с аналогичным содержанием для отображения.
Схема эксперимента
Мы провели два типа экспериментов: эксперимент с изображением и эксперимент с изображениями.Все визуальные стимулы проецировались на экран в отверстии сканера fMRI с использованием жидкокристаллического проектора с калибровкой яркости. Данные от каждого субъекта были собраны в течение нескольких сеансов сканирования, продолжавшихся примерно 2 месяца. В каждый день эксперимента проводился один последовательный сеанс не более 2 часов. Испытуемым давали достаточно времени для отдыха между запусками (каждые 3–10 мин) и разрешали сделать перерыв или прекратить эксперимент в любое время.
Эксперимент по представлению изображений состоял из двух различных типов сеансов: сеансов с обучающими изображениями и сеансов с тестовыми изображениями, каждый из которых состоял из 24 и 35 отдельных прогонов (9 мин 54 сек для каждого прогона) соответственно.Каждый запуск содержал 55 блоков стимулов, состоящих из 50 блоков с разными изображениями и пяти случайно перемежающихся блоков повторения, в которых было представлено то же изображение, что и в предыдущем блоке. В каждом блоке стимулов изображение (угол обзора 12 × 12 градусов) мигало с частотой 2 Гц в течение 9 с. Изображения были представлены в центре дисплея с центральной точкой фиксации. Цвет пятна фиксации менялся с белого на красный за 0,5 с до того, как каждый блок стимулов начинал указывать на начало блока.Дополнительные 33- и 6-секундные периоды отдыха были добавлены к началу и концу каждого бега соответственно. Субъекты сохраняли устойчивую фиксацию на протяжении каждого прогона и выполняли одноразовую задачу обнаружения повторения на изображениях, отвечая нажатием кнопки для каждого повторения, чтобы удерживать свое внимание на представленных изображениях (среднее выполнение задания по пяти субъектам; чувствительность = 0,930; специфичность = 0,995). В сеансе тренировочного образа всего 1200 изображений из 150 категорий объектов (по 8 изображений из каждой категории) были представлены только один раз.В сеансе тестового изображения было представлено всего 50 изображений из 50 категорий объектов (по 1 изображению из каждой категории) по 35 раз каждое. Важно отметить, что категории в сеансе тестового изображения не использовались в сеансе тренировочного изображения. Порядок представления категорий был рандомизирован по запускам.
В эксперименте с изображениями испытуемые должны были визуально представить изображения из одной из 50 категорий, которые были представлены в сеансе тестовых изображений эксперимента по представлению изображений.Перед экспериментом 50 образцов изображений из каждой категории были выставлены для тренировки соответствия между именами объектов и визуальными образами, указанными в именах. Эксперимент с изображениями состоял из 20 отдельных прогонов, и каждый прогон содержал 25 блоков изображений (10 мин 39 с для каждого прогона). Каждый блок изображений состоял из 3-секундного периода подсказки, 15-секундного периода изображения, 3-секундного периода оценки и 3-секундного периода отдыха. Дополнительные 33- и 6-секундные периоды отдыха были добавлены к началу и концу каждого бега соответственно.В периоды покоя в центре дисплея отображалось белое пятно фиксации. Цвет пятна фиксации изменился с белого на красный в течение 0,5 с, чтобы указать начало блоков за 0,8 с до начала каждого периода сигнала. Во время периода подсказки слова, описывающие названия 50 категорий, представленных в сеансе тестового изображения, были визуально представлены вокруг центра дисплея (1 цель и 49 отвлекающих факторов). Положение каждого слова в блоках случайным образом изменялось, чтобы избежать искажения специфических для сигналов эффектов на ответ фМРТ во время периодов изображения.Слово, соответствующее воображаемой категории, было выделено красным цветом (цель), а другие слова — черным цветом (отвлекающие факторы). Начало и конец периодов изображения сигнализировались звуковыми сигналами. Испытуемые должны были начать воображать как можно больше изображений объектов, относящихся к категории, описанной красным словом, и были проинструктированы держать глаза закрытыми от первого сигнала до второго сигнала. После второго звукового сигнала было представлено слово, соответствующее целевой категории, чтобы испытуемые могли оценить яркость своих мысленных образов по пятибалльной шкале (очень яркая, довольно яркая, довольно яркая, не яркая, не может распознать цель). нажатие кнопки.25 категорий в каждом прогоне были псевдослучайно выбраны из 50 категорий, так что два последовательных прогона содержали все 50 категорий.
Эксперимент с ретинотопией
Эксперимент с ретинотопией проводился по стандартному протоколу 51,52 с использованием вращающегося клина и расширяющегося кольца мерцающей шахматной доски. Данные были использованы для определения границ между каждой зрительной корковой областью и для идентификации ретинотопической карты (V1 – V4) на сглаженных корковых поверхностях отдельных субъектов.
Эксперимент с локализатором
Мы провели функциональные эксперименты с локализатором для определения LOC, FFA и PPA для каждого индивидуального объекта 53,54,55 . Эксперимент с локализатором состоял из 4–8 запусков, каждый из которых содержал 16 блоков стимулов. В этом эксперименте неповрежденные или зашифрованные изображения (угол обзора 12 × 12 градусов) из категорий лиц, объектов, домов и сцен были представлены в центре экрана. Каждый из восьми типов стимулов (четыре категории × два условия) предъявлялся дважды за цикл.Каждый блок стимула состоял из 15-секундного неповрежденного или зашифрованного предъявления стимула. Неповрежденные и зашифрованные блоки стимулов предъявлялись последовательно (порядок неповрежденных и зашифрованных блоков стимулов был случайным) с последующим 15-секундным периодом отдыха, состоящим из однородного серого фона. Дополнительные 33- и 6-секундные периоды отдыха были добавлены к началу и концу каждого бега соответственно. В каждом блоке стимулов 20 различных изображений одного и того же типа были представлены в течение 0,3 с с последующим пустым экраном 0.4 с.
Получение МРТ
данных фМРТ были собраны с использованием 3,0-Тесла-сканера Siemens MAGNETOM Trio A Tim, расположенного в Центре визуализации активности мозга ATR. Для получения функциональных изображений, охватывающих весь мозг, было выполнено сканирование с чередованием T2 * -взвешенного градиентного EPI (эхопланарного изображения) (представление изображений, эксперименты с изображениями и локализаторами: время повторения (TR), 3000 мс; время эхо (TE), 30 мс; угол поворота 80 градусов; поле зрения (FOV) 192 × 192 мм 2 ; размер вокселя 3 × 3 × 3 мм 3 ; расстояние между срезами 0 мм; количество срезов 50) или вся затылочная доля (эксперимент с ретинотопией: TR, 2000 мс; TE, 30 мс; угол переворота, 80 градусов; FOV, 192 × 192 мм 2 ; размер вокселя, 3 × 3 × 3 мм 3 ; промежуток среза, 0 мм; количество ломтиков 30).Т2-взвешенные изображения турбо спинового эха сканировались для получения анатомических изображений с высоким разрешением тех же срезов, которые использовались для EPI (представление изображений, эксперименты с изображениями и локализатором: TR, 7020 мс; TE, 69 мс; угол поворота, 160 градусов; FOV , 192 × 192 мм 2 ; размер вокселя, 0,75 × 0,75 × 3,0 мм 3 ; ретинотопический эксперимент: TR, 6000 мс; TE, 57 мс; угол поворота, 160 град; FOV, 192 × 192 мм 2 ; размер вокселя 0,75 × 0,75 × 3,0 мм 3 ). Также были получены тонкоструктурные изображения всей головы, подготовленные с помощью T1-взвешенной намагниченности для быстрого получения градиент-эхо (TR, 2250 мс; TE, 3.06 мс; TI, 900 мс; угол переворота, 9 град, FOV, 256 × 256 мм 2 ; размер вокселя, 1.0 × 1.0 × 1.0 мм 3 ).
Предварительная обработка данных МРТ
Первые 9-секундные сканы для экспериментов с TR = 3 с (представление изображений, эксперименты с изображениями и локализатором) и 8-секундные сканы для экспериментов с TR = 2 с (эксперимент с ретинотопией) каждого прогона были отброшены. чтобы избежать нестабильности МРТ сканера. Полученные данные фМРТ подверглись трехмерной коррекции движения с использованием SPM5 (http: //www.fil.ion.ucl.ac.uk/spm). Затем данные были сопоставлены с анатомическим изображением с высоким разрешением внутри сеанса тех же срезов, которые использовались для EPI, а затем с анатомическим изображением всей головы с высоким разрешением. Затем зарегистрированные данные были повторно интерполированы с помощью вокселей 3 × 3 × 3 мм 3 .
Для данных эксперимента по представлению изображений и экспериментов с изображениями после удаления линейного тренда внутри прогона амплитуды вокселей были нормализованы относительно средней амплитуды всего временного хода в каждом прогоне.Нормализованные амплитуды вокселей из каждого эксперимента затем усреднялись в пределах каждого 9-секундного блока стимулов (три тома; эксперимент с изображением) или в течение каждого 15-секундного периода изображения (пять объемов; эксперимент с изображениями), соответственно (если не указано иное) после сдвига данные на 3 секунды (один объем) для компенсации задержек гемодинамики.
Выбор ROI
V1 – V4 были выделены стандартным ретинотопическим экспериментом 51,52 . Данные ретинотопического эксперимента были преобразованы в координаты Талаираха, а визуальные корковые границы были очерчены на уплощенных корковых поверхностях с помощью BrainVoyager QX (http: // www.brainvoyager.com). Координаты вокселей вокруг границы серого и белого вещества в V1 – V4 были идентифицированы и преобразованы обратно в исходные координаты изображений EPI. Воксели от V1 до V3 были объединены и определены как «LVC». LOC, FFA и PPA были идентифицированы с использованием обычных функциональных локализаторов 53,54,55 . Данные экспериментов с локализатором были проанализированы с помощью SPM5. Воксели показывают значительно более высокие отклики на объекты, лица или сцены, чем для скремблированных изображений (двусторонний t -тест, нескорректированный P <0.05 или 0,01) были идентифицированы и определены как LOC, FFA и PPA соответственно. Смежная область, покрывающая LOC, FFA и PPA, была вручную очерчена на сплющенных кортикальных поверхностях, и область была определена как «HVC». Вокселы, перекрывающиеся с LVC, были исключены из HVC. Вокселы от V1 до V4 и HVC были объединены для определения «VC». В регрессионном анализе воксели, показывающие наивысший коэффициент корреляции с целевой переменной в сеансе обучающего изображения, были выбраны для прогнозирования каждой функции (максимум 500 вокселей для V1 – V4, LOC, FFA и PPA; 1000 вокселей для LVC, HVC). и ВК).
Визуальные особенности
Мы использовали четыре типа вычислительных моделей: CNN 20 , HMAX 21,22,23 , GIST 24 и SIFT 18 в сочетании с ‘BoF’ 16 для построения визуальных особенности из изображений. Функции с фазой обучения модели (HMAX и SIFT + BoF) использовали для обучения 1000 изображений, принадлежащих к категориям, используемым в сеансе обучающих изображений (150 категорий). Каждая модель подробно описана в следующих подразделах.
Сверточная нейронная сеть
Мы использовали реализацию MatConvNet (http: // www.vlfeat.org/matconvnet/) модели CNN 20 , которая была обучена с изображениями в ImageNet 31 для классификации 1000 категорий объектов. CNN состояла из пяти сверточных слоев и трех полностью связанных слоев. Мы случайным образом выбрали 1000 единиц в каждом из слоев с первого по седьмой и использовали все 1000 единиц на восьмом уровне. Мы представили каждое изображение вектором выходных данных этих устройств и назвали их CNN1 – CNN8 соответственно.
HMAX
HMAX 21,22,23 — это иерархическая модель, которая расширяет простые и сложные ячейки, описанные Hubel и Wiesel 56,57 и вычисляемые функции, через иерархические уровни.Эти слои состоят из слоя изображения и шести последующих слоев (S1, C1, S2, C2, S3 и C3), которые построены из предыдущих слоев путем чередования операций сопоставления шаблонов и max. В расчетах на каждом слое мы использовали те же параметры, что и в предыдущем исследовании 22 , за исключением того, что количество элементов в слоях C2 и C3 было установлено на 1000. Мы представили каждое изображение вектором трех типов функций HMAX, который состоял из 1000 случайно выбранных выходных данных единиц в слоях S1, S2 и C2, и всех 1000 выходных данных в слое C3.Мы определили эти выходы как HMAX1, HMAX2 и HMAX3 соответственно.
GIST
GIST — это модель, разработанная для компьютерной задачи категоризации сцены 24 . Для вычисления GIST изображение сначала было преобразовано в шкалу серого, а его размер был изменен до максимальной ширины 256 пикселей. Далее изображение было отфильтровано с помощью набора фильтров Габора (16 ориентаций, 4 шкалы). После этого отфильтрованные изображения были сегментированы сеткой 4 × 4 (16 блоков), а затем отфильтрованные выходные данные в каждом блоке были усреднены для извлечения 16 ответов для каждого фильтра.Ответы от нескольких фильтров были объединены, чтобы создать 1024-мерный вектор признаков для каждого изображения (16 (ориентации) × 4 (масштаб) × 16 (блоков) = 1024).
SIFT с BoF (SIFT + BoF)
Визуальные характеристики с использованием SIFT с подходом BoF были рассчитаны на основе дескрипторов SIFT. Мы вычислили дескрипторы SIFT из изображений, используя реализацию VLFeat 58 плотного SIFT. В подходе BoF каждый компонент вектора признаков (визуальные слова) создается путем векторного квантования извлеченных дескрипторов.Используя ~ 1000000 дескрипторов SIFT, рассчитанных из независимого набора обучающих образов, мы выполнили кластеризацию k-средних, чтобы создать набор из 1000 визуальных слов. Дескрипторы SIFT, извлеченные из каждого изображения, были квантованы в визуальные слова с использованием ближайшего центра кластера, и частота каждого визуального слова была вычислена для создания гистограммы BoF для каждого изображения. Наконец, все гистограммы, полученные в результате описанной выше обработки, прошли L-1 нормализацию, чтобы стать векторами единичной нормы. Следовательно, функции из SIFT с подходом BoF инвариантны к масштабированию, перемещению и повороту изображения и частично инвариантны к изменениям освещения и аффинной или трехмерной проекции.
Декодирование визуальных признаков
Мы построили модели декодирования для прогнозирования векторов визуальных признаков видимых объектов по активности фМРТ с использованием функции линейной регрессии. Здесь мы использовали SLR (http://www.cns.atr.jp/cbi/sparse_estimation/index.html) 32 , который может автоматически выбирать важные функции для прогнозирования. Известно, что разреженная оценка хорошо работает, когда размерность объясняющей переменной высока, как в случае с данными фМРТ 59 .
Учитывая образец фМРТ, состоящий из активности d вокселей в качестве входных данных, функция регрессии может быть выражена как
, где x i — скалярное значение, определяющее амплитуду фМРТ воксела i , w i — вес вокселя i и w 0 — смещение.Для простоты смещение w 0 поглощается вектором весов, так что. В данные вводится фиктивная переменная x 0 = 1, так что. Используя эту функцию, мы смоделировали l -й компонент каждого вектора визуальных признаков как целевую переменную t l ( l ∈ {1,…, L }), что объясняется регрессией функция y ( x ) с аддитивным гауссовым шумом, как описано в
, где ∈ — гауссовская случайная величина с нулевым средним с точностью до шума β .
Учитывая набор обучающих данных, SLR вычисляет веса для функции регрессии, так что функция регрессии оптимизирует целевую функцию. Чтобы построить целевую функцию, мы сначала выражаем функцию правдоподобия как
, где N — количество выборок, а X — это матрица данных фМРТ N × ( d +1), у которой n -я строка представляет собой одномерный вектор d + x n и являются выборками компонента вектора визуальных признаков.
Мы выполнили оценку байесовского параметра и приняли автоматическое определение релевантности до 32 , чтобы внести разреженность в оценку веса. Мы рассмотрели оценку весового параметра w с учетом наборов обучающих данных { X , t l }. Мы приняли гауссовское распределение априорным для весов w и неинформативными априорными значениями для параметров точности веса и параметра точности шума β , которые описаны как
. оцениваемые параметры и веса могут быть оценены путем оценки следующей совместной апостериорной вероятности w :
. Учитывая, что оценка совместной апостериорной вероятности аналитически неразрешима, мы аппроксимировали ее, используя вариационный байесовский метод 32,60, 61 .Хотя результаты, показанные на основных рисунках, основаны на этой модели автоматического определения релевантности, мы получили качественно аналогичные результаты с использованием других регрессионных моделей (дополнительные рисунки 21 и 22).
Мы обучили модели линейной регрессии, которые предсказывают векторы признаков отдельных типов / слоев признаков для категорий наблюдаемых объектов по образцам фМРТ в сеансе обучающего изображения. Для наборов тестовых данных образцы фМРТ, соответствующие тем же категориям (35 образцов в сеансе тестового изображения, 10 образцов в эксперименте с изображениями), были усреднены по испытаниям для увеличения отношения сигнал / шум сигналов фМРТ.Используя изученные модели, мы предсказали векторы признаков видимых / воображаемых объектов из усредненных образцов фМРТ, чтобы построить один предсказанный вектор признаков для каждой из 50 тестовых категорий.
Синтез предпочтительных изображений с использованием максимизации активации
Мы использовали метод максимизации активации для генерации предпочтительных изображений для отдельных единиц в каждом слое CNN 33,34,35,36 . Синтез предпочтительных изображений начинается со случайного изображения и оптимизирует изображение, чтобы максимально активировать целевой блок CNN, итеративно вычисляя, как изображение должно быть изменено с помощью обратного распространения.Этот анализ был реализован с использованием специального программного обеспечения, написанного в MATLAB на основе кодов Python, представленных в серии сообщений в блогах (Mordvintsev, A., Olah, C., Tyka, M., DeepDream — пример кода для визуализации нейронных сетей, https: / /github.com/google/deepdream, 2015; Ойгард, AM, Визуализация классов GoogLeNet, https://github.com/auduno/deepdraw, 2015).
Идентификационный анализ
В ходе идентификационного анализа категории видимых / воображаемых объектов были идентифицированы с использованием векторов визуальных признаков, декодированных из сигналов фМРТ.Перед идентификационным анализом векторы визуальных признаков были вычислены для всех предварительно обработанных изображений во всех категориях (15 372 категории в ImageNet 31 ), за исключением тех, которые использовались в экспериментах с фМРТ и их категорий гиперонимов / гипонимов, а также тех, которые использовались для визуализации. обучение функциональной модели (HMAX и SIFT + BoF). Векторы визуальных признаков отдельных изображений были усреднены внутри каждой категории, чтобы создать средние по категории векторы признаков для всех категорий, чтобы сформировать набор кандидатов.Мы вычислили коэффициенты корреляции Пирсона между декодированными и средними по категории векторами признаков в наборах кандидатов. Для количественной оценки точности мы создали наборы кандидатов, состоящие из увиденных / воображаемых категорий и указанного количества случайно выбранных категорий. Ни одна из категорий в наборе кандидатов не использовалась для обучения декодера. Учитывая декодированный вектор признаков, идентификация категории проводилась путем выбора категории с наивысшим коэффициентом корреляции среди наборов кандидатов.
Статистика
В основном анализе мы использовали t -тесты, чтобы проверить, превышает ли среднее значение коэффициентов корреляции и среднее значение точности идентификации по субъектам уровень вероятности (0 для коэффициента корреляции и 50% для точность идентификации). Для коэффициентов корреляции перед статистическими тестами применялось преобразование Фишера z . Перед каждым тестом t мы выполняли тест Шапиро-Уилка для проверки нормальности и подтвердили, что нулевая гипотеза о том, что данные, полученные из нормального распределения, не была отвергнута для всех случаев ( P > 0.01).
Доступность данных и кода
Экспериментальные данные и коды, подтверждающие выводы этого исследования, доступны в нашем репозитории: https://github.com/KamitaniLab/GenericObjectDecoding.
Декодирование звуковых категорий на основе паттернов функциональной связи всего мозга
2Кодирование звука важно для пациентов с потерей чувствительности, например для слепых. Предыдущие исследования звуковой категоризации проводились путем оценки активности мозга с использованием одномерного анализа или методов многомерного декодирования на основе вокселей, и предполагали, что некоторые области были чувствительны к слуховым категориям.Предполагается, что обратная связь между областями мозга может облегчить выбор слуховых объектов. Следовательно, важно изучить, можно ли использовать функциональную связность между регионами для декодирования категории звука. В этом исследовании мы построили паттерны функциональной связи всего мозга, когда испытуемые воспринимали четыре разные звуковые категории, и объединили их с анализом многомерной классификации паттернов для декодирования звука. Категориальные дискриминативные сети и регионы были определены на основе карт весов.Результаты показали, что высокая точность классификации по нескольким категориям была получена на основе паттернов функциональной связи всего мозга, и результаты были проверены с помощью различных параметров предварительной обработки. Понимание категории дискриминирующих функциональных сетей показало, что вкладные связи пересекают левое и правое полушарие и варьируются от первичных областей до когнитивных областей высокого уровня, что дает новые доказательства распределенного представления слухового объекта. Дальнейший анализ областей мозга в дискриминирующих сетях показал, что верхняя височная извилина и извилина Хешля вносят значительный вклад в распознавание категорий звуков.Вместе полученные результаты показывают, что метод многомерной классификации, основанный на функциональной связности, предоставляет обширную информацию для декодирования слуховых категорий. Успешные результаты декодирования подразумевают интерактивные свойства распределенных областей мозга в представлении слуховых звуков.
Ключевые слова: Слуховое декодирование; Функциональная связность; Функциональная магнитно-резонансная томография; Многомерный анализ паттернов; Категория звука.
Декодирование нескольких категорий звуков в височной коре человека с использованием фМРТ высокого разрешения
Abstract
Восприятие звуковых категорий — важный аспект слухового восприятия. Степень, в которой представление мозга о звуковых категориях закодировано в специализированных субрегионах или распределяется по слуховой коре, остается неясной. Недавние исследования с использованием многомерного анализа паттернов (MVPA) активаций мозга предоставили важную информацию о том, как мозг декодирует перцептивную информацию.В существующей обширной литературе по декодированию мозга с использованием методов MVPA относительно мало исследований было проведено по мультиклассовой категоризации в слуховой области. Здесь мы исследовали представление и обработку слуховых категорий в височной коре человека с использованием методов фМРТ и MVPA высокого разрешения. Что еще более важно, мы рассматривали возможность одновременного декодирования нескольких категорий звука с помощью исключения машинно-рекурсивных функций мультиклассового вектора поддержки (MSVM-RFE) в качестве нашего инструмента MVPA.Результаты показывают, что для всех классификаций модель MSVM-RFE смогла изучить функциональную связь между несколькими звуковыми категориями и соответствующими вызванными пространственными паттернами и классифицировать немаркированные вызванные звуком паттерны значительно выше вероятности. Это указывает на возможность декодирования нескольких звуковых категорий не только внутри, но и между предметами. Однако вариация между предметами влияет на эффективность классификации больше, чем вариация внутри предмета, поскольку внутрипредметный анализ имеет значительно более низкую точность классификации.Карты мозга с селективной категорией звука были идентифицированы на основе мультиклассовой классификации и выявили распределенные паттерны мозговой активности в верхней и средней височной извилинах. Это соответствует предыдущим исследованиям, показывающим, что информация в пространственно распределенных образцах может отражать более абстрактный уровень восприятия представления звуковых категорий. Кроме того, мы показываем, что эффективность классификации по предметам может быть значительно улучшена путем усреднения изображений фМРТ по элементам, поскольку несущественные различия между различными элементами одной и той же звуковой категории уменьшаются, и, в свою очередь, увеличивается доля сигналов, относящихся к классификации звука.
Образец цитирования: Чжан Ф., Ван Дж. П., Ким Дж., Пэрриш Т., Вонг PCM (2015) Декодирование нескольких категорий звуков в височной коре человека с использованием фМРТ высокого разрешения. PLoS ONE 10 (2): e0117303. https://doi.org/10.1371/journal.pone.0117303
Академический редактор: Юрки Ахвенинен, Гарвардская медицинская школа / Массачусетская больница общего профиля, США
Поступила: 15.11.2013; Одобрена: 22 декабря 2014 г .; Опубликован: 18 февраля 2015 г.
Авторские права: © 2015 Zhang et al.Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника
Финансирование: Авторы хотели бы признать финансовая поддержка грантов от Национального научного фонда (BCS-1125144) и Национальных институтов здравоохранения (R01DC008333), предоставленных PW Финансирующие организации не играли никакой роли в дизайне исследования, сборе и анализе данных, принятии решения о публикации или подготовке рукописи.
Конкурирующие интересы: Авторы заявили, что конкурирующих интересов не существует.
Введение
Восприятие звуковых категорий имеет фундаментальное значение в нашей повседневной жизни. Один из основных аспектов слухового восприятия — это абстрагирование отдельных категорий от непрерывных физических характеристик, когда стимулы сгруппированы в отдельные, но значимые категории [1]. Категоризация требует минимизации внутри категории и максимизации различий между категориями, что является более абстрактным представлением звукового сходства.Таким образом устраняются постоянные физические вариации между стимулами, так что кажущиеся разными стимулы можно рассматривать как одну и ту же категорию. Было сделано несколько попыток исследовать репрезентацию звуковых категорий мозгом [1–3]. Несколько исследований подтвердили иерархически организованный путь обработки объектов вдоль антеровентральной слуховой коры [3, 4], в то время как другие подчеркивали важность распределенных представлений слуховых объектов [2, 5]. Степень, в которой представление и обработка слуховых категорий кодируется в специализированных субрегионах или распределяется по слуховой коре, остается неясной.
Недавние исследования функциональной магнитно-резонансной томографии (фМРТ) применили различные статистические методы к декодированию мозга и предоставили важную информацию о том, как мозг декодирует перцептивную информацию [5–11]. Многомерный анализ паттернов (MVPA) привлекает все большее внимание в исследованиях фМРТ [10–13]. В то время как традиционные одномерные подходы исследуют только одно местоположение (воксель) за раз, MVPA извлекает информацию из многих местоположений мозга (вокселей) одновременно, тем самым исследуя полный пространственный паттерн реакций мозга.При изучении представления категорий визуальных объектов в вентральной височной коре было продемонстрировано, что MVPA чувствительна к изменениям в распределенных паттернах активации в отсутствие изменений общего уровня активации [14]. Подход MVPA был использован для выявления тонких различий в перекрывающихся звуковых представлениях [2, 5]. Однако эти исследования либо в основном сосредоточены на бинарной классификации, либо имеют тенденцию изучать визуальное восприятие [5–9]. В существующей обширной литературе по декодированию мозга с использованием методов MVPA имеется относительное отсутствие исследований по мультиклассовой категоризации в слуховой области.Богатое разнообразие слуховых категорий в реальной жизни создает необходимость в стратегиях декодирования для одновременного рассмотрения нескольких категорий. Мультиклассовые модели MVPA позволяют использовать более двух категорий. Следовательно, в этой работе мы изучаем декодирование нескольких звуковых категорий одновременно в височной коре человека с использованием фМРТ высокого разрешения и мультиклассовых моделей MVPA.
При исследовании слуховых функций с помощью фМРТ возникают проблемы анализа данных, поскольку звуковой сигнал является непрерывным и изменяется со временем.Распознавание звуковых объектов требует непрерывного прослушивания и непрерывной обработки его познавательного значения. Это может привести к тому, что гемодинамические ответы будут менее информативными для различения различных слуховых стимулов. Кроме того, McDermott et al . показали, что и визуальная, и слуховая обработка требуют сводной статистики, но визуальная обработка является пространственной, а слуховая — временной [15–17]. Сводные статистические измерения зрения происходят в пространственных областях поля зрения, в то время как слуховые эффекты включают объединение информации во времени [15, 18].Одно фундаментальное исследование восприятия речи объединило технологию фМРТ со статистическим методом распознавания образов (поддержка векторного машинно-рекурсивного исключения признаков, SVM-RFE), чтобы продемонстрировать возможность декодирования речевого содержания и идентичности говорящего [5]. Однако их анализ ограничивался бинарной классификацией и не рассматривал одновременное декодирование нескольких слуховых объектов. В повседневной жизни человек сталкивается с большим количеством слуховых объектов, что создает потребность в стратегиях декодирования для обобщения для множества слуховых объектов и разных людей.На сегодняшний день в большинстве исследований человеческого декодирования алгоритмы декодирования обучались индивидуально для каждого участника и / или для фиксированного набора психических состояний, что является очень упрощенной ситуацией по сравнению с реальными приложениями [5, 6, 9, 10]. Степень, в которой модели декодирования MVPA могут быть обобщены для различных обстоятельств, таких как несколько категорий звука, разные предметы и разные образцы звука в одной и той же категории звука, в настоящее время не совсем понятна [9, 10].
В этом исследовании мы исследовали представление и обработку слуховых категорий в височной коре человека с использованием методов фМРТ и MVPA высокого разрешения.Что еще более важно, мы рассматривали декодирование нескольких звуковых категорий одновременно с помощью мультиклассовых классификаторов в качестве наших инструментов MVPA. Сначала мы построили многоклассовые модели MVPA для каждого испытуемого отдельно, чтобы предсказать, какую из семи звуковых категорий он слышит. Этот внутрисубъектный анализ позволил нам исследовать пространственно различные паттерны избирательной активности звуковых категорий в височной коре головного мозга человека. Затем мы построили многоклассовые (все семь звуковых категорий) классификаторы по предметам. В этой процедуре классификатор научился различать нейронные паттерны, вызываемые каждой звуковой категорией, на основе данных от подгруппы субъектов, а затем был протестирован на данных от субъекта, который не входил в эту подгруппу.В рамках этого межсубъектного анализа мы спросили, существуют ли у разных испытуемых последовательные паттерны активности мозга и как результаты анализа паттернов обобщаются для разных субъектов. Категориальное восприятие звуков требует более абстрактного представления звукового подобия. Формирование границы категорий требует перцептивной инвариантности наборов объектов, классифицированных как принадлежащие к одной и той же категории, и игнорирования несущественных различий в некоторых аспектах. Не все надежные образцы эквивалентны по принадлежности к категории.Поэтому мы исследовали влияние принадлежности к категории на модели активности мозга и точность декодирования.
Материалы и методы
Заявление о соблюдении этических норм
Исследование было одобрено Наблюдательным советом Северо-Западного университета, и от всех участников было получено письменное информированное согласие.
Участники
Шесть одноязычных англоговорящих правшей (средний возраст 22,5 года; 4 женщины) из Северо-Западного университета были набраны для исследования функциональной визуализации.У них не было в анамнезе неврологических расстройств, и они сообщили о нормальном слухе. Подобный размер выборки использовался в нескольких других исследованиях фМРТ высокого разрешения для изучения декодирования человеческого мозга [1, 2, 5, 19, 20].
Стимулы
Были использованы семь категорий звуков, включая английскую речь (EN), неанглийскую речь (NE), неречевую речь (VC), животные (AN), механические (MC), музыкальные (MS) и звуки природы (NT). ). Это были когнитивные категории, которые являются абстрактными и, вероятно, различаются по многим параметрам, а не категории восприятия, которые с помощью задач идентификации и различения демонстрируют четкие признаки категориального восприятия (например, речевые согласные).Каждая категория состояла из шести различных звуковых элементов (звуковых образцов), т.е. всего было использовано 42 жетона (стимула) (Таблица 1). Стимулы длились одну секунду, взятые с веб-сайтов (AN, MC, MS и NT) и из оригинальных записей (EN, NE и VC). Все стимулы были повторно дискретизированы до 44,1 кГц и нормализованы к одному и тому же уровню интенсивности и основной частоте с использованием программ Praat и Level 16 [21, 22].
Для обеспечения качества звука и точности идентификации было проведено пилотное поведенческое исследование с участием десяти добровольцев, которые не участвовали в сеансах сканирования.Их попросили описать услышанное в коротком предложении и оценить качество звука по шкале от одного (худшее) до семи (лучшее) после прослушивания каждого стимула. Все испытуемые, кроме одного, который не мог распознавать большинство звуков, смогли правильно идентифицировать индивидуальные стимулы. Результаты этого пилотного исследования были использованы в процессе построения и выбора стимулов. Как показано в таблице 1, средние оценки качества звука для каждой категории находятся в диапазоне от 4,4 до 5,0, что указывает на адекватное качество звуковых стимулов.Кроме того, после сканирования всех субъектов, участвовавших в сканировании с помощью фМРТ, спросили, и они подтвердили, что они могут точно классифицировать отдельные стимулы.
Экспериментальный дизайн и получение фМРТ
Был принят дизайн, связанный с медленным событием, со средним интервалом между стимулами (ISI) 15 секунд. Медленный, связанный с событием дизайн с длинным ISI позволяет оценивать динамику ЖИВОЙ реакции на одиночные представления звуков путем измерения импульсной характеристики стимулов.Каждый из семи функциональных прогонов состоял из 42 испытаний стимулов, в которых каждый звуковой стимул предъявлялся только один раз. Последовательность стимулов была псевдо-рандомизирована по сериям.
Визуализация головного мозга была выполнена в Центре усовершенствованной МРТ отделения радиологии Северо-Западного университета с использованием Siemens 3T Trio. Для каждого субъекта было собрано семь функциональных прогонов с высоким пространственным разрешением (1,7 мм × 1,7 мм × 2 мм) (215 объемов на цикл = 5 объемов x 43 испытания, 10 минут 45 секунд = 15 секунд x 43 испытания) в течение двух дней с использованием стандартная последовательность эхо-планарного изображения (EPI) (TR = 3 с, TA = 2 с, TE = 20 мс, 1 попытка = 15 секунд = 5 повторений 2-секундного сканирования и 1-секундное молчание).Первоначальные 5 объемов каждого цикла были отброшены, чтобы позволить MR-сигналу достичь равновесия. Каждый объем состоял из 32 смежных срезов без промежутка, покрывающих всю височную долю. Во время функциональных прогонов испытуемые слушали стимулы, которые подавались через наушники-вкладыши, совместимые с МРТ (Sensimetrics, Inc, Boston), в интервале молчания в 1 секунду между двумя измерениями громкости. Звуковой стимул был предъявлен в одном из этих пяти 1-секундных молчаний. Подача стимулов в безмолвном промежутке приводила к четкому восприятию акустических стимулов и отделению от шума сканирования.Анатомическое изображение, охватывающее весь мозг, также было получено с использованием T1-взвешенной последовательности с высоким разрешением (1 мм × 1 мм × 1 мм).
Предварительная обработка данных
Функциональные и анатомические изображения были проанализированы с помощью AFNI [23]. Функциональные изображения были предварительно обработаны для коррекции синхронизации срезов, коррекции движения твердого тела, удаления линейных тенденций, временной высокочастотной фильтрации, сопоставления с отдельными структурными изображениями и нормализации анатомических и функциональных данных в пространстве Талаираха.Пространственное сглаживание не применялось для сохранения мелкозернистой пространственной информации из функциональной МРТ с высоким разрешением.
В каждом вокселе ответ на стимул был получен с помощью общей линейной модели (GLM) с одним кодированием предиктора для стимула [5, 24]. Расчетный коэффициент регрессии (то есть бета) был взят для представления ответа на стимул, и бета-версии всех вокселей были объединены для формирования матрицы данных со столбцами вокселей и строками ответов на стимулы каждого вокселя. Эта матрица данных затем использовалась в качестве входных данных в нашем анализе MVPA.
Анализ MVPA
Чтобы изучить мультиклассовую категоризацию слуховых объектов, мы следовали общей структуре MVPA. Был представлен популярный алгоритм MVPA SVM-RFE. Затем было представлено мультиклассовое расширение SVM-RFE. Кроме того, мы рассмотрели несколько других подходов, основанных на поддерживающих векторных машинах (SVM), и их варианты.
Общая структура MVPA
Типичные приложения MVPA для фМРТ требуют двух основных этапов: обучения модели и тестирования модели [10, 25].На этапе обучения модель MVPA строится путем изучения функциональной взаимосвязи между паттернами реакции мозга и психическими состояниями (экспериментальными условиями) с использованием набора обучающих данных. Экспериментальные условия обычно обозначаются дискретными значениями, такими как единица или отрицательное значение для двоичных результатов. На этапе тестирования недавно обученная модель MVPA используется для классификации экспериментальных условий независимого набора данных (тестовых данных) на основе паттернов мозга. Производительность модели оценивается с точки зрения точности классификации.
Данные фМРТ разделены на набор обучающих данных, заданный матрицей X ϵ R n × p и набор тестовых данных, заданный матрицей, с соответствующими метками Y ϵ R n × 1 с указанием соответствующих экспериментальных условий. В контексте классификации ответов фМРТ, n обозначает размер обучающей выборки, m обозначает размер тестовой выборки, а p обозначает количество вокселей.Модель MVPA сначала изучает функцию принятия решения (или дискриминантную функцию), обозначенную как f (X) , которая является скалярной функцией входных шаблонов ответа мозга X . В случае линейной классификации ответов фМРТ новые паттерны классифицируются по знаку решающей функции: (1) Где W T — это весовой вектор 1 × p , а b — член смещения или пороговый вес. Правило принятия решения для двоичного классификатора: (2)
SVM-RFE
SVM-RFE — это популярная модель MVPA, которую можно использовать для определения паттернов реакции мозга посредством обучения и тестирования бинарного классификатора.Он широко оценивался как с помощью смоделированных, так и реальных данных фМРТ [1, 5, 24, 26]. Этот алгоритм может эффективно уменьшить размерность набора данных фМРТ путем итеративного удаления вокселей с наименьшим рангом при определенном критерии ранжирования [27]. Этот алгоритм выполняется с двумя последовательными шагами итеративно, включая построение классификатора (машина опорных векторов) и удаление рекурсивных признаков.
В настоящее время SVMявляются одним из самых известных методов классификации с вычислительными преимуществами.Интуитивно SVM ищет гиперплоскость, до которой максимально увеличивается расстояние от ближайших выборок каждого из двух классов [28]. Решающее правило линейной двоичной SVM следует формуле (2). Механизм SVM заключается в минимизации следующей проблемы оптимизации:
- Свернуть,
- В соответствии с y i [ w T x i + b] ≥ 1- ξ i , ξ i ≥ 0, i = …, п .
Рекурсивное исключение признаков (RFE) — это итеративная процедура обратного исключения вокселов.Принято считать, что в исследованиях фМРТ только части мозга участвуют в восприятии определенной информации, поэтому модели MVPA стремятся идентифицировать подмножество вокселей, которые могут эффективно и действенно представлять различные процессы интересующего стимула. RFE является такой стратегией устранения вокселов, и ее можно резюмировать следующим образом:
- Обучите классификатор (оптимизируйте веса W i относительно Дж (Вт) )
- Вычислить дискриминационные веса (критерий ранжирования) для всех функций ( W i 2 )
- Удалите элементы с наименьшими разрядами.
Универсальный SVM-RFE
SVM-RFE изначально был разработан для двоичной классификации. В настоящем исследовании мы хотим построить модель многоклассовой классификации для одновременного декодирования нескольких звуковых категорий на основе активности мозга в слуховой коре височной доли. Следовательно, после предварительной обработки данных с использованием AFNI мы применили расширение SVM-RFE, а именно мультиклассовый SVM-RFE (MSVM-RFE), для декодирования нескольких категорий звука [29].
Мы рассмотрели все воксели в височной доле обоих полушарий, чтобы сформировать исходные многовоксельные паттерны.Воксельная реакция стимула оценивалась с помощью GLM, в которой стимул кодировался как один предиктор. Для этого анализа стимульные реакции оценивались для каждого из семи функциональных прогонов отдельно.
Весь набор данных был разделен на две части: обучающий набор и тестовый набор. Для каждого разделения данные из обучающего набора использовались для обучения классификатора вычислению дискриминантных весов вокселей, а затем данные из независимого тестового набора использовались для тестирования обученного классификатора для оценки точности классификации.По соглашению [27] половина вокселов с более низкими дискриминантными весами удалялась на этапе RFE в каждой итерации. На этапе обучения перекрестная проверка использовалась, чтобы найти оптимальное количество вокселов, которые должны быть включены в модель, что дало наименьшую ошибку перекрестной проверки. Для внутрипредметного анализа классификатор был обучен для каждого предмета отдельно, с данными пяти функциональных прогонов в качестве обучающего набора и двух других прогонов как тестового набора. Процесс повторялся пять раз, каждый со случайным выбором разделения данных на семь функциональных прогонов.Для межпредметного анализа данные от каждого отдельного субъекта были исключены один раз в качестве набора тестов, в то время как данные от всех других субъектов обрабатывались как обучающий набор. Точности классификации, рассчитанные на основе наборов тестов, усредняли по всем повторениям. Выбранные воксели были сопоставлены с шаблоном мозга в качестве отличительной карты для каждой классификации.
Чтобы исследовать репрезентацию звуковых категорий мозгом, мы построили карты выборки звуков по категориям. Подобно одномерному контрастному анализу, категориально-селективные карты часто определяются на основе результатов алгоритмов бинарной классификации [3].Например, выборочная карта английского языка может быть определена как соединение шести различающих карт, относящихся к английской категории, которые получены посредством бинарных классификаций английского языка по сравнению с каждой из шести других звуковых категорий. В этом исследовании мы использовали мультиклассовую классификацию, чтобы найти карты с отбором по категориям. Например, выборочная карта для английского языка определяется как значимые оставшиеся воксели при сравнении классификаторов 7-го (все) и 6-го классов (без английского). Мы объединили выбранные воксели от всех субъектов и сопоставили эти воксели, которые последовательно выживали при выборе RFE более чем для одного повторения и более чем для одного субъекта, обратно в шаблон мозга в виде выборочных карт.
Другие методы MVPA
Поскольку SVM-RFE является одной из многих возможных машин векторов поддержки, мы также исследовали две другие модели SVM, включая L2-регуляризованную классификацию векторов поддержки L1-потерь [30] и мультиклассовую SVM Краммера-Зингера [30]. Хотя SVM часто понимается как метод поиска гиперплоскости с максимальным запасом, его также можно сформулировать как функцию потерь на шарнире плюс член регулирования L2-нормы. Так называемая L2-регуляризованная классификация опорных векторов L1-потерь — это машина опорных векторов со схемой регуляризации L2-нормы и функцией потерь L1-нормы.Мультиклассовая SVM Краммера-Зингера — это машина опорных векторов, которая может классифицировать несколько классов без возможности выбора вокселей [31]. Поскольку данные фМРТ имеют высокую размерность, мы также рассмотрели применение штрафного линейного дискриминантного анализа (PLDA), одного передового статистического метода, обычно используемого при анализе данных большой размерности [32]. Линейный дискриминантный анализ — это классический метод уменьшения размерности и классификации, цель которого — максимизировать соотношение межклассовой дисперсии к внутриклассовой дисперсии.PLDA — это общий подход к наказанию дискриминантных векторов в линейном дискриминантном анализе Фишера, что приводит к большей интерпретируемости. Результаты этих методов будут сравнены в следующем разделе.
Результаты
Многоклассная классификация по предметам
В общем, мультиклассовое предсказание намного сложнее, чем решение двоичного предсказания [29]. Эта проблема становится еще более сложной в данных фМРТ из-за большого количества вокселей и относительно небольшого количества выборок для каждого стимула и категории.Сначала мы исследовали характеристики классификации нескольких мультиклассовых моделей MVPA, включая MSVM-RFE, PLDA, L2-регуляризованную векторную классификацию L1-потерь и мультиклассовую SVM Краммера-Зингера. Классификатор из семи классов был построен с использованием каждого из этих статистических методов с пятью повторениями. Как показано на рис. 1, MSVM-RFE по точности классификации намного превосходит остальные три модели. Горизонтальная линия отмечает уровень вероятности. Следует отметить, что в литературе имеется гораздо больше доступных моделей MVPA.Для нашей конкретной проблемы была выбрана модель MSVM-RFE для анализа данных фМРТ.
Для оценки и декодирования различных паттернов активации, вызванных разными звуковыми категориями, мы обучили и протестировали модель MSVM-RFE для декодирования всех семи звуковых категорий одновременно в пределах каждого субъекта. На рис. 2 показаны точности классификации для внутрисубъектного анализа с уровнем вероятности, отмеченным горизонтальной линией. Модель MSVM-RFE смогла изучить функциональную связь между звуковыми категориями и соответствующими вызванными пространственными паттернами и достигла точности классификации для каждого субъекта, значительно превышающей уровень вероятности (p = 3 × 10 -4 для субъекта 1, p <1 × 10 -4 для субъектов 2 и 3, p = 2.6 × 10 -3 для субъекта 4, p = 1,7 × 10 -3 для субъекта 5 и p = 1 × 10 -4 для субъекта 6, односторонний t-критерий для одного образца, n = 5) . Это демонстрирует возможность декодирования нескольких звуковых категорий внутри субъектов. На рис. 2 мы также наблюдали некоторые признаки изменчивости результатов классификации по предметам.
Для дальнейшего изучения представления мозгом категорий звуков мы построили карты выборки звуков по категориям. На рис. 3 показаны отдельные карты мозга для категорий «Английский» и «Музыка» по отдельности, обе из которых выявили распределенные паттерны мозговой активности в верхней височной извилине (STG) и средней височной извилине (MTG).Выборочная карта английского языка, которая отличала английский язык от других шести звуковых категорий, была широко распространена двусторонне в STG с самым большим кластером (приблизительно соответствующим координате MNI -58, -30, -9) в левой MTG. Панели (a1) — (a4) на рис.3 показывают четыре самых больших кластера из вокселей, выбранных для английской категории в левом MTG (-58, -30, -9), левом STG (-65, -16, 4 ), правый STG (64, -27, 2) и левый MTG (-46, -53, 6) соответственно. На панели (а5) показано скопление на левой извилине Гешля (-49, -16, 7).Как показано на панелях (b1) — (b5), пять самых больших кластеров для карты выбора музыки были обнаружены в правом MTG (64, -37, -1), правом MTG (65, -41, 2), правый STG (58, -24, 0), правый STG (47, 11, -9) и левый STG (-55, 9, 3), а различительные паттерны для музыки были широко распределены с обеих сторон в верхних височных регионы. В литературе по декодированию головного мозга четко не определен распределенный паттерн мозговых реакций. В области зрительного восприятия было обнаружено, что представление мозгом категорий визуальных объектов широко распространено, что отражается в отчетливом паттерне реакции на обширном пространстве коры головного мозга [14].Тот же тип распределенного паттерна, специфичного для категории, наблюдался в нашем исследовании, а также в нескольких других исследованиях декодирования мозга в слуховой области [2, 5]. Наши результаты показывают, что представления звуковых категорий широко распространены в височной коре. Это согласуется с предыдущими исследованиями, показывающими, что информация в пространственно распределенных паттернах может отражать более абстрактный уровень восприятия представления звуковых категорий [1, 2].
Рис. 3. Выборочные карты мозга для (а) английского и (б) музыкальных категорий, основанные на результатах классификации MSVM-RFE.
Панели (a1) — (a4) показывают четыре самых больших кластера из вокселей, выбранных для английской категории. На панели (а5) показано скопление на левой извилине Гешля. Панели (b1) — (b5) показывают пять самых больших кластеров из вокселей, выбранных для категории «Музыка». Для каждой панели аксиальный, сагиттальный и коронарный срезы центрируются в соответствующем кластере. Левая часть мозга находится в левой части рисунка.
https://doi.org/10.1371/journal.pone.0117303.g003
Классификация нескольких классов по предметам
Чтобы исследовать, согласованы ли звуковые паттерны выборочной активности по категориям для разных субъектов и как результаты анализа паттернов обобщаются среди индивидуумов, мы выполнили межпредметный анализ.Поскольку точность классификации внутри предмета, полученная от предмета 4, была значительно ниже, чем точность, полученная от любого другого предмета (рис. 2), мы исключили этот предмет из дальнейшего анализа. Один из способов проверить, есть ли у разных субъектов согласованные паттерны реакции мозга, — это обучить классификатор на данных, полученных от нескольких человек, и протестировать классификатор на данных, полученных от нового человека [20]. Следовательно, в рамках предметного анализа мы итеративно не учитывали полные данные по одному предмету.Модель классификации семи звуковых категорий одновременно была обучена на четырех предметах и протестирована на оставленном предмете. Из рисунка 4 видно, что эффективность прогнозирования значительно выше вероятности (p = 7,3 × 10 -3 , односторонний t-тест с одним образцом, n = 5), что демонстрирует возможность декодирования нескольких звуковых категорий для разных субъектов. . Это указывает на то, что паттерны нейронной активности в височной коре головного мозга человека отражают категориальное содержание звуков и что эти паттерны имеют общие черты у разных субъектов.Горизонтальная линия представляет точность, достигаемую при угадывании. Сравнивая рис.2 и рис.4, мы видим, что точность классификации по предметам значительно ниже, чем точность классификации внутри субъектов (p <1 × 10 -4 , двухвыборочный двусторонний t-критерий, n 1 = 25, n 2 = 5), что указывает на то, что значительная часть нейронного представления звуковых категорий специфична для человека. Это говорит о том, что вариации между предметами влияют на эффективность классификации больше, чем вариации внутри предмета.По сравнению с внутрипредметным анализом, внутрипредметное обобщение является более сложной задачей из-за дополнительной межпредметной вариативности. Успех стратегий декодирования также будет зависеть от того, возможно ли идентифицировать функционально совпадающие области мозга у разных субъектов.
Рис. 4. Точность классификации по предметам для всех семи звуковых категорий с использованием MSVM-RFE.
Основываясь на результатах внутрипредметного анализа, данные от предмета 4 не были включены в предметный анализ.«Исключить подпункт 1» означает исключить предмет 1. Это означает, что модель обучается на данных от 2-го, 3-го, 5-го и 6-го субъектов и проверяется на данных от 1-го субъекта.
https://doi.org/10.1371/journal.pone.0117303.g004
Многоклассная классификация по усредненным предметам и предметам
Результаты многоклассовой классификации внутри и между предметами побудили нас продолжить изучение влияния усреднения по элементам и по предметам на производительность классификатора.Все четыре сценария и их взаимосвязь представлены на рис. 5.
Рис. 5. Диаграмма взаимосвязи четырех различных случаев анализа данных фМРТ.
(A) Случай WithinSub: Классификаторы обучаются и тестируются по каждому предмету отдельно; (B) Case AcrossSub: классификаторы строятся по предметам, то есть не учитывают полные данные одного предмета для тестирования и используют данные всех других предметов для обучения; (C) Case AvgItem: данные фМРТ усредняются по элементам, а классификаторы строятся по предметам на основе усредненных данных; (D) Случай AvgSub: данные фМРТ усредняются по предметам, и для этого «усредненного предмета» построены классификаторы.Для каждого случая анализа данных фМРТ, если красный прямоугольник содержит только одну тему, это указывает на внутрипредметный анализ. В противном случае анализ проводится по предметам.
https://doi.org/10.1371/journal.pone.0117303.g005
Внутриобъектный и межпредметный анализ, описанный в двух предыдущих подразделах, называется Cases WithinSub и AcrossSub, как показано в частях A и B на рис. Чтобы изучить возможность обобщения по различным образцам звука (элементам) в пределах одной и той же категории звука, мы усреднили изображения фМРТ по элементам (Case AvgItem), что привело к данным фМРТ по «усредненному элементу».Усреднение по элементам в Case WithinSub приводит к Case AvgItem (часть C на рис. 5). Кроме того, мы усреднили изображения фМРТ по субъектам, чтобы исследовать эффект усреднения по субъектам (случай AvgSub), что привело к данным фМРТ по «усредненному объекту». Усреднение по предметам в Case WithinSub приводит к Case AvgSub (часть D на рис. 5). Для случаев WithinSub и AvgSub красный прямоугольник на рис. 5 включает только одну тему, что указывает на то, что классификатор находится внутри субъекта. Для Cases AcrossSub и AvgItem красный прямоугольник включает несколько субъектов, что указывает на то, что классификатор обучается на данных из подгруппы субъектов, а затем тестируется на данных от субъекта, который не является частью этой подгруппы (рис.5).
Как описано выше, для каждого случая были построены семизначные классификаторы категорий. Усредненные значения точности классификации по каждому случаю показаны на рис. 6. Точности классификации по Case WithinSub значительно выше, чем по Case AcrossSub. Это говорит о том, что вариация между предметами влияет на эффективность классификации больше, чем вариация внутри предмета. Что еще более интересно, было обнаружено, что точность классификации в Case AvgItem значительно выше, чем в случае Case AcrossSub (p = 0.0196, двухвыборочный двусторонний t-критерий, n 1 = 5, n 2 = 5) , хотя модели, построенные для этих двух случаев, являются универсальными многоклассовыми классификаторами. Это говорит о том, что усреднение по элементам помогает повысить производительность классификатора. Перцепционная категоризация входящих звуков требует перцептивной инвариантности наборов звуков, классифицированных как принадлежащие к одной и той же категории. Усредняя изображения фМРТ по элементам, мы уменьшаем несущественные различия между различными элементами одной и той же звуковой категории и, в свою очередь, увеличиваем долю сигналов, относящихся к классификации звука.Это разумно в том смысле, что данные с большим количеством повторений по элементам более стабильны и меньше страдают от шума. При сравнении Case AvgSub и Case WithinSub, как и ожидалось, эффективность классификации по «усредненному предмету» близка к средней эффективности классификации по отдельным предметам.
Чтобы лучше понять взаимосвязь между четырьмя случаями, мы выполнили совместное картирование мозга вокселов, выбранных в разделах Cases WithinSub и AvgSub, Cases WithinSub и AvgItem, а также Cases WithinSub и AcrossSub.Поскольку Case WithinSub (внутрисубъектный анализ) является наиболее распространенным способом анализа данных фМРТ, мы сравнили выбранные воксели, которые являются общими и разными для Case WithinSub и каждого из трех других случаев. Опять же, выявленные закономерности мозговой деятельности распределяются. Несмотря на эти различия, мы обнаружили, что, что более интересно, самые большие кластеры (соответствующие приблизительно координате MNI (-65, -15, -6), (-63, -13, -3) и (-63, -14, -4) на рис.7 части (a), (b) и (c) соответственно), сформированные выбранными вокселями, которые являются общими для Case WithinSub, и каждый из трех других случаев находится примерно в тех же местах мозга, что указывает на эту классификацию в этих случаях полагаются на аналогичные области мозга (рис.7). Хотя точность различается для четырех случаев из-за вариаций субъектов и других факторов, общие воксели, обнаруженные на картах мозга соединения на рис. 7, кажутся важными для успешной классификации. Это также говорит о том, что многовоксельные модели ЖИВОГО ответа, вызванные слуховыми стимулами, информативны и могут использоваться для декодирования нескольких звуковых категорий не только внутри, но и между субъектами.
Рис. 7. Карты мозга соединения для общих вокселей между Cases WithinSub и каждым из трех других.
Мозговые карты самых больших кластеров, образованных выбранными вокселями, которые являются общими для случаев WithinSub и AvgSub, случаев WithinSub и AvgItem, а также случаев WithinSub и AcrossSub, показаны в частях (a), (b) и (c) соответственно. Левая часть мозга находится в левой части рисунка.
https://doi.org/10.1371/journal.pone.0117303.g007
Обсуждение
Варианты наименования и предмета
В этом исследовании было обнаружено, что вариации как предмета, так и предмета оказывают значительное влияние на производительность декодирования модели.
Один сложный вопрос — это степень, в которой стратегии декодирования MVPA могут быть обобщены для разных образцов одной и той же звуковой категории [9]. Восприятие звуковых категорий требует перцептивной инвариантности наборов звуков, классифицированных как принадлежащие к одной и той же категории, что приводит к более абстрактному представлению звукового сходства [1]. Успешные стратегии декодирования должны быть в состоянии увеличить процесс получения релевантной информации и уменьшить процесс обработки нерелевантной информации.Это требует определенной степени гибкости в моделировании MVPA, чтобы модель игнорировала несущественные различия между различными элементами одной и той же звуковой категории и выбирала аналогичные функции в качестве основы для абстрактных представлений звуковых категорий. Однако способность моделей MVPA идентифицировать характерный образец ответа мозга, соответствующий одной звуковой категории, зависит от выбора звуковых образцов как принадлежащих к этой категории. Если звуковая категория хорошо представлена выбранными образцами, упрощается обобщение для разных экземпляров одной и той же звуковой категории.Усредняя изображения фМРТ по элементам, мы уменьшаем несущественные различия между различными элементами одной и той же звуковой категории и, в свою очередь, увеличиваем долю сигналов, относящихся к классификации звука. Усредненный элемент, по-видимому, обладает наибольшим количеством свойств, определяющих эту категорию, и, следовательно, может считаться наиболее типичным образцом этого класса. Подобно теории образцов в литературе по визуальной категоризации, категоризация основана на сравнении стимула со всеми ранее категоризированными образцами всех категорий [33].Наличие большего количества образцов звука в одной звуковой категории может помочь улучшить производительность декодирования модели.
Звуки одной категории, хотя и сильно варьируются, могут иметь значительное акустическое сходство по сравнению со звуками между категориями. В этом сценарии модели MVPA потенциально могут учитывать физические, а не категориальные различия во время обучения. Подобно предыдущим исследованиям [2, 3], все стимулы в этом исследовании были повторно дискретизированы с одинаковой частотой дискретизации и нормализованы к одному и тому же уровню интенсивности и основной частоте.Однако мы не можем полностью исключить роль акустических переменных, поскольку семантические и акустические категории могут быть коррелированы. Совершенная нормализация акустических различий создаст набор идентичных стимулов [3]. Следовательно, ожидается некоторая акустическая изменчивость по категориям. Отношения между звуковыми категориями и акустическими характеристиками сложны. Предыдущая работа установила, что люди классифицируют звуковые образцы на основе семантических характеристик, а не строго перцептуальных, что означает, что семантические свойства не могут быть напрямую сведены к причинным физическим параметрам [34].Хотя воспринимаемое сходство между звуками окружающей среды в значительной степени определяется акустическими характеристиками, категоризация звука хуже предсказывается акустическими характеристиками [35].
Еще один сложный вопрос — обобщение модели декодирования по предметам. Известно, что не всегда существует точное пространственное соответствие между гомологичными функциональными локациями в разных индивидуальных мозгах, даже когда используются продвинутые процедуры выравнивания [9]. Такое предметное изменение неизбежно затмевает любое общесубъектное обобщение.Хотя существуют вариации в анатомии субъектов и методологические трудности в совместной регистрации между субъектами, возникло нейронное сходство с точки зрения местоположения и амплитуд активации вокселей, используемых классификатором для определения категории стимула [36]. В настоящее время растет количество исследований, показывающих, что MVPA может раскрывать инвариантные паттерны нейронной активности у субъектов [20, 37, 38].
Локализованное и распределенное представление звуковых категорий
В литературе по фМРТ-исследованиям репрезентаций звуковых категорий мозгом предыдущие модели предполагают иерархическую обработку слуховых категорий в слуховой коре.В этих моделях верхняя височная кора головного мозга организована в специализированных областях, среди которых нейронная обработка звука переходит от анализа его физических составляющих низкого уровня к более высоким измерениям восприятия. Несколько групп использовали одномерные подходы и определили избирательные области в слуховой коре, которые потенциально объясняют дифференциацию звуковых категорий [3, 4, 39]. Однако Staeren et al . обнаружили, что представления звуковых категорий в верхней височной коре широко распространены [2].В нашем исследовании звуковые карты мозга с отбором по категориям были идентифицированы на основе многоклассовой классификации и выявили распределенные паттерны мозговой активности вдоль височной коры. Это согласуется с предыдущими исследованиями, показывающими, что информация в пространственно распределенных паттернах может отражать более абстрактный уровень восприятия представления звуковых категорий [1, 2]. Это предполагает, что представления мозга о звуковых категориях могут возникать в результате совместного кодирования информации, происходящей в наборе областей, связанных не только с высокоуровневой, но и с низкоуровневой обработкой слуха.В будущих исследованиях следует рассмотреть взаимодействие между семантическими и физическими свойствами звуковых категорий и их взвешивание свойств при кодировании звука, в том числе то, как представлены звуки в одной семантической категории с разными или одинаковыми акустическими характеристиками, а также являются ли центральные и распределенные представления. относящиеся к категориальным иерархиям.
Локализованные и распределенные виды категоризации звука не могут быть полностью несовместимы друг с другом.Одна область может играть доминирующую роль, в то время как несколько различных областей предлагают дополнительную поддержку. Кумар и др. . доказывал возможность включения роли основного тона в распределенную систему для представления основного тона человеческого мозга [40]. Аналогичные аргументы можно привести в пользу представления звуковых категорий в человеческом мозге.
Мы признаем, что размер выборки в нашем текущем исследовании относительно невелик, тем не менее, этот размер выборки согласуется с аналогичными исследованиями, описанными в литературе [1, 2, 5, 19, 20].Мы считаем, что наше исследование демонстрирует, что можно обобщить звуковую категоризацию с помощью измерений фМРТ от одного слушателя к другому. Однако мы не утверждаем, что полученные нами данные могут быть обобщены для всех слушателей в популяции. Кроме того, мы признаем, что наши результаты ограничены семью выбранными звуковыми категориями, и необходимы дальнейшие исследования, чтобы изучить, как другие звуковые категории представлены в мозгу. Тем не менее, мы включили ряд звуковых категорий, которые можно найти в мире природы.Таким образом, мы считаем, что наши результаты говорят о фундаментальных принципах кодирования звуковых категорий в головном мозге.
Резюме
В этом исследовании мы исследовали представление и обработку звуковых категорий в височной коре человека с использованием методов фМРТ и MVPA высокого разрешения. Важно отметить, что мы изучили преимущества использования MSVM-RFE для одновременного декодирования нескольких категорий звука. Надежная классификация паттернов является сложной задачей из-за наличия нескольких категорий звуков, высокой размерности набора данных и небольших размеров выборки для каждого стимула и категории.
Мы показали, что для всех классификаций модель MSVM-RFE смогла изучить функциональную связь между множеством звуковых категорий и соответствующими вызванными пространственными паттернами и классифицировать немаркированные звуковые паттерны значительно выше вероятности. Это указывает на возможность декодирования нескольких звуковых категорий не только внутри, но и между предметами. Карты мозга с отбором по категориям звуков были определены на основе мультиклассовой классификации и выявили распределенные паттерны мозговой активности.Наш межсубъектный анализ показывает, что паттерны нейронной активности в височной коре головного мозга человека отражают категориальное содержание звуков и что эти паттерны имеют общие черты у разных субъектов. Однако вариации между предметами влияют на эффективность классификации больше, чем вариации внутри предмета, поскольку внутрипредметный анализ имеет значительно более низкую точность классификации, чем внутрипредметный анализ. Кроме того, мы показываем, что путем усреднения изображений фМРТ по элементам можно значительно повысить эффективность классификации по предметам.После усреднения изображений фМРТ по элементам несущественные различия между различными элементами одной и той же звуковой категории уменьшаются, и, в свою очередь, увеличивается доля сигналов, относящихся к классификации звука. Это требует определенной степени гибкости в моделировании MVPA, чтобы модель игнорировала несущественные различия между разными экземплярами одной и той же звуковой категории и выбирала аналогичные функции в качестве основы для абстрактных представлений звуковых категорий. Кроме того, это исследование улучшает наше понимание важного и нерешенного вопроса, т.е.е., уровень, до которого модели декодирования MVPA могут быть обобщены по множеству категорий звука, по разным предметам и по разным образцам звука в одной и той же категории.
Благодарности
Авторы хотели бы поблагодарить двух анонимных рецензентов за их ценные комментарии, а также Ника Паевски за помощь в подготовке рукописи.
Вклад авторов
Задумал и спроектировал эксперименты: FZ JK TP PW. Проведены эксперименты: JK TP PW.Проанализированы данные: FZ JW JK PW. Написал статью: FZ JW PW.
Список литературы
- 1. Лей А., Вромен Дж., Хаусфельд Л., Валенте Дж., Де Верд П. и др. (2012) Изучение новых звуковых категорий формирует паттерны нейронных реакций в слуховой коре человека. J. Neurosci. 32: 13273–13280. pmid: 22993443
- 2. Staeren N, Renvall H, De Martino F, Goebel R, Formisano E (2009) Звуковые категории представлены как распределенные паттерны в слуховой коре человека.Curr. Биол. 19: 498–502. pmid: 19268594
- 3. Ливер AM, Раушекер JP (2010) Кортикальное представление естественных сложных звуков: эффекты акустических характеристик и категории слуховых объектов. J. Neurosci. 30: 7604–7612. pmid: 20519535
- 4. Раушекер Дж. П., Скотт С. К. (2009) Карты и потоки в слуховой коре: нечеловеческие приматы освещают обработку человеческой речи. Nat. Neurosci. 12: 718–724. pmid: 19471271
- 5. Формизано Э, Де Мартино Ф, Бонте М., Гебель Р. (2008) «Кто» говорит «Что»? На основе мозга.Расшифровка человеческого голоса и речи. Наука 7: 970–973.
- 6. Kay KN, Naselaris T, Prenger RJ, Gallant JL (2008) Идентификация естественных изображений из активности человеческого мозга. Природа 452: 352–355. pmid: 18322462
- 7. Naselaris T, Prenger RJ, Kay KN, Oliver M, Gallant JL (2009) Байесовская реконструкция естественных изображений из активности человеческого мозга. Нейрон 63: 902–915. pmid: 19778517
- 8. Мейер К., Каплан Дж. Т., Эссекс Р., Уэббер С., Дамасио Н. и др.(2010) Прогнозирование визуальных стимулов на основе активности слуховой коры. Nat. Neurosci. 13: 667–668. pmid: 20436482
- 9. Haynes JD, Rees G (2006) Расшифровка психических состояний по активности мозга у людей. Nat. Rev. Neurosci. 7: 523–534. pmid: 16791142
- 10. Weil RS, Rees G (2010) Расшифровка нейронных коррелятов сознания. Curr. Opin. Neurol. 23: 649–655. pmid: 20881487
- 11. Тонг Ф., Пратте М.С. (2012) Расшифровка моделей активности человеческого мозга.Анну. Rev. Psychol. 63: 483–509. pmid: 21943172
- 12. Raizada RDS, Kriegeskorte N (2010) ФМРТ с информацией о паттернах: новые вопросы, которые она открывает, и проблемы, с которыми она сталкивается. Int. J. Imag. Syst. Tech. 20: 31–41.
- 13. Ханке М., Хальченко Ю.О., Седерберг П.Б., Хансон С.Дж., Хаксби СП и др. (2009) PyMVPA: Набор инструментов Python для многомерного анализа паттернов данных фМРТ. Нейроинформатика 7: 37–53. pmid: 19184561
- 14. Haxby JV, Gobbini MI, Furey ML, Ishai A, Schouten JL, et al.(2001) Распределенные и перекрывающиеся изображения лиц и предметов в вентральной височной коре. Наука 293: 2425–2430. pmid: 11577229
- 15. Макдермотт Дж. Х., Шемич М., Симончелли Е. П. (2013) Сводная статистика слухового восприятия. Nat. Neurosci. 16: 493–498. pmid: 23434915
- 16. Ариэли Д. (2001) Видящие множества: представление с помощью статистических свойств. Psychol. Sci. 12: 157–162. pmid: 11340926
- 17. Chong SC, Treisman A (2003) Представление статистических свойств.Зрение. Res. 43: 393–404. pmid: 12535996
- 18. Балас Б., Накано Л., Розенхольц Р. (2009) Сводно-статистическое представление в периферическом зрении объясняет визуальную скученность. J. Vis. 9: 13 11–18.
- 19. Meier JD, Aflalo TN, Kastner S, Graziano MS (2008) Сложная организация первичной моторной коры человека: исследование фМРТ с высоким разрешением. J. Neurophysiol. 100: 1800–1812. pmid: 18684903
- 20. Каплан Дж. Т., Мейер К. (2012) Анализ многомерных паттернов выявляет общие нейронные паттерны у людей во время сенсорного наблюдения.Neuroimage 60: 204–212. pmid: 22227887
- 21. Тайс Б, Каррелл Т (1997) Тон. Университет Небраски.
- 22. Boersma P, Weenink D (2001) Praat, система для компьютерной фонетики. Глот. Международный 5: 341–345.
- 23. Cox RW (1996) AFNI: программное обеспечение для анализа и визуализации функциональных магнитно-резонансных нейровизуальных изображений. Comput. Биомед. Res. 29: 162–173. pmid: 8812068
- 24. Де Мартино Ф., Валенте Дж., Стаерен Н., Эшбернер Дж., Гебель Р. и др.(2008) Сочетание многомерного выбора вокселей и вспомогательных векторных машин для отображения и классификации пространственных паттернов фМРТ. Нейроизображение 43: 44–58. pmid: 18672070
- 25. Норман К.А., Полин С.М., Детре Г.Дж., Хаксби Дж.В. (2006) Помимо чтения мыслей: анализ многовоксельного паттерна данных фМРТ. Trends Cogn. Sci. 10: 424–430. pmid: 16899397
- 26. Formisano E, De Martino F, Valente G (2008) Многомерный анализ временных рядов fMRI: классификация и регрессия ответов мозга с использованием машинного обучения.Magn. Резон. Изображение 26: 921–934. pmid: 18508219
- 27. Guyon I, Weston J, Barnihill S, Vapnik V (2002) Выбор гена для классификации рака с использованием машин опорных векторов. Мах. Учение 46: 389–422.
- 28. Вапник V (1998) Статистическая теория обучения. Спрингер, штат Нью-Йорк.
- 29. Zhou X, Tuck DP (2007) MSVM-RFE: расширения SVM-RFE для многоклассового отбора генов на данных микрочипа ДНК. Биоинформатика 23: 1106–1114. pmid: 17494773
- 30.Fan RE, Chang KW, Hsieh CJ, Wang XR, Lin CJ (2008) LIBLINEAR: Библиотека для большой линейной классификации. J. Mach. Учить. Res. 9: 1871–1874.
- 31. Crammer K, Singer Y (2000) Об обучаемости и дизайне выходных кодов для мультиклассовых задач. Comput. Учить. Теория: 35–46.
- 32. Виттен Д.М., Тибширани Р. (2011) Наказанная классификация с использованием линейного дискриминанта Фишера. J. R. Stat. Soc. Серия B Стат. Методол. 73: 753–772. pmid: 22323898
- 33.Нософский Р.М. (1986) Внимание, сходство и отношение категоризации идентификации. J. Exp. Psychol. Быт. 115: 39–57. pmid: 2937873
- 34. Dubois D, Guastavino C, Raimbault M (2006) Когнитивный подход к городским звуковым ландшафтам: использование вербальных данных для доступа к повседневным слуховым категориям. Acta Acustica объединилась с Acustica 92: 865–874.
- 35. Gygi B, Kidd GR, Watson CS (2007) Сходство и категоризация звуков окружающей среды.Восприятие и психофизика 69: 839–855.
- 36. Шинкарева С.В., Малаве В.Л., Мейсон Р.А., Митчелл Т.М., Джаст М.А. (2011) Общность нейронных представлений слов и изображений. Нейроизображение 54: 2418–2425. pmid: 20974270
- 37. Clithero JA, Smith DV, Carter RM, Huettel SA (2011) Классификаторы внутри и между участниками выявляют различное нейронное кодирование информации. Нейроизображение 56: 699–708. pmid: 20347995
- 38. Etzel JA, Valchev N, Keysers C (2011) Влияние определенных методологических решений на многомерный анализ данных фМРТ с машинами опорных векторов.Нейроизображение 54: 1159–1167. pmid: 20817107
- 39. Биндер Дж. Р., Фрост Дж. А., Хаммеке Т. А., Беллгоуэн П. С., Спрингер Дж. А. и др. (2000) Активация височной доли человека речью и неречевыми звуками. Cereb Cortex 10: 512–528. pmid: 10847601
- 40. Kumar S, Schonwiesner M (2012) Отображение представления человеческого голоса в распределенной системе с использованием записи и моделирования с помощью электрода глубины. J Neurosci 32: 13348–13351. pmid: 23015425
Расшифровка четырех различных звуковых категорий в слуховой коре с использованием функциональной ближней инфракрасной спектроскопии
Основные моменты
- •
Исследуется асимметрия функциональных гемодинамических реакций на 4 звуковые категории с использованием fNIRS.
- •
В качестве признаков для классификации используются среднее значение, наклон и асимметрия сигналов оксигемоглобина.
- •
Для ИМК, основанного на слуховых реакциях, рекомендуется использование сигналов левого полушария.
Abstract
Способность слуховой коры головного мозга различать различные звуки важна в повседневной жизни. В этом исследовании изучали, можно ли с помощью функциональной ближней инфракрасной спектроскопии (fNIRS) определить активацию слуховой коры, вызванную различными звуками.Гемодинамические ответы (HRs) в обоих полушариях с использованием fNIRS были измерены у 18 субъектов, подвергая их четырем звуковым категориям (англоязычная, неанглийская речь, раздражающие звуки и звуки природы). В качестве признаков для классификации различных сигналов использовались среднее значение, наклон и асимметрия сигнала оксигемоглобина (HbO). Что касается языковых стимулов, ЧСС, вызванные понятной речью (английской), наблюдались в более широком регионе мозга, чем те, которые были вызваны неанглоязычной речью.Кроме того, амплитуда сигналов HbO, вызванных англоязычной речью, была выше, чем у неанглоязычной речи. Соотношение пиковых значений неанглийской и английской речи составило 72,5%. Кроме того, область мозга, вызываемая раздражающими звуками, была шире, чем звуки природы. Однако сила сигнала звуков природы была выше, чем у раздражающих звуков. Наконец, для целей интерфейса мозг-компьютер (BCI) к четырем категориям звуков были применены классификаторы линейного дискриминантного анализа (LDA) и машины опорных векторов (SVM).Общая эффективность классификации для левого полушария была выше, чем для правого полушария. Поэтому для расшифровки слуховых команд рекомендуется левое полушарие. Кроме того, в двухклассной классификации сравнение раздражающих звуков и звуков природы обеспечивает более высокую точность классификации, чем сравнение английской и неанглоязычной речи. Наконец, LDA работает лучше, чем SVM.
Ключевые слова
Функциональная ближняя инфракрасная спектроскопия (fNIRS)
Слуховая кора
Классификация
Множественные звуковые категории
Сокращения
fNIRSФункциональная ближняя инфракрасная спектроскопия
LDA Линейный дискриминантный анализ Рекомендуемые статьиЦитирующие статьи (0) Полный текстCopyright © 2016 Elsevier B.V. Все права защищены.
Рекомендуемые статьи
Цитирование статей
Замещение длинного хвоста с помощью древовидной структуры декодирования сложных категорий | Труды Ассоциации компьютерной лингвистики
Одной из неотъемлемых проблем задачи супертэгов является разреженность выходного пространства. Однако это недостаточно отражено в стандартных наборах оценок, как показано на Рисунке 1b. Чтобы проверить, насколько хорошо модели на самом деле обобщаются для длинного хвоста, мы оцениваем их на альтернативно выборочных обучающих и оценочных разбиениях данных WSJ (таблица 6), а также в областях, расходящихся с обучающим набором WSJ (таблица 7).Эти эксперименты в значительной степени подтверждают наши выводы из стандартного набора оценок Rebank, в то время как изменение в распределении категорий оказывает несколько важных эффектов на нашу способность оценивать обобщение модели: во-первых, производительность OOV намного выше для перераспределенных данных (таблица 6), чем для стандартных Тестовые разбиения в таблицах 3, 4 и 7 подчеркивают возможности обобщения всех конструктивных моделей и, в свою очередь, предполагают, что категории OOV в разделе 23 WSJ и PMB действительно сложны, шумны или иным образом несовместимы с данными обучения.Во-вторых, доля оценочных токенов категорий менее 10 раз в обучении составляет 1,6% в PMB и 3,8% в наших перераспределенных оценочных данных Rebank, по сравнению с только ≈0,2% в стандартных тестовых наборах CCGbank и Rebank. Это 7–16-кратное увеличение относительного размера делает хвост гораздо более значимым для общей производительности. И действительно, мы наблюдаем немного меньший разрыв в общей точности между наиболее эффективными неконструктивными и наиболее эффективными конструктивными системами в Таблице 7 (0,08 на Wiki, 0.11 на PMB) по сравнению с 0,13 в таблицах 3 и 4, а в таблице 6 AddrMLP даже явно превосходит неконструктивные модели. В-третьих, эффективность по редким и невидимым категориям теперь может быть измерена гораздо более надежно благодаря большему количеству абсолютных редких и невидимых категорий. Мы предоставляем подробный анализ этого подмножества тегов в п. 6.2.
Как для внутренних, так и для внешних данных разрыв в производительности между неконструктивными MLP и AddrMLP в наиболее часто встречающихся категориях минимален и фактически находится в пределах стандартного отклонения.Учитывая тенденцию, которую мы наблюдаем от Таблиц 3 и 4 до Таблиц 6 и 7, возможность обобщения до длинного хвоста вполне может перевесить любое незначительное улучшение наиболее часто встречающихся категорий при применении к еще более разнообразным данным на других языках и на разных языках. .
Нейронные механизмы контроля внимания для объектов: декодирование альфа-канала ЭЭГ при прогнозировании лиц, сцен и инструментов альфа указывает на очаговое корковое усиление и повышенное альфа указывает на подавление.Это наблюдалось для пространственного избирательного внимания и внимания к характеристикам стимула, таким как цвет по сравнению с движением. Мы исследовали, включает ли внимание к объектам подобные альфа-опосредованные изменения фокальной корковой возбудимости. В эксперименте 1 20 добровольцев (8 мужчин; 12 женщин) были направлены (прогноз 80%) на пробную основу к различным объектам (лицам, сценам или инструментам). Поддержка векторного машинного декодирования альфа-паттернов мощности показала, что на поздних этапах (задержка> 500 мс) в предварительном периоде от метки к цели только альфа ЭЭГ различалась с категорией объекта, подлежащего наблюдению.В эксперименте 2, чтобы исключить возможность того, что расшифровка физических характеристик сигналов привела к нашим результатам, 25 участников (9 мужчин; 16 женщин) выполнили аналогичную задачу, в которой реплики не предсказывали категорию объекта. Альфа-декодирование теперь имело значение только в ранний (
<200 мс) предварительный период. В эксперименте 3, чтобы исключить возможность того, что различия в постановке задач между разными категориями объектов привели к результатам нашего эксперимента 1, 12 участников (5 мужчин; 7 женщин) выполнили задачу прогнозирования, в которой задача распознавания различных объектов была идентична для разных категорий объектов. .Результаты воспроизведены в эксперименте 1. В совокупности эти результаты подтверждают гипотезу о том, что нейронные механизмы зрительного избирательного внимания включают фокальные корковые изменения альфа-мощности не только для простого пространственного и особенного внимания, но также и для объектного внимания высокого уровня у людей.ЗНАЧИМОЕ ЗАЯВЛЕНИЕ Внимание — это когнитивная функция, которая позволяет выбирать релевантную информацию из сенсорных входов, чтобы ее можно было обработать для поддержки целенаправленного поведения.Визуальное внимание широко изучается, но нейронные механизмы, лежащие в основе отбора визуальной информации, остаются неясными. Колебательная активность ЭЭГ в альфа-диапазоне (8–12 Гц) нервных популяций, восприимчивых к целевым визуальным стимулам, может быть частью механизма, поскольку считается, что альфа отражает фокальную нервную возбудимость. Здесь мы показываем, что активность альфа-диапазона, измеренная с помощью ЭЭГ скальпа участников, варьируется в зависимости от конкретной категории объекта, выбранного вниманием. Это открытие подтверждает гипотезу о том, что активность альфа-диапазона является фундаментальным компонентом нейронных механизмов внимания.
Введение
Селективное внимание — это фундаментальная когнитивная способность, которая облегчает обработку релевантной для задачи перцепционной информации и подавляет отвлекающие сигналы. Влияние внимания на восприятие было продемонстрировано в улучшении поведенческих характеристик (Posner, 1980) и изменении кривых психофизической настройки (Carrasco and Barbot, 2019). У людей эти преимущества восприятия присутствующих стимулов сочетаются с повышенными сенсорно-вызванными потенциалами (Van Voorhis and Hillyard, 1977; Eason, 1981; Mangun and Hillyard, 1991; Eimer, 1996; Luck et al., 2000) и усиление гемодинамических реакций (Corbetta et al., 1990; Heinze et al., 1994; Mangun et al., 1998; Tootell et al., 1998; Martínez et al., 1999; Hopfinger et al., 2000; Giesbrecht et al., 2003). У животных электрофизиологические записи показывают, что сенсорные нейроны, реагирующие на обслуживаемые раздражители, имеют более высокую частоту возбуждения, чем таковые на необслуживаемые раздражители (Moran and Desimone, 1985; Luck et al., 1997), улучшенное соотношение сигнал-шум при передаче информации (Mitchell et al. ., 2009; Briggs et al., 2013) и усиленные колебательные ответы (Fries et al., 2001), которые поддерживают более высокую межреальную функциональную связность (Bosman et al., 2012).
Большинство моделей избирательного внимания постулируют, что нисходящие управляющие сигналы внимания, возникающие в корковых сетях более высокого уровня, искажают обработку сенсорных систем (Nobre et al., 1997; Kastner et al., 1999; Corbetta et al., 2000; Hopfinger). и др., 2000; Корбетта, Шульман, 2002; Петерсен, Познер, 2012). Однако остается неясным, как именно нисходящие сигналы влияют на сенсорную обработку в сенсорной коре.Один из возможных механизмов включает модуляцию альфа-колебаний ЭЭГ (8–12 Гц). Когда скрытое внимание направлено на одну сторону поля зрения, альфа-сигнал сильнее подавляется в противоположном полушарии (Worden et al., 2000; Sauseng et al., 2005; Thut et al., 2006; Rajagovindan and Ding, 2011). Считается, что это латерализованное уменьшение альфа-канала отражает увеличение возбудимости коры головного мозга в сенсорных нейронах, соответствующих задаче, для облегчения обработки предстоящих стимулов (Romei et al., 2008; Дженсен и Мазахери, 2010; Климеш, 2012). Связь между нисходящей активностью в лобно-теменной системе контроля внимания и альфа в сенсорной коре была предположена в исследованиях с использованием транскраниальной магнитной стимуляции для контроля областей (Capotosto et al., 2009, 2017), одновременных исследованиях ЭЭГ-фМРТ (Zumer et al., 2014; Liu et al., 2016) и магнитоэнцефалографии (Popov et al., 2017).
Хотя большинство исследований роли альфы в избирательном зрительном внимании сосредоточено на пространственном внимании, альфа-механизмы могут быть более общими (Jensen and Mazaheri, 2010).Селективное внимание к визуальным характеристикам низкого уровня — движению по сравнению с цветом — также, как было показано, модулирует альфа-канал, который был локализован в областях MT и V4 с использованием моделирования ЭЭГ у людей (Snyder and Foxe, 2010). Следовательно, похоже, что связанная с вниманием альфа-модуляция может происходить на нескольких ранних уровнях сенсорной обработки в зрительной системе, причем локус альфа-модуляции функционально соответствует типу визуальной информации, на которую нацелено внимание. Неизвестно, участвует ли альфа-механизм также в контроле внимания над более высокими уровнями корковой визуальной обработки, например, вниманием к объектам.В настоящем исследовании мы проверили гипотезу о том, что альфа-модуляция является механизмом избирательного внимания к объектам путем записи ЭЭГ участников, выполняющих задачу упреждающего внимания к объектам, с использованием следующих трех категорий объектов: лица, сцены и инструменты. Используя методы декодирования ЭЭГ, мы подтверждаем эту гипотезу, обнаруживая объектно-специфические модуляции альфа-канала во время упреждающего внимания к различным категориям объектов.
Материалы и методы
Обзор
Настоящее исследование состояло из трех экспериментов.Эксперимент 1 является основным экспериментом, в котором мы проверяли, можно ли различить топологию альфа-диапазона ЭЭГ в зависимости от объектно-ориентированного состояния внимания. Анализ данных ЭЭГ включал построение топографической карты разности мощностей и декодирование мощности альфа-диапазона опорным вектором (SVM) для количественной оценки того, содержит ли альфа-диапазон ЭЭГ информацию о наблюдаемой категории объекта. В экспериментах 2 и 3 мы проверили две альтернативные интерпретации наших результатов из эксперимента 1.В частности, в эксперименте 2 мы проверили, могла ли точность декодирования в подготовительном периоде между началом сигнала и целевым началом, обнаруженная в эксперименте 1, быть основана на различиях в сенсорных процессах, вызываемых в зрительной системе различными стимулами сигнала, поскольку Свойства физических стимулов сигналов для трех различных условий внимания к объекту отличались друг от друга (треугольник против квадрата против круга). В эксперименте 3 мы исследовали, могли ли различия в альфа-топографии в разных условиях внимания к объекту в эксперименте 1 быть результатом разных наборов задач в трех условиях внимания объекта, а не отражением механизмов внимания, основанных на объектах, в зрительной коре головного мозга.
Участники
Все участники были здоровыми студентами-волонтерами из Калифорнийского университета в Дэвисе; имел нормальное или скорректированное до нормального зрение; дали информированное согласие; и получили зачетное время или денежную компенсацию за свое время. В эксперименте 1 данные ЭЭГ были записаны у 22 добровольцев (8 мужчин; 14 женщин). Два добровольца решили прекратить свое участие в середине эксперимента; данные оставшихся 20 участников (8 мужчин; 12 женщин) использовались для всех анализов.В эксперименте 2 данные ЭЭГ были записаны у 29 студентов; наборы данных от 4 участников были отклонены на основании непримиримого шума в данных или несоответствия субъектов, в результате чего был получен окончательный набор данных от 25 участников (9 мужчин; 16 женщин), который был использован для дальнейшего анализа декодирования. В эксперименте 3 данные ЭЭГ были записаны у 12 добровольцев (5 мужчин; 7 женщин). Наборы данных от двух участников были отклонены на основании непримиримого шума в данных ЭЭГ, в результате чего был получен окончательный набор данных ЭЭГ от 10 участников (5 мужчин и 5 женщин), который использовался для дальнейшего анализа декодирования.
План эксперимента
В исследовании использовался дизайн внутри субъектов. В экспериментах 1 и 3 мы исследовали распределение мощности альфа-сигнала ЭЭГ на коже черепа в зависимости от категории обслуживаемых объектов в упреждающей задаче на внимание с тремя категориями объектов (лица, сцены и инструменты). В эксперименте 2 мы исследовали распределение мощности альфа-сигнала ЭЭГ на коже черепа во время послеоперационного периода, когда три категории объектов не были посещены заранее. Подробная информация о задаче на внимание на объектном вызове, задаче без ответа и статистическом анализе представлена ниже.
Статистический анализ
Данные поведенческой реакции были проанализированы с помощью обобщенной линейной смешанной модели с гамма-распределением (Lo and Andrews, 2015) со случайным эффектом субъекта и фиксированными эффектами категории объекта и достоверности сигнала для количественной оценки эффекта достоверности сигнала от времени реакции (RT).
Различия в топографиях альфа-мощности скальпа ЭЭГ в зависимости от состояния сигнала были статистически проанализированы с использованием подхода декодирования SVM и непараметрического кластерного теста перестановок и моделирования Монте-Карло.Статистический тест на основе кластера использовался для управления проблемами множественного сравнения, которые возникают, когда тесты t выполняются во все моменты времени в течение эпохи (Bae and Luck, 2018). Подробности статистического теста на альфа-мощность ЭЭГ описаны ниже.
Эксперимент 1
Аппараты и раздражители.
Участники удобно расположились в электрически экранированном звукопоглощающем помещении (ETS-Lindgren). Стимулы предъявлялись на светодиодном мониторе VIEWPixx / EEG (модель VPX-VPX-2006A, VPixx Technologies) на расстоянии просмотра 85 см, центрированном по вертикали на уровне глаз.Диагональ дисплея составляла 23,6 дюйма, разрешение — 1920 × 1080 пикселей, частота обновления — 120 Гц. Комната для записи и предметы в ней были окрашены в черный цвет, чтобы избежать отраженного света, и она слабо освещалась лампами постоянного тока.
Каждое испытание начиналось с псевдослучайно выбранного представления одного из трех возможных типов сигналов в течение 200 мс (треугольник, квадрат или круг 1 ° × 1 °, используя PsychToolbox; Brainard, 1997; Рис. 1 A ). Действительные сигналы информировали участников, какая категория целевых объектов (лицо, сцена или инструмент, соответственно), вероятно, появится впоследствии (вероятность 80%).Реплики располагались на 1 ° выше центральной точки фиксации. После псевдослучайно выбранных асинхронностей начала стимула (SOA; 1000–2500 мс) от начала сигнала, целевые стимулы (квадратное изображение 5 ° × 5 °) предъявлялись при фиксации в течение 100 мс. В случайных 20% испытаний реплики были недействительными, неправильно информируя участников о предстоящей категории целевых объектов. Для этих недействительных испытаний целевое изображение было нарисовано с равной вероятностью из любой из двух категорий объектов без привязки. Все стимулы предъявлялись на сером фоне.Белая точка фиксации постоянно присутствовала в центре дисплея.
Рисунок 1.A , Пример пробной последовательности для задачи «Внимание». Каждое испытание начиналось с предъявления символической подсказки, которую испытуемые учили, предсказывали (80%) конкретную категорию объекта. После периода ожидания (от метки к цели), изменяющегося от 1,0 до 2,5 с, было представлено изображение объекта (лица, сцены или инструмента). В 20% испытаний было представлено одно из двух изображений цели без привязки.Испытуемые должны были быстро и точно различать аспекты изображений как в ожидаемых, так и в неожиданных условиях (подробности см. В тексте). B , Примеры целевых изображений, представленных в задаче на внимание. Изображения лиц, сцен и инструментов были выбраны из онлайн-баз данных.
Целевые изображения (Рис. 1 B ) были выбраны из 60 возможных изображений для каждой категории объектов. Все целевые изображения были собраны из Интернета. Изображения лиц были фронтальными, с нейтральным выражением лица, лицами белой национальности, обрезанными и помещенными на белом фоне (Righi et al., 2012). Полнокадровые изображения сцены были взяты из коллекции естественных сцен Техасского университета в Остине (Geisler and Perry, 2011) и коллекции сцен кампуса (Burge and Geisler, 2011). Обрезанные изображения инструментов на белом фоне были взяты из Банка стандартизированных стимулов (Brodeur et al., 2014). Псевдослучайно распределенный интервал между испытаниями (ITI; 1500–2500 мс) отделял целевое смещение от начала сигнала следующего испытания. Каждый набор из 60 изображений объектов состоял из 30 изображений следующих различных подкатегорий: мужские / женские лица, городские / природные сцены и инструменты с питанием / без питания.
Запись ЭЭГ.
Необработанные данные ЭЭГ были получены с помощью 64-канальной системы активных электродов Brain Products actiCAP (Brain Products) и оцифрованы с помощью входной платы и усилителя Neuroscan SynAmps2 (Compumedics). Сигналы регистрировались с помощью программного обеспечения для сбора данных Scan 4.5 (Compumedics) с частотой дискретизации 1000 Гц и полосой пропускания от постоянного тока до 200 Гц. Шестьдесят четыре активных электрода Ag / AgCl помещали в подогнанные эластичные колпачки, используя следующий монтаж в соответствии с международной системой 10–10 (Jurcak et al., 2007): FP1, FP2, AF7, AF3, AFz, AF4, AF8, F7, F5, F3, F1, Fz, F2, F4, F6, F8, FT9, FT7, FC5, FC3, FC1, FCz, FC2, FC4, FC6, FT8, FT10, T7, C5, C3, C1, Cz, C2, C4, C6, T8, TP9, TP7, CP5, CP3, CP1, CPz, CP2, CP4, CP6, TP8, TP10, P7, P5, P3, P1, Pz, P2, P4, P6, P8, PO7, PO3, POz, PO4, PO8, PO9, O1, Oz, O 2 и PO10; с каналами AFz и FCz, назначенными как наземный и оперативный, соответственно. Кроме того, электроды в точках TP9 и TP10 были размещены непосредственно на левом и правом сосцевидном отростке.Электрод Cz был ориентирован на макушку головы каждого участника путем измерения спереди назад от назиона до иона и справа налево между преаурикулярными точками. Гель-электролит с высокой вязкостью наносился на каждое место электрода для облегчения проводимости между электродом и кожей головы, а значения импеданса поддерживались на уровне <25 кОм. Непрерывные данные сохранялись в отдельных файлах, соответствующих каждому пробному блоку парадигмы стимула.
Предварительная обработка ЭЭГ.
Все процедуры предварительной обработки данных были выполнены с помощью набора инструментов EEGLAB MATLAB (Delorme and Makeig, 2004).Для каждого участника все файлы данных ЭЭГ были объединены в единый набор данных перед обработкой данных. Каждый набор данных был визуально проверен на наличие плохих каналов, но таких каналов не наблюдалось. Данные были отфильтрованы с помощью окна Хэмминга sinc FIR (конечный импульсный отклик) (1–83 Гц), а затем субдискретизированы до 250 Гц. Данные были алгебраически привязаны к среднему значению для всех электродов, а затем были отфильтрованы нижние частоты до 40 Гц. Данные были привязаны к периоду от 500 мс до начала сигнала до 1000 мс после начала сигнала, так что ожидаемые данные всех испытаний можно было изучить вместе.Данные были визуально проверены, чтобы отметить и отклонить испытания с помощью морганий и движений глаз, которые произошли во время представления сигнала. Затем была использована разложение независимого компонентного анализа для удаления артефактов, связанных с морганиями и движениями глаз.
Анализ ЭЭГ.
Мы использовали процедуру спектральной плотности мощности с функцией периодограммы (x) Matlab (длина окна, 500 мс; длина шага, 40 мс), чтобы извлечь мощность в альфа-диапазоне для каждого электрода, а также для каждого участника и сигнала. условие.Мощность в альфа-диапазоне рассчитывалась как среднее значение мощности от 8 до 12 Гц. Для каждого участника и условия сигнала результаты спектральной плотности мощности вычислялись в отдельных испытаниях, а затем усреднялись по испытаниям. Усредненные результаты спектральной плотности мощности использовались для визуального изучения топографии мощности альфа-диапазона в различных условиях сигнала.
Мы реализовали анализ декодирования, чтобы количественно оценить, было ли внимание объекта систематически связано с изменениями топографии мощности в альфа-диапазоне, не зависящей от фазы, в зависимости от условий.Эта процедура анализа была адаптирована из процедуры декодирования представлений рабочей памяти из ЭЭГ кожи головы (Bae and Luck, 2018).
Декодирование выполнялось независимо в каждый момент времени в эпохах. Мы реализовали нашу модель декодирования с помощью функции Matlab fitecoc (x) , чтобы использовать комбинацию SVM и алгоритмов выходного кодирования с исправлением ошибок (ECOC). Отдельный бинарный классификатор был обучен для каждого условия сигнала с использованием подхода «один против одного», при этом производительность классификатора была объединена в соответствии с подходом ECOC.Таким образом, декодирование считалось правильным, когда классификатор правильно определил условие реплики из трех возможных условий реплики, а вероятность выполнения была установлена на уровне 33,33% (одна треть).
Декодирование для каждой временной точки следовало шестикратной процедуре перекрестной проверки. Данные пяти шестых испытаний, выбранных случайным образом, были использованы для обучения классификатора правильной маркировке. Оставшаяся шестая часть испытаний использовалась для тестирования классификатора с помощью функции Matlab прогноз (x) .Вся эта процедура обучения и тестирования повторялась 10 раз, при этом новые данные для обучения и тестирования назначались случайным образом на каждой итерации. Для каждого условия реплики, каждого участника и каждой временной точки точность декодирования рассчитывалась путем суммирования количества правильных маркировок в испытаниях и итерациях и деления на общее количество маркировок.
Мы усреднили результаты декодирования для всех 10 итераций, чтобы проверить точность декодирования для всех участников в каждый момент времени в эпоху.В любой момент времени точность декодирования с высокой вероятностью предполагает, что альфа-топография содержит информацию о категории обслуживаемых объектов. Однако сравнения точности декодирования со случайностью самого по себе недостаточно для оценки надежности вывода, сделанного на основе точности декодирования. Несмотря на то, что односторонний тест t на точность декодирования разных субъектов против случайности даст значение t и результат статистической значимости для рассматриваемой временной точки, проведение того же теста в каждой из 375 временных точек, включенных в нашу эпоху. потребует поправки на множественные поправки, которые приведут к чрезмерно консервативным статистическим тестам.Поэтому, после исследования Bae and Luck (2018), мы использовали оценку значимости на основе моделирования методом Монте-Карло, чтобы выявить статистически значимые кластеры точности декодирования.
Статистическим методом Монте-Карло точность декодирования оценивалась по случайно выбранному целому числу (1, 2 или 3), представляющему экспериментальные условия, для каждой временной точки. Тест t точности классификации участников на случайность проводился в каждый момент времени для перемешанных данных.Были идентифицированы кластеры последовательных моментов времени с точностью декодирования, определенные как статистически значимые с помощью теста t , и масса кластера t была рассчитана для каждого кластера путем суммирования значений t , заданных каждым составляющим тестом t . Каждый кластер сэкономил т массы . Эта процедура была повторена 1000 раз, чтобы сгенерировать распределение масс t , чтобы представить нулевую гипотезу о том, что данный кластер масс t из нашего анализа декодирования, вероятно, был найден случайно.95% пороговое значение массы t было определено из нулевого распределения на основе перестановок и использовано в качестве порогового значения, с которым можно сравнивать массы кластера t , вычисленные на основе наших исходных данных декодирования. Кластеры последовательных моментов времени в исходных результатах декодирования с массами ± , превышающими порог, основанный на перестановках, считались статистически значимыми.
Мы выполнили ту же процедуру декодирования фазонезависимой колебательной активности ЭЭГ в тета-диапазоне (4–7 Гц), бета-диапазоне (16–31 Гц) и гамма-диапазоне (32–40 Гц), чтобы проверить гипотезу, что объект Модуляции активности ЭЭГ, основанные на внимании, специфичны для альфа-диапазона.Для фильтрации данных ЭЭГ в бета- и гамма-диапазоне мы установили минимальный порядок фильтрации, равный трехкратному количеству отсчетов в экспериментальную эпоху. Для фильтрации по тета-диапазону мы установили минимальный порядок фильтрации, равный двукратному количеству отсчетов, потому что длительность эпохи не была достаточно большой, чтобы позволить порядок фильтрации в три раза больше количества отсчетов.
Процедура.
Участники были проинструктированы сохранять фиксацию в центре экрана во время каждого испытания и предвосхищать категорию объекта, на которую указывает указатель, до тех пор, пока не появится целевое изображение.Им также было поручено указать подкатегорию объекта целевого изображения (например, мужчина / женщина) нажатием кнопки как можно быстрее и точнее в целевой презентации, используя кнопку указательного пальца для мужчин (лицо), природы (сцена) и питания. (инструмент) и нажмите кнопку среднего пальца для женщин (лицо), городских (сцена) и без питания (инструмент). Ответы регистрировались только во время ITI между целевым началом и следующим испытанием. Испытания были классифицированы как правильные, когда записанный ответ соответствовал подкатегории целевого изображения, и неправильный, когда ответ не совпадал или когда не было записанного ответа.Каждый блок экспериментов включал 42 испытания продолжительностью ~ 3 мин. Каждый участник выполнил 10 блоков эксперимента.
Эксперимент 2
Протоколы записи и анализа были идентичны протоколам эксперимента 1. Учитывая, что цель этого эксперимента состояла в том, чтобы проверить, могла ли точность декодирования в подготовительном периоде между началом сигнала и целевым началом быть основана на различиях Что касается сенсорных процессов, вызываемых в зрительной системе различными репликами, мы модифицировали эксперимент 1, сделав реплики непредсказуемыми для предстоящей целевой категории.В соответствии с этой модификацией мы проинструктировали участников, что форма реплики неинформативна, и что представление реплики было просто для предупреждения их о том, что целевой стимул скоро появится. Участников не проинструктировали игнорировать форму реплики. Хотя временной ход различий в сенсорных ответах в ЭЭГ кожи головы, отфильтрованных до частот альфа-диапазона, трудно измерить, на основе предыдущей литературы (Bae and Luck, 2018) мы предсказали, что даже для альфа любой дифференцируемый вызванный стимулом сенсорная активность будет ограничена временным окном в пределах 200 мс после начала сигнала.Каждый участник выполнил 10 блоков эксперимента, в каждом блоке по 42 попытки.
Эксперимент 3
Протоколы записи и анализа были идентичны протоколам эксперимента 1. Целью этого эксперимента было выяснить, могли ли различия в альфа-топографии между условиями внимания объекта в эксперименте 1 быть результатом различных наборов задач в разных группах. три состояния объектного внимания, а не отражающие объектно-ориентированные механизмы внимания в зрительной коре.В частности, в условиях присутствия лица в эксперименте 1 участники были проинструктированы различать, было ли представленное лицо мужским или женским, и указывать свой выбор, используя поле кнопок с двумя кнопками под указательным и средним пальцами. В условиях присутствия на сцене задача заключалась в том, чтобы отличить городские сцены от естественных с помощью тех же двух кнопок, а в условиях использования инструментов присутствия задача заключалась в том, чтобы отличить включенные от неактивных инструментов с помощью тех же двух кнопок. Поскольку различаемые категории были разными в разных условиях (мужской / женский, городской / естественный, электроинструмент / ручной инструмент), возможно, что участники готовили разные наборы задач в разных условиях реплики в течение подготовительного периода.Например, после представления треугольной реплики участнику потребуется когнитивно сопоставить реакцию своего указательного пальца на идентификацию мужского лица и реакцию своего среднего пальца на идентификацию женского лица, тогда как это сопоставление будет другим, если Участнику был вручен квадратный кий. Эти различные наборы задач и сопоставления от зрительной коры головного мозга к подготовке двигательной реакции могли, возможно, управлять различными альфа-топографиями кожи головы в течение подготовительного периода.
Это объяснение не является взаимоисключающим с нашей интерпретацией, согласно которой альфа-топография скальпа отражает различное предварительное смещение внимания в визуальных областях, отобранных по категориям объектов, но, учитывая план эксперимента 1, нет способа узнать, одно, другое или оба отражены в различных альфа-паттернах. Поэтому мы провели эксперимент, который приравнял задачу ко всем условиям внимания к объекту, чтобы устранить любые различия в наборе задач, которые присутствовали в исходном эксперименте.Основываясь на нашей модели, согласно которой альфа — это механизм избирательного внимания к объектам в зрительной коре, в этом новом дизайне мы все еще должны наблюдать различные паттерны альфа-сигналов для подготовительного внимания к категориям объектов, которые должны быть выявлены при успешном декодировании на поздних стадиях сигнала. к целевому периоду.
Аппараты и раздражители.
Общая структура парадигмы для эксперимента 3 следовала парадигме эксперимента 1. В каждом испытании появлялась форма реплики, указывающая категорию объекта, который необходимо посетить.Формы реплик были идентичны таковым в эксперименте 1. Как и раньше, за репликой следовал подготовительный период, а затем появлялось изображение стимула. ITI разделяет изображение стимула и начало следующего испытания. Во время этого ITI были собраны поведенческие ответы. Диапазоны SOA и ITI оставались такими же, как в эксперименте 1.
Поведенческая задача для этого эксперимента заключалась в том, чтобы определить при каждом испытании, соответствует ли кратко представленное целевое изображение, принадлежащее к категории объектов, по которым осуществляется указание (лица, сцены или инструменты). в фокусе или размыто.В отличие от экспериментов 1 и 2, стимулы, подлежащие различению, представляли собой композицию изображения, принадлежащего целевой категории, наложенного на изображение, принадлежащее к категории отвлекающих факторов. Важно отметить, что и целевое изображение, и изображение-отвлекающий элемент в смеси могут быть в фокусе или размытыми независимо друг от друга; следовательно, задача не могла быть выполнена исключительно на основе внимания и реакции на присутствие или отсутствие размытия (см., например, результаты эксперимента 3).
Двадцать процентов испытаний были неправильно запрошены, что позволяет нам оценить влияние достоверности реплики на поведенческие характеристики.Для недействительных испытаний изображение стимула было составным из изображения из случайно выбранной категории объектов без привязки, наложенного на черно-белую шахматную доску. Шахматная доска также может быть размытой или в фокусе независимо от изображения объекта. Участников проинструктировали, что всякий раз, когда они сталкивались с испытанием, в котором смешанный стимул не включал изображение, принадлежащее к категории объекта с указанием, а вместо этого содержал только одно изображение объекта и наложение шахматной доски, они должны были указать, является ли изображение объекта без привязки в стимуле был расплывчатым или в фокусе.Мы предсказали, что участники будут медленнее реагировать на испытания с неверными указаниями, аналогично поведенческому эффекту валидности, наблюдаемому в парадигмах пространственного внимания с указанием указаний.
Изображения стимула охватывали квадрат 5 ° × 5 ° угла обзора. Для создания размытых изображений к изображениям применялось размытие по Гауссу со значением SD 2.
Все три категории объектов включали 40 различных отдельных изображений. В каждом испытании были нарисованы случайные изображения для создания составного изображения стимула. Изображения сцен и инструментов были взяты из тех же наборов изображений, что и для исходного эксперимента.Однако изображения лиц были взяты из другого набора изображений (Ma et al., 2015), потому что изображения лиц, использованные в исходном эксперименте, не имели достаточно высокого разрешения, чтобы обеспечить надежно заметные различия в размытых и не размытых условиях. Все изображения лиц были обрезаны до овалов с центром на лице и помещены на белом фоне.
В отличие от изображений сцены, которые содержали визуальные детали, охватывающие весь квадрат 5 ° × 5 °, изображения лиц и инструментов были установлены на белом фоне и поэтому не содержали визуальной информации до всех границ изображения.Следовательно, чтобы исключить возможность того, что участники могут использовать информацию о сигнале для фокусировки пространственного внимания вместо объектно-ориентированного внимания для выполнения размытого / сфокусированного различения в любом испытании, где изображение лица или инструмента было включено в составной стимул, положение этого изображение лица или инструмента было случайным образом смещено из центра.
Процедура.
Участников проинструктировали как можно быстрее реагировать на целевой стимул, поэтому крайне важно, чтобы участники в течение подготовительного периода привлекали подготовительное внимание к категории объектов с указанием.Все участники были обучены как минимум 126 попыткам выполнения задания и смогли достичь не менее 60% точности ответа перед выполнением его в рамках сбора данных ЭЭГ; для этого продолжительность стимула была скорректирована для каждого участника на начальном этапе обучения. Эксперимент 3 был проведен в той же лабораторной среде, что и исходный эксперимент, и переменные настройки окружающей среды были приравнены к параметрам исходного эксперимента.
Каждый участник выполнил 15 блоков эксперимента, каждый из которых включал 42 испытания, что в среднем представляло на 210 испытаний на одного испытуемого больше, чем эксперимент 1.
Результаты
Эксперимент 1
Поведенческие результаты
Наблюдаемая точность ответа была высокой и одинаковой для всех условий объекта и условий достоверности (недопустимое лицо 96,6%; недопустимая сцена 97,1%; допустимое лицо 96,8%; допустимая сцена 96,7 %; действительный инструмент, 93,1%), за исключением недопустимого условия обслуживания инструмента (87,5%), которое мы рассмотрим ниже.
Чтобы определить, вызвала ли наша задача поведенческий эффект внимания, мы сравнили RT для определения целевых различий между испытаниями с действительной и недействительной подсказкой.Мы наблюдали более быстрые средние RT для действительных испытаний, чем для недействительных испытаний, усредняясь по условиям (рис. 2 A ) и для каждого условия отдельно (рис. 2 B ).
Рисунок 2.Поведенческие меры внимания в эксперименте 1. A , Ящичковые диаграммы данных о времени реакции для недействительных и достоверных испытаний для 20 субъектов, усредненных по состояниям внимания (объекта). Толстые горизонтальные линии внутри прямоугольников представляют собой медианные значения. Первый и третий квартили показаны как нижний и верхний края прямоугольника.Вертикальные линии проходят до самых крайних точек данных, за исключением выбросов. Точки над графиками представляют выбросы, которые были определены как любое значение, превышающее третий квартиль плюс 1,5 межквартильного размаха. Субъекты в целом были значительно быстрее для объектов с указанием (действительных), чем с объектами с указанием (недопустимыми). B , Время реакции для действительных и недействительных испытаний отдельно для каждого состояния внимания. Субъекты были значительно быстрее для объектов с указанием (действительных), чем с объектами с указанием (недопустимые) для каждой категории объектов.
Чтобы количественно оценить влияние достоверности реплики на RT, мы подобрали обобщенную линейную смешанную модель с гамма-распределением к данным RT (Lo and Andrews, 2015). Мы обнаружили значительный эффект валидности (действительный или недействительный, p <0,001). Модель также выявила значительный главный эффект категории объекта ( p <0,001) из-за более медленного общего времени реакции в категории инструмента. Таким образом, испытуемые были менее точны и медленнее реагировали на категорию инструментов.Несмотря на эти незначительные снижения производительности для категории инструментов, тем не менее наблюдался значительный поведенческий эффект внимания для категории инструментов, что свидетельствует о том, что испытуемые использовали все три типа сигналов, чтобы подготовиться к различению и реагированию на приближающиеся объекты.
Результаты альфа-топографии
Чтобы качественно оценить, была ли картина альфа-мощности на электродах разной для упреждающего внимания к трем категориям объектов, мы проверили топографические графики альфа-мощности для каждого состояния объекта в разные периоды времени после сигналов, но до появления целевых раздражителей.Чтобы выделить различия между альфа-топографиями между состояниями и контролировать неспецифические эффекты поведенческого возбуждения, мы создали попарные карты различий альфа-топографии одного состояния внимания объекта, вычтенного из другого состояния внимания объекта.
Мы наблюдали, что различия в альфа-топографии между условиями объекта возникали и развивались в течение периода ожидания (от сигнала к цели) (рис. 3). В топографиях посещаемость минус посещаемость (рис.3 A ), мы наблюдали повышенную альфа-мощность над левой задней частью скальпа и уменьшенную альфа-мощность над правой задней частью скальпа в течение периода упреждения, при этом латерализация становилась наиболее заметной при более длительных послеоперационных латентных периодах. В топографиях «лицо минус инструмент» (рис. 3 B ) картина была аналогичной в самые длинные латентные периоды, но была более изменчивой в промежуточные периоды времени. В топографиях посещаемости минус посещаемость (рис. 3 C ), паттерн альфа-различий отличался от тех, которые связаны с условиями присутствия; при самых длительных послеоперационных латентных периодах картина силы альфа-излучения на коже черепа была обратной, чем на других картах разницы, причем сила альфа-излучения была выше слева, чем на правой задней части скальпа.В целом, наличие этих различий между состояниями согласуется с вариациями основных паттернов корковой альфа-мощности во время упреждающего внимания к лицам, сценам и инструментам. Однако, учитывая вариабельность между субъектами и присущую им сложность в количественной оценке карт различий между субъектами в зависимости от условий внимания, мы обратились к методу декодирования ЭЭГ, чтобы количественно оценить различия в мощности альфа в условиях, которые качественно описаны выше.
Рис. 3.Карты топографических различий для мощности альфа в эксперименте 1. A , Карты различий для упреждающего внимания к лицам минус сцены. График разности альфа-топографии для условий присутствия минус состояние сцены, усредненного по участникам, для четырех временных окон относительно начала сигнала. Карты топографических различий отображаются только до 1000 мс после начала сигнала, когда могут появиться цели с наименьшей задержкой. Вид на эти разностные карты из-за головы.См. Описание в тексте. B , Карты различий для упреждающего внимания к лицам без инструментов. График разности альфа-топографии для условий посещаемости минус условия посещаемости, усредненные по участникам. C , Карты различий для упреждающего внимания к инструментам без сцен. График разницы в альфа-топографии для инструмента посещаемости минус условия посещения, усредненные по участникам.
Результаты декодирования SVM
Результаты декодирования SVM (рис.4) выявил статистически значимые точности декодирования в двух кластерах временных точек в диапазоне 500–800 мс после спасения и перед целью (рис. 4, бирюзовые точки). Точность декодирования в диапазоне от -100 до +200 мс в начале сигнала не достигла порога статистической значимости.
Рисунок 4.Точность декодирования альфа-диапазона в эксперименте 1. Точность декодирования активности альфа-диапазона в течение эпохи для разных участников. Горизонтальная красная линия представляет собой случайную точность декодирования.Сплошная изменяющаяся во времени линия представляет собой среднюю точность декодирования по каждому объекту в каждый момент времени, а заштрихованная область вокруг этой линии — это SEM. Серая заливка обозначает период предварительного ожидания, а сегмент с оранжевой заливкой представляет период ожидания между началом сигнала (0 мс) и самым ранним наступлением цели (1000 мс). Бирюзовые точки обозначают моменты времени, которые принадлежат статистически значимым кластерам точности декодирования, как определено оценкой Монте-Карло.
Результаты декодирования SVM осцилляторной активности ЭЭГ в тета-, бета- и гамма-диапазонах не выявили статистически значимого декодирования в период упреждения (рис.5).
Рисунок 5.Декодирование для разных частотных диапазонов ЭЭГ в эксперименте 1. A , Та же процедура декодирования SVM и статистическая процедура Монте-Карло, которые использовались для анализа данных альфа-диапазона, были применены к тета-диапазону (4– 7 Гц). B , Тот же конвейер декодирования был применен к бета-диапазону (16–31 Гц), что не выявило статистически значимых кластеров с высокой точностью декодирования в подготовительный период. C , Тот же конвейер декодирования также применялся к гамма-диапазону (32–40 Гц) и, аналогичным образом, не выявил статистически значимых кластеров с высокой точностью декодирования в подготовительный период.
Эксперимент 2
Мы наблюдали статистически значимый кластер моментов времени с высокой точностью декодирования с высокой вероятностью только в окне представления сигнала. Никаких дальнейших кластеров декодирования со значительно большей вероятностью не происходило где-либо в интервале от 200 до 1000 мс (рис. 6).
Рисунок 6.Точность декодирования альфа-диапазона для эксперимента 2. Та же процедура декодирования SVM и статистическая процедура Монте-Карло, которые использовались для анализа данных из эксперимента 1, были применены к альфа-диапазону ЭЭГ из эксперимента 2, выявив кластер статистически важные моменты времени, близкие к началу сигнала, но не позднее подготовительного периода.
Результаты этого контрольного эксперимента опровергают возможность того, что декодирование позднего периода альфа-диапазона, которое мы наблюдали в нашем первоначальном эксперименте, было просто результатом дифференциальных восходящих сенсорных процессов в трех условиях сигнала. Поскольку парадигма эксперимента 2 была идентична парадигме эксперимента 1 во всех отношениях, кроме достоверности реплики, и поскольку мы использовали тот же конвейер декодирования SVM для данных ЭЭГ в альфа-диапазоне из эксперимента 2, как и в эксперименте 1, мы могли напрямую оценить, была ли модель результатов декодирования, полученных нами в первоначальном эксперименте, связана с восходящими сенсорными процессами.
Мы собрали данные от большего числа участников для эксперимента 2, чем для нашего первоначального эксперимента, чтобы у нас было больше возможностей для оценки величины и временной степени декодирования, которое могло быть достигнуто исключительно на основе вызванной стимулом активности. Наши результаты подтверждают идею о том, что сверх-случайное декодирование с большой задержкой в эксперименте 1 не связано с чисто сенсорной активностью, обусловленной различиями физических стимулов, потому что мы обнаружили, что в эксперименте 2 статистически значимое сверх-случайное декодирование происходило только в кластере времени. указывает на короткую задержку после спасения (<200 мс после начала сигнала; рис.6).
Эксперимент 3
Поведенческие результаты
В задаче различения нечеткости от сфокусированных изображений (рис.7) мы наблюдали различия в RT между действительными и недействительными испытаниями для всех категорий объектов, так что испытания с достоверными указаниями вызывали более быстрые ответы, чем неправильно назначенные испытания (рис. 8). При подгонке обобщенной линейной смешанной модели с гамма-распределением к данным RT мы обнаружили значительный эффект достоверности ( p <0,001).
Рис. 7.Пример изображения цели в задаче на внимание для эксперимента 3.В этом наборе примеров лицо — это категория целевого объекта, которую нужно идентифицировать как находящуюся в фокусе или размытую, а наложенные изображения инструмента или сцены являются изображениями-отвлекающими элементами. Для каждого стимульного изображения и цель, и отвлекающий фактор могут быть размытыми или в фокусе независимо друг от друга.
Рисунок 8.Поведенческие меры внимания в эксперименте 3. A , Ящичковые диаграммы данных о времени реакции для недействительных и достоверных испытаний для 12 субъектов, усредненных по состояниям внимания (объекта).Толстые горизонтальные линии внутри прямоугольников представляют собой медианные значения. Первый и третий квартили показаны как нижний и верхний края прямоугольника. Вертикальные линии проходят до самых крайних точек данных, за исключением выбросов. Точки над графиками представляют выбросы, определяемые как любое значение, превышающее третий квартиль плюс 1,5 межквартильного размаха. Субъекты в целом были значительно быстрее для объектов с указанием (действительных), чем с объектами с указанием (недопустимыми). B , Время реакции для действительных и недействительных испытаний отдельно для каждого состояния внимания.Субъекты были значительно быстрее для объектов с указанием (действительных), чем с объектами с указанием (недопустимые) для каждой категории объектов.
Результаты декодирования SVM
Используя тот же анализ ЭЭГ и конвейер декодирования SVM, что и для эксперимента 1, мы обнаружили статистически значимые кластеры временных точек, демонстрирующих точность декодирования выше шансов (рис. 9). Как и в эксперименте 1, эти статистически значимые кластеры наблюдались во второй половине подготовительного периода,> 500 мс после начала сигнала.Примечательно, что в окне представления сигнала 0–200 мс, по-видимому, также имеется группа моментов времени с высокой вероятностью, в тот же период, когда мы наблюдали статистически значимое декодирование в эксперименте 2, которое было связано с сенсорной активностью, вызванной сигналом. Однако в результатах эксперимента 3, как и в эксперименте 1, декодирование в этот период времени предъявления сигнала (задержка <200 мс) не достигло уровня статистической значимости (тогда как при большем количестве участников в эксперименте 2 это могло быть выявлено. ).
Рисунок 9.Точность декодирования альфа-диапазона для эксперимента 3. Та же процедура декодирования SVM и статистическая процедура Монте-Карло, которые использовались для анализа данных из эксперимента 1, были применены к альфа-диапазону ЭЭГ из эксперимента 3, выявив кластер статистически знаменательные моменты времени во второй половине подготовительного периода.
Поведенческие результаты эксперимента 3 предполагают, что участники привлекали объектное внимание в течение подготовительного периода. Участники быстрее распознавали изображения объектов как размытые или сфокусированные, когда их категория была указана.По аналогии с парадигмами пространственного внимания с указаниями, в испытаниях с неверно указанными объектами участники обращались к одной категории объектов в течение подготовительного периода, но затем при предъявлении стимула переориентировали свое внимание, чтобы иметь возможность различать, было ли изображение из категории объектов без привязки размытым или размытым. фокус.
Поскольку поведенческий эффект между валидными и недействительными испытаниями соответствует таковому в нашем первоначальном эксперименте, мы уверены, что экспериментальный план в эксперименте 3 порождал ту же форму объектно-ориентированного внимания сверху вниз, как это было зафиксировано в эксперименте 1.Следовательно, при наблюдении статистически значимого сверхшансного декодирования в том же общем окне времени после появления сигнала для экспериментов 1 и 3 мы интерпретируем этот результат как доказательство того, что внимание, основанное на объекте, а не различия в постановке задачи или подготовке двигательной реакции, является движущей силой. результат декодирования с большей задержкой до наступления целей.
Обсуждение
Объектное внимание — фундаментальный компонент естественного зрения. Люди перемещаются по миру в основном на основе взаимодействий с объектами, которые изобилуют в типичных средах (O’Craven et al., 1999; Scholl, 2001). Примат объектов означает, что адаптивное взаимодействие с миром требует представлений объектов высокого уровня, которые отличаются от визуальных характеристик низкого уровня в той же области пространства. Следовательно, воздействие внимания непосредственно на репрезентации объектов является критическим аспектом восприятия (Woodman et al., 2009). Было показано, что внимание действует на репрезентации объектов (Типпер и Берманн, 1996; Берманн и др., 1998), поэтому выявление нейронных механизмов, с помощью которых внимание влияет на репрезентации объектов, является ключевой задачей когнитивной нейробиологии.
Физиологические исследования показывают, что повышение эффективности внимания коррелирует с изменениями нейронной активности в системах восприятия. Корковые структуры, кодирующие сопровождаемую информацию, показывают повышенную амплитуду сигнала, синхронность и / или функциональную связность (Moore and Zirnsak, 2017). Как нервная система механистически контролирует эту корковую возбудимость и эффективность обработки, остается не совсем понятным, но большинство моделей предполагают, что нисходящие управляющие сигналы от сетей более высокого порядка в лобной и теменной коре изменяют обработку в сенсорных / перцептивных областях коры, кодирующих посещаемую и необслуживаемую информацию ( Петерсен и Познер, 2012).Одной из гипотез нейронной сигнатуры нисходящего контроля на уровне сенсорной / перцептивной коры является фокусная альфа-сила (Jensen and Mazaheri, 2010). Изменения в мощности альфа происходят во время пространственного внимания (Worden et al., 2000) и особого внимания (Snyder and Foxe, 2010). Здесь мы исследовали механизмы на основе альфа-канала, опосредующие избирательное внимание к объектам, привлекая внимание к различным объектам и измеряя изменения в записанной на коже головы альфа-мощности ЭЭГ. Мы объединили поведение с топографическим картированием и декодированием ЭЭГ, чтобы проверить гипотезу о том, что внимание к объекту включает селективные модуляции мощности альфа-излучения в объектно-специфической коре головного мозга.
Мы выбрали лица, сцены и инструменты в качестве целей внимания, потому что было показано, что эти объекты активируют ограниченные области в зрительной коре. Веретенообразная область лица (FFA) избирательно реагирует на изображения вертикальных лиц (Allison et al., 1994; Kanwisher and Yovel, 2006): лица могут считаться объектами, потому что, например, данные пациентов с прозопагнозией предполагают, что аналогичные механизмы лежат в основе распознавания лиц и объектов (Gauthier et al., 1999).Площадь парагиппокампа (PPA) реагирует на сцены (Epstein et al., 1999) и, в частности, на категорию сцены (Henriksson et al., 2019). Области, чувствительные к инструментам, были идентифицированы в вентральном и дорсальном зрительных путях (Kersey et al., 2016). В соответствии с предсказанием, что объектно-ориентированное внимание модулирует альфа-канал в визуальных областях, специализированных для обработки категории обслуживаемых объектов, внимание к лицам должно выборочно снижать активность альфа-диапазона в визуальных областях, избирательных по лицам, таких как FFA, внимание к сценам должно уменьшать альфа-диапазон активность в областях, отобранных для выбора места, таких как PPA, и внимание к инструментам должно снизить активность альфа-диапазона по сравнению с областями, отобранными для выбора инструментов, вентральных и дорсальных путей зрения.ЭЭГ не является сильным методом локализации нейронных источников мозговой активности, но, учитывая, что области FFA, PPA и постулируемые специализированные области инструментов расположены в разных областях коры головного мозга, закономерности альфа-модуляции с вниманием в этих областях можно было бы ожидать. для получения дифференциальных альфа-паттернов ЭЭГ на коже головы. Учитывая, что можно ожидать, что такие паттерны будут лишь незначительно отличаться и трудно предсказать, одним из способов оценки различных паттернов альфа для внимания к разным объектам является включение машинного обучения для декодирования альфа-паттернов ЭЭГ кожи головы.Таких различий следует ожидать только в том случае, если фокусная модуляция альфа также участвует в избирательном внимании объекта.
Наши результаты по времени реакции показали, что участники, которые обращали внимание на объектно-ориентированное внимание на категории объектов, на которые указывает указание, быстрее идентифицировали объекты с указанием. Теоретически, когда участники получают команду предвидеть определенную категорию объектов, они будут искажать нейронную активность в областях коры, специализированных для этого типа объекта, и, возможно, также искажать активность в областях коры, обрабатывающих все визуальные особенности нижнего уровня, связанные с этим объектом (Коэн и Тонг, 2015).Когда цель появляется, ее визуальные свойства интегрируются, облегчая требуемое восприятие различения. Когда появляется объект из непредвиденной (необработанной) категории, активность в областях, отобранных для объекта, и связанных областях визуальных характеристик для объектов без привязки будет относительно подавлена, что задерживает интеграцию и семантический анализ несвязанных целевых изображений и замедляет время реакции.
Топографические карты альфа-различий менялись в зависимости от категории объекта, на котором присутствовали участники.Различная альфа-топография соответствовала паттернам ЭЭГ кожи головы, которые можно было бы ожидать, если бы альфа-модуляции происходили в разных основных корковых генераторах (корковых пятнах или областях) для трех категорий объектов. Множество доказательств лежащих в основе нейроанатомических субстратов лица, сцены и обработки инструментов из исследований изображений позволяет делать некоторые прогнозы относительно наших данных в отношении предполагаемой природы фокальной корковой активности, вносящей вклад в наши топографические и декодирующие результаты.FFA с акцентом на правое полушарие (Kanwisher et al., 1997) и одинаково двусторонне распределенный PPA (Epstein and Kanwisher, 1998), в принципе, предсказывают дифференциальное альфа-распределение скальпа и, возможно, более низкую альфа-мощность в целом по правой затылочной кости при посещении лиц. Наша альфа-топография посещаемости минус посещаемость сцены в целом соответствовала этому прогнозу (рис.3 A ), и эта модель отличалась от графика на графике разницы посещаемости минус посещаемости и инструментов (рис.3 В ). Однако мы надеемся прояснить, что мы не предполагаем, что мы можем локализовать лежащие в основе корковые генераторы регистрируемой активности кожи головы, используя методы, которые мы использовали здесь; поэтому мы обратились к декодированию.
Наш анализ декодирования убедительно подтверждает утверждение о том, что внимание модулирует альфа-топографии в зависимости от категории объекта и согласуется с временными курсами различий в альфа-образцах, наблюдаемых на графиках топографических различий скальпа.В нашем анализе декодирования статистически значимая точность декодирования с высокой вероятностью обеспечивает прямое свидетельство того, что альфа-топография содержит информацию о выбранной категории объекта, и, следовательно, что внимание, основанное на нисходящем объекте, модулирует альфа-топографию в соответствии с категорией объекта с указанием (сопровождаемым) . Мы наблюдали, что статистически значимое декодирование происходило в диапазоне 500-800 мс после спасения / предварительной цели, что указывает на то, что паттерны альфа-топографии на коже черепа надежно модулировались нашим манипулированием вниманием в этом временном диапазоне (рис.4). Важно отметить, что диапазон 500–800 мс соответствует периодам на графиках альфа-топографических разностей, где изображения стабилизировались.
Чтобы проверить, были ли наши результаты декодирования специфичными для альфа-диапазона, мы выполнили ту же процедуру декодирования SVM для мощности в тета-, бета- и гамма-диапазонах и не обнаружили значительного превосходного декодирования в период ожидания для этих полосы частот (рис. 5). Этот результат согласуется с гипотезой о том, что осцилляторная нейронная активность в альфа-диапазоне механически участвует в упреждающем внимании, тогда как активность в других частотных диапазонах ЭЭГ не модулируется в соответствующих целевых визуальных областях ЭЭГ человека.
В двух последующих экспериментах мы непосредственно оценили две альтернативные интерпретации наших результатов декодирования из эксперимента 1. Во-первых, различия в альфа-топографии скальпа после спасения могут отражать чисто сенсорную обработку, связанную с каждым сигналом (например, треугольник против круга). Это должно быть применимо только к декодированию с повышенной вероятностью (хотя и не значимым в наших тестах), наблюдаемому в ранний период после спасения (∼0–200 мс) на рисунке 4, а не к декодированию с более длительной задержкой.Действительно, мы проверили это в эксперименте 2, в котором участники выполняли ту же задачу и видели те же сигналы и цели, что и в эксперименте 1, но форма сигнала не предсказывала предстоящую категорию объекта. Мы наблюдали статистически значимое декодирование в период после спасения / перед целью от 0 до 200 мс, связанное с физическими функциями реплики (Bae and Luck, 2018), но не наблюдали значимого декодирования позже в интервале от реплики к цели.
Второе альтернативное объяснение наших результатов декодирования из эксперимента 1 состоит в том, что они были вызваны различиями в наборах задач в зависимости от условий объекта.Задача для лиц, например, заключалась в различении пола, в то время как для сцен — различать городские сцены и природные сцены, оставляя открытой возможность того, что наше декодирование в конце периода после спасения отражало различия в поставленных задачах (Hubbard et al., 2019 ), а не контроль внимания над выбором объекта, как мы предлагаем. Мы можем отклонить эту альтернативу на основе результатов эксперимента 3, в котором реплики предсказывали соответствующий целевой объект, но задача распознавания была одинаковой для всех категорий объектов: различать, был ли объект, на который подведена подсказка, был в фокусе или размыт.Таким образом, мы смогли воспроизвести подготовительные эффекты внимания, связанные с альфа-альфа с большей задержкой, о которых сообщалось в эксперименте 1, при одновременном контроле факторов набора задач.
Наши результаты показывают, что альфа-модуляция ЭЭГ связана с избирательным вниманием на основе объектов, расширяя предыдущие выводы о том, что альфа-модуляция связана с вниманием к пространственным местоположениям и визуальным особенностям низкого уровня. Используя подход к декодированию SVM, мы выявили различия в топографических паттернах мощности альфа-канала во время выборочного внимания к разным категориям объектов.Кроме того, мы связали временной диапазон, в течение которого было достигнуто статистически значимое декодирование, с топографическими картами с усилением альфа-канала и наблюдали, что альфа-модуляция согласуется с временным ходом подготовительного внимания, наблюдаемым в предыдущих исследованиях. В целом, эти результаты подтверждают модель, согласно которой нейронная активность в альфа-диапазоне функционирует как модулятор внимания сенсорной обработки как для зрительных функций низкого уровня, так и для нейронных репрезентаций высокого порядка, таких как репрезентации объектов.
Сноски
Эта работа была поддержана грантом Mh217991 на имя G.R.M. и M.D. S.N. поддерживался T32EY015387. Мы благодарим Майкла Дж. Тарра, Центр нейронных основ познания и Департамент психологии Университета Карнеги-Меллона (http://www.tarrlab.org/) за изображения стимулов для лица при финансовой поддержке премии Национального научного фонда 0339122. Мы также благодарим Стивена Дж. Лака и Ги-Йеул Бэ за советы по анализу с использованием методов декодирования, а также Атиша Кумара и Тамима Хассана за помощь в сборе данных.
Авторы заявляют об отсутствии конкурирующих финансовых интересов.
- Корреспонденция должна быть адресована Джорджу Р. Мангуну на grmangun {at} ucdavis.edu
Страница не найдена
К сожалению, страница, которую вы искали на веб-сайте AAAI, не находится по URL-адресу, который вы щелкнули или ввели:
https://www.aaai.org/papers/aaai/2008/aaai08-193.pdf Если указанный выше URL заканчивается на «.html», попробуйте заменить «.html:» на «.php» и посмотрите, решит ли это проблему.
Если вы ищете конкретную тему, попробуйте следующие ссылки или введите тему в поле поиска на этой странице:
- Выберите Темы AI, чтобы узнать больше об искусственном интеллекте.
- Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство».
- Выберите «Публикации», чтобы узнать больше о AAAI Press и журналах AAAI.
- Для рефератов (а иногда и полного текста) технических документов по ИИ выберите Библиотека
- Выберите AI Magazine, чтобы узнать больше о флагманском издании AAAI.
- Чтобы узнать больше о конференциях и встречах AAAI, выберите Conferences
- Для ссылок на симпозиумы AAAI выберите «Симпозиумы».
- Для получения информации об организации AAAI, включая ее должностных лиц и персонал, выберите «Организация».
Помогите исправить страницу, которая вызывает проблему
Интернет-страница
, который направил вас сюда, должен быть обновлен, чтобы он больше не указывал на эту страницу. Вы поможете нам избавиться от старых ссылок? Напишите веб-мастеру ссылающейся страницы или воспользуйтесь его формой, чтобы сообщить о неработающих ссылках. Это может не помочь вам найти нужную страницу, но, по крайней мере, вы можете избавить других людей от неприятностей. Большинство поисковых систем и каталогов имеют простой способ сообщить о неработающих ссылках.
Если это кажется уместным, мы были бы признательны, если бы вы связались с веб-мастером AAAI, указав, как вы сюда попали (т. Е. URL-адрес страницы, которую вы искали, и URL-адрес ссылки, если таковой имеется). Спасибо!
Содержание сайта
К основным разделам этого сайта (и некоторым популярным страницам) можно перейти по ссылкам на этой странице. Если вы хотите узнать больше об искусственном интеллекте, вам следует посетить страницу AI Topics. Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство».Выберите «Публикации», чтобы узнать больше о AAAI Press, AI Magazine, и журналах AAAI. Чтобы получить доступ к цифровой библиотеке AAAI, содержащей более 10 000 технических статей по ИИ, выберите «Библиотека». Выберите Награды, чтобы узнать больше о программе наград и наград AAAI. Чтобы узнать больше о конференциях и встречах AAAI, выберите «Встречи». Для ссылок на программные документы, президентские обращения и внешние ресурсы ИИ выберите «Ресурсы». Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «О нас» (также «Организация»).Окно поиска, созданное Google, будет возвращать результаты, ограниченные сайтом AAAI.
.